标签:最小 size learn tar structure lan 过程 andrew ng struct
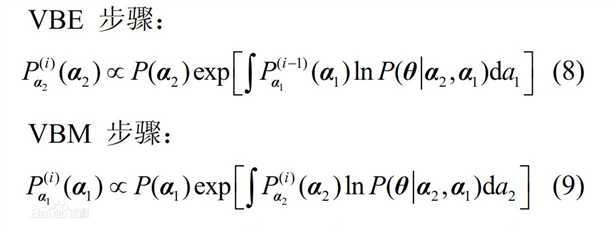
二、采样和变分
1、Gibbs采样和变分
Gibbs采样:使用邻居结点(相同文档的词)的主题采样值
变分:采用相邻结点的期望。n
这使得变分往往比采样算法更高效:用一次期望计算代替了大量的采样。直观上,均值的信息是高密(dense)的,而采样值的信息是稀疏(sparse)的。
2、变分概述
变分既能够推断隐变量,也能推断未知参数,是非常有力的参数学习工具。其难点在于公式演算略复杂,和采样相对:一个容易计算但速度慢,一个不容易计算但运行效率高。
平均场方法的变分推导,对离散和连续的隐变量都适用。在平均场方法的框架下,变分推导一次更新一个分布,其本质为坐标上升。可以使用模式搜索(pattern search)、基于参数的扩展(parameter expansion)等方案加速
有时假定所有变量都独立不符合实际,可使用结构化平均场(structured mean field),将变量分成若干组,每组之间独立
变分除了能够和贝叶斯理论相配合得到VB(变分贝叶斯),还能进一步与EM算法结合,得到VBEM,用于带隐变量和未知参数的推断
标签:最小 size learn tar structure lan 过程 andrew ng struct
原文地址:http://www.cnblogs.com/smuxiaolei/p/7500634.html