标签:指定 erb style 需要 聚合 highlight 二进制 .com 数据集
用ff 包读取一个csv 文件
>options(fftempdir = [二进制文件存放的位置]) >file_chunks <- read.csv.ffdf(file=”big_data.csv”, header=T, sep=”,”, VERBOSE=T, next.rows=500000, colClasses=NA)
ff通过next.row指定的参数一块一块的读取一个大数据量的csv文件,它读取切割块并写入二进制文件,并将文件的指针存储在内存中,然后重复的执行此步骤直到csv文件离开没有块。
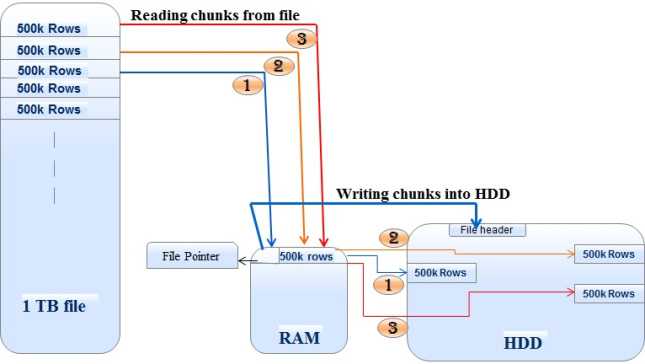
以同样的方式,我们可以在块中编写csv或其他文件。它从本地磁盘一块一块的读取数据或任何其他外部媒体中读取大块块,并将其写入csv或其他支持的格式。
>write.csv.ffdf(File_chunks, “file_name.csv”)
ff 包 给我们提供了 ffbase 的包 以供我们实现一些 排序,关联,聚合,分割和切片的功能
>Merged_data = merge(ffobject1, ffobject2, by.x=c(“Col1”, “Col2”), by.y=c(“Col1″,”Col2”), trace=T)
>library(“doBy”) >AggregatedData = ffdfdply(ffobject, split=as.character(ffobject$Col1), FUN=function(x) summaryBy(Col3+Col4+Col5 ~ Col1, data=x, FUN=sum))
重点说下 ffdfdply函数
在ffdf上执行split-apply-combine。根据split参数拆分传入的数据集并将应用于FUN,将FUN的结果存储在ffdf中。
请注意,此函数实际上并不拆分数据。
为了减少数据在大量分割级别的情况下放入RAM的次数,该功能根据BATCHBYTES提取可以放入RAM的分割块。
请确保您的FUN涵盖了几个拆分元素可以在应用FUN的一个数据块中。
另外,分组中的NA不被视为将应用FUN的分裂。
关于split参数
根据split拆分整体数据集并将FUN应用于数据,将FUN的结果存储在ffdf中。
但是注意此函数实际上并不拆分数据。为了减少数据在大量分割级别的情况下放入RAM的次数,
该功能根据BATCHBYTES(整数标量限制在一个块中要处理的字节数)提取可以放入RAM的分割元素组。
>ffobject$KeyColumn <- ikey(ffobject[c(“Col1″,”Col2″,”Col3”)])
1、巨大的数据集执行复杂的操作时,我们需要以速度来妥协2、使用ff开发并不容易
3、需要关心存储在磁盘中的文件,否则您的HDD或外部介质留有很少或没有空间。
标签:指定 erb style 需要 聚合 highlight 二进制 .com 数据集
原文地址:http://www.cnblogs.com/qiaoyihang/p/7505680.html