标签:本质 目的 越界 style cli png opened using image
给定一个由且仅由字符 ‘H‘ , ‘T‘ 构成的字符串$S$.
给定一个最初为空的字符串$T$ , 每次随机地在$T$的末尾添加 ‘H‘ 或者 ‘T‘ .
问当$S$为$T$的后缀时, 在末尾添加字符的期望次数.
输入只有一行, 一个字符串$S$.
输出只有一行, 一个数表示答案.
为了防止运算越界, 你只用将答案对$10^9+7$取模.
Sample Input |
Sample Output |
HTHT
|
20
|
题目的本质其实就是:从左到右一位一位填字符(0或1,概率都为$0.5$),如果当前字符不满足目标串的相应字符,就要退回到之前的某一位继续匹配,求成功填满整个字符串的期望填充次数。
其中,“退回”的操作,实际上是为了满足题目所说的“后缀”,这点要清楚,失配后不会从头开始,而是从类似KMP的next位置继续匹配。
那么我们对$S$预处理正常KMP的next数组,和一个数组$g[i][j]$ $(j=0,1)$,表示已正确填好前$i$位字符,第$i+1$位字符填了$j$后,匹配的位置。
设第$i+1$位正确的字符为$x$,那么有
$g[i][x]=i+1$
$g[i][x\text^1]=g[next[i]][x\text^1]$
如果当前第$i$位我们填入$y$,那么下一步我们就应该从$g[i-1][y]$处开始匹配。
设$f_i$表示当前前$i$位已正确填充好,成功填入下一位$i+1$的期望填充次数,$wrong$为$i+1$位的错误字符。
转移即为:
$\begin{aligned}
f_i&=0.5*1+0.5*(1+\sum_{j=g[i][wrong]}^{i}f_j)\\
f_i&=0.5*1+0.5*(1+f_i+\sum_{j=g[i][wrong]}^{i-1}f_j)\\
\frac{1}{2}f_i&=0.5*1+0.5*(1+\sum_{j=g[i][wrong]}^{i-1}f_j)\\
f_i&=2+\sum_{j=g[i][wrong]}^{i-1}f_j
\end{aligned}$
第一行什么意思呢?
我们有$0.5$的概率$1$次填上对的字符;
也有$0.5$的概率填充$1$次,结果填错了,蹦回$g[i][wrong]$,再一路走到$i+1$。
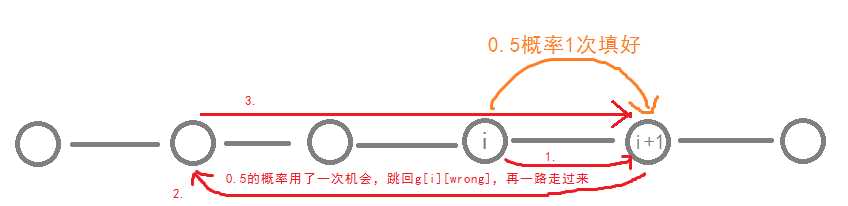
我们边算期望边处理一个前缀和$sum_i=\sum\limits_{j=0}^{i-1}f_j$,这样公式中求和的部分就变成了:
$f_i=2+sum_{i}-sum_{g[i][wrong]}$
答案也就是$sum_{len(S)}$,从$0$一路走到$S$的最后。

1 #include <cstdio> 2 #include <cstring> 3 using namespace std; 4 typedef long long ll; 5 const int N=1000010,Mod=1e9+7; 6 char inp[N]; 7 int n,s[N],g[N][2],nex[N]; 8 ll sum[N]; 9 ll max(ll x,ll y){return x>y?x:y;} 10 void kmp(){ 11 nex[1]=0; 12 for(int i=2,j;i<=n;i++){ 13 j=nex[i-1]; 14 while(j&&s[j+1]!=s[i]) j=nex[j]; 15 if(s[j+1]==s[i]) nex[i]=j+1; 16 else nex[i]=0; 17 } 18 for(int i=0;i<n;i++){ 19 g[i][s[i+1]]=i+1; 20 g[i][s[i+1]^1]=g[nex[i]][s[i+1]^1]; 21 } 22 } 23 int main(){ 24 scanf("%s",inp+1); 25 n=strlen(inp+1); 26 for(int i=1;i<=n;i++) s[i]=inp[i]==‘T‘; 27 kmp(); 28 ll f; 29 sum[1]=2; 30 for(int i=1;i<n;i++){ 31 f=(sum[i]+Mod-sum[g[i][s[i+1]^1]]+2)%Mod; 32 sum[i+1]=(sum[i]+f)%Mod; 33 } 34 printf("%lld\n",sum[n]); 35 return 0; 36 }
标签:本质 目的 越界 style cli png opened using image
原文地址:http://www.cnblogs.com/RogerDTZ/p/7501446.html
