标签:stp 记录 sha bsp 内存区域 do it psi demo for
这几天我再次阅读了《深入理解Java虚拟机》之第二章“Java内存区域与内存溢出异常”,同时也参考了一些网上的资料,现在把自己的一些认识和体会记录一下。
(本文为博主原创文章,转载请注明出处)
一、概述
在网上看到很多的各种文章来写Java内存布局/Java内存模型(JMM)/Java内存分配和回收等。初学者,往往容易被搞混淆,这些东西到底都是些啥?讲的是不是同一个东西?如果不是同一个东西,那它们之间又有什么区别和联系?说句实话,笔者在看到这些文章和概念时,一样是有这些疑问的。下面我来说说我的理解,如果有人觉得有异议或者不对的地方,欢迎讨论和指出,谢谢!
1.1 Java内存布局
我认为这是一个静态的概念, 即JVM在概念和作用上对其管理的内存进行划分。如整体上来看,JVM的内存分为堆区和非堆区,而非堆区又包括了方法区、JVM栈、本地方法栈、程序计数器等。直接上图:
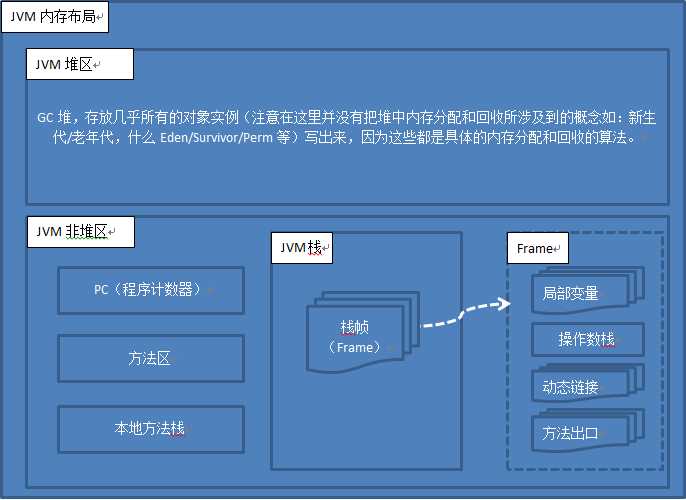
图1.1
1.2 Java内存模型(JMM)
这个讲的是Java多线程的情况下,多线程之间的内存通信模型。即如果多个线程存在共享同一块内存的情况下,JVM通过一个什么样的内存模型来解决多线程对共享内存的读取和写入数据的问题。借用网上的一张图:
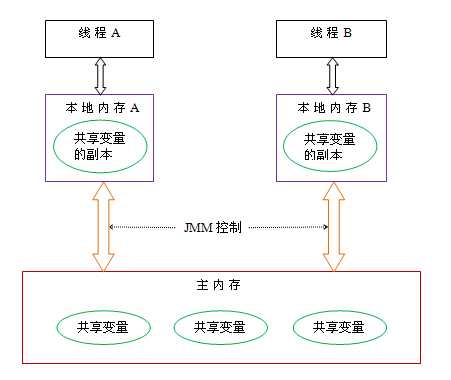
图1.2
从上图中我们可以看到,JMM的核心思想是把堆中的内存分成了两部分:主内存和本地内存,主内存为所有线程共享,而本地内存则由线程独享,同时,对于共享变量,在线程的本地内存中都保存了一个副本共当前线程使用。其他更具体的细节,笔者会在后续的博客中继续跟进和分析。当然,读者也可以自行在网上搜,会有很多的文章讲JMM的。
参考:http://www.infoq.com/cn/articles/java-memory-model-1
1.3 Java内存分配和回收
这是一个侧重JVM对内存的使用和回收方法的概念。即JVM是如何分配内存,如何回收内存?通常Hotspot的JVM的分配和回收算法(分代垃圾回收)中,又体现出了如下的内存布局图,同样先借用网上的一张图:
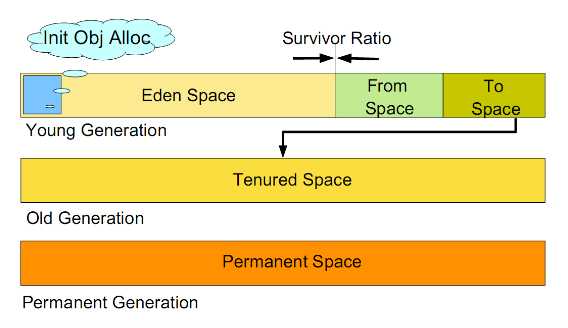
图1.3
在JVM的内存空间中把堆空间分为年老代和年轻代。将大量(据说是90%以上)创建了没多久就会消亡的对象存储在年轻代,而年老代中存放生命周期长久的实例对象。年轻代中又被分为Eden区(圣经中的伊甸园)、和两个Survivor区。新的对象分配是首先放在Eden区,Survivor区作为Eden区和Old区的缓冲,在Survivor区的对象经历若干次收集仍然存活的,就会被转移到年老区。
参考:http://www.cnblogs.com/douba/p/a-simple-example-demo-jvm-allocation-and-gc.html
讲完了这三个概念的比较,接下来进入正题“JVM内存布局”
二、Java虚拟机运行时数据区划分
运行时的数据区域划分,可以参考图1.1,现在就几个数据区域的功能和作用做详细的介绍。
2.1 JVM堆(heap)
其主要作用是用于为几乎所有的对象实例和数组实例的实例化提供内存空间。说通俗点,所有采用new关键字产生的对象的空间都在此分配。如:Map<String,String> map = new HashMap<>(); 这个map所引用的对象即位于JVM的堆中。
JVM heap的特点是:1)内存不一定连续分配,只要逻辑上是连续的即可;
2)内存的大小可以通过JVM的参数来控制:如 -Xms = 1024M -Xmx = 2048M; 表示JVM Heap的初始大小为1GB,最大可自动伸缩到2GB;
3)平时所说的Java内存管理即指的是内存管理器对这部分内存的管理(创建/回收);
4)所有线程共享
而JVM Heap的内存在采用分代垃圾回收算法的Hotspot JVM中,这片区域会被分割成新生代/老年代/永久代,而新生代中又分成了两部分Eden区和Survivor区(分为from space和to space,各自占Survivor区的50%的内存大小)。此部分的详细信息,可以参考图1.3 。然而,在内存分配的时候,JVM通常会从Heap中为每个线程分配一个线程缓冲区(Thread Local Allocation Buffer, TLAB),TLAB为线程私有,因此在为对象分配内存时,首先会先从TLAB中分配内存,这样做可以保证在分配内存的时候不用锁住整个堆区,减少锁开销。
2.2 方法区
主要用于存储已经由JVM加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。在Hotspot JVM中,设计者使用“永久代”来实现方法区,这样带来的好处是,JVM可以不用再特别的写代码来管理方法区的内存,而可以像管理JVM 堆一样来管理。带来的弊端在于,这很容易造成内存溢出的问题。我们知道,JVM的永久代使用 --XX:MAXPermSize来设定永久代的内存上限。
值得一提的是,运行时常量池也属于方法区的一部分,所以,它的大小是受到方法区的限制的。运行期间也可以将新的常量放入池中,运用的比较多的就是String的intern()方法。
2.3 JVM栈(Java虚拟机栈)
JVM栈是伴随着线程的产生而产生的,属于线程私有区域,生命周期和线程保持一致,所以,JVM的内存管理器对这部分内存无需管理;
从图1.1中可以看出,栈中有包含了多个栈帧(frame),frame伴随的方法的调用而产生,方法调用完毕,frame也就出栈,从JVM栈中被移除。frame主要保存方法的局部变量、操作数栈、动态链接、方法出口(reternAddress或者抛Exception)。
虚拟机规范中,对此内存区域规定了两种异常情况:
1)当线程请求的战的深度大于JVM所允许的最大深度,则抛出StackOverflowError;
2)当栈的内存是可动态扩展的时候,如果扩展时发现堆内存不足时,会抛出OutofMemoryError;
2.4 本地方法栈
与JVM栈非常类似,只不过,本地方法栈是为Java的Native method方法调用的时候服务。JVM规范并未定义如何实现该区域,但是,在Hotspot JVM中,本地方法栈和JVM栈合二为一,所以,本地方法栈同样会抛出StackOverflowError和OutofMemoryError。
2.5 程序计数器
简称PC(Program Counter Register),为线程私有,如果执行的是一个Java方法,那么此时PC里保存的是当前Java字节码的指令地址;如果说执行的是Native方法,那么PC的内容则为空。
2.6 直接内存
这部分内存不属于JVM的内存区域,在这里提出来也是为了在心里对这个有一定的了解。在JDK1.4中提出来的NIO中,就存在这直接访问机器内存的情况,从而避免了机器内存到JVM内存之间数据的来回拷贝情况,能够提高性能。在虚拟机内存调优时,可能常常容易被遗忘的部分就是这部分内存了。这也是有时候,Java程序实际占用的内存大于-Xmx所限制的内存大小的原因之一。
三、Hotspot虚拟机对象分析
3.1 对象的布局
Hotspot JVM中,对象在内存中的布局包括3块区域:对象头(header),对象实例数据(Instance Data)和对齐填充(Padding)。
3.1.1 对象头(Header)
对象头又包含两部分内容:Markword和reference(类类型指针)
3.1.1.1 Markword
用于存储运行时自身的数据,包括哈希码、GC分代年龄、偏向锁标记、线程持有的锁、偏向线程ID、偏向时间戳等。
从markOop.hpp中的注释中,我们可以详细的了解到Markword各个bit位所代表的内容和含义
// Bit-format of an object header (most significant first, big endian layout below): // // 32 bits: // -------- // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) // // 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) // // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
以32位的系统为例,能总结出如下表:
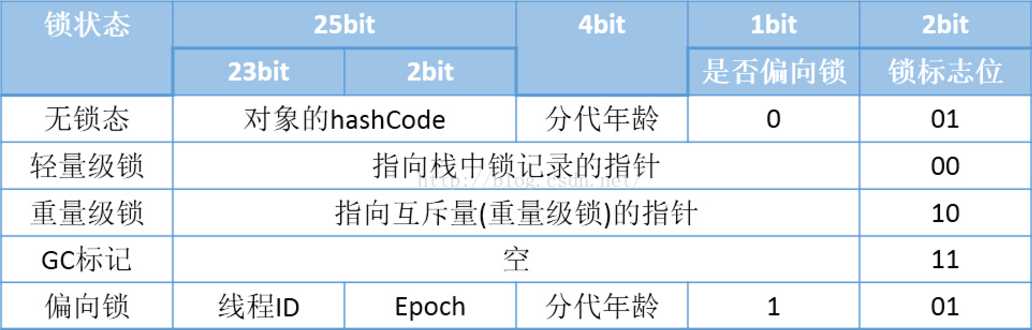
图3.1
3.1.2 reference(类类型指针)
用于指向对象的类的元数据的指针,通过这个指针,JVM可以知道,这个对象是属于哪个类的实例对象。当然,并不是所有的JVM的实现都会把对象的类类型指针保留在对象上的(这里是由Java对象的内存访问定位实现来决定的)。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
当Java对象的内存访问定位是直接指针访问时(大部分JVM这样实现),才会在对象的头部保存类类型指针,如图
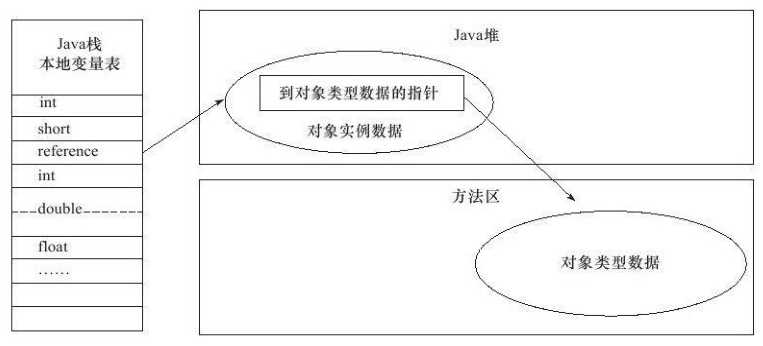
图3.2 直接指针访问对象
当Java对象的内存访问定位采用的是句柄访问时,则不会在对象的头部保存类类型指针,如图
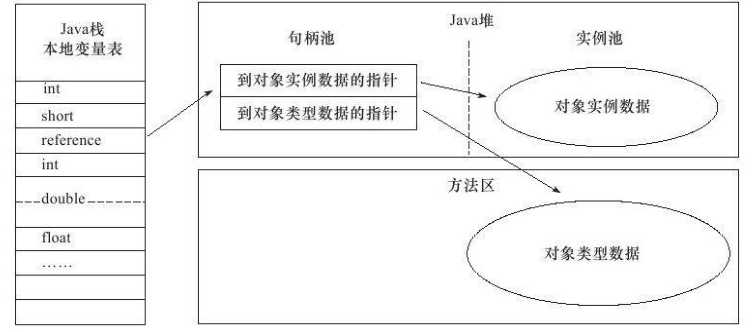
图3.3 句柄访问对象
3.2 JVM对象内存分配过程
通过源码(bytecodeInterpreter.cpp)中的来分析,如下:
// 如果是new操作的时候
CASE(_new): { u2 index = Bytes::get_Java_u2(pc+1); ConstantPool* constants = istate->method()->constants(); if (!constants->tag_at(index).is_unresolved_klass()) { // Make sure klass is initialized and doesn‘t have a finalizer // 1. 确保类已经初始化,及类已经加载/验证/准备/解析/初始化完成了。
Klass* entry = constants->slot_at(index).get_klass();
// 确保类已经被解析
assert(entry->is_klass(), "Should be resolved klass"); Klass* k_entry = (Klass*) entry;
// 确保类已经被初始化 assert(k_entry->oop_is_instance(), "Should be InstanceKlass"); InstanceKlass* ik = (InstanceKlass*) k_entry;
// 2. 如果类已经初始化并且能够进行快速内存分配 if ( ik->is_initialized() && ik->can_be_fastpath_allocated() ) {
// 获取对象实例的大小 size_t obj_size = ik->size_helper(); oop result = NULL; // If the TLAB isn‘t pre-zeroed then we‘ll have to do it
// 如果在TLAB上分配内存,如果TLAB上事先未将内存进行置零处理,则后续在内存分配完毕之后,需要将对象所在的内存进行置零操作 bool need_zero = !ZeroTLAB; if (UseTLAB) {
// 如果开启了线程的TLAB,则直接在线程的TLAB上给对象分配内存,如果分配成功,则返回对象的地址,否则返回null,是否开启TLAB是通过虚拟机参数:-XX:+/-UseTLAB参数来设定,默认是开启的。 result = (oop) THREAD->tlab().allocate(obj_size); } // Disable non-TLAB-based fast-path, because profiling requires that all // allocations go through InterpreterRuntime::_new() if THREAD->tlab().allocate // returns NULL. #ifndef CC_INTERP_PROFILE if (result == NULL) {
// 如果在TLAB上未成功分配到内存给对象,则从堆上为对象分配内存 need_zero = true; // Try allocate in shared eden retry:
// 获取堆顶的地址 HeapWord* compare_to = *Universe::heap()->top_addr();
// 获取分配obj_size字节的内存后,堆顶的位置 HeapWord* new_top = compare_to + obj_size;
// 如果堆顶地址小于或等于堆的最大内存地址,则采用原子操作CAS,将堆顶的地址指向new_top,从而完成内存的分配 if (new_top <= *Universe::heap()->end_addr()) { if (Atomic::cmpxchg_ptr(new_top, Universe::heap()->top_addr(), compare_to) != compare_to) { goto retry; }
// 如果CAS操作成功,则表示内存分配成功,然后把原来堆顶的内存地址赋值给指向对象的引用,即对象的内存地址 result = (oop) compare_to; } } #endif if (result != NULL) { // Initialize object (if nonzero size and need) and then the header
// 如果对象不为空,且需要置零,则置零处理 if (need_zero ) {
// 我们知道,对象的头是不能置零处理的,只有对象的body部分能置零处理,所以跳过对象的头部内存sizeof(oopDesc)/oopSize部分 HeapWord* to_zero = (HeapWord*) result + sizeof(oopDesc) / oopSize; obj_size -= sizeof(oopDesc) / oopSize; if (obj_size > 0 ) {
// 置零处理 memset(to_zero, 0, obj_size * HeapWordSize); } }
// 如果对象使用偏向锁 if (UseBiasedLocking) { result->set_mark(ik->prototype_header()); } else { result->set_mark(markOopDesc::prototype()); }
// 内存对齐 result->set_klass_gap(0);
// 设置对象的类元数据信息 result->set_klass(k_entry); // Must prevent reordering of stores for object initialization // with stores that publish the new object. OrderAccess::storestore(); SET_STACK_OBJECT(result, 0);
// 更新PC的指令地址,执行吓一条指令 UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1); } } } // Slow case allocation
// 如果未执行快速内存划分,则执行慢速内存划分,可能会采用锁的机制来完成,效率会比较低
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index), handle_exception); // Must prevent reordering of stores for object initialization // with stores that publish the new object. OrderAccess::storestore(); SET_STACK_OBJECT(THREAD->vm_result(), 0); THREAD->set_vm_result(NULL); UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1); }
从以上源码,简单的总结下对象内存分配的过程:
1). 确保类已经初始化,及类已经加载/验证/准备/解析/初始化完成了;
2). 判断该类的实例对象是否能够进行快速内存分配,如果是,则继续,否则跳到10;
3). 判断JVM是否开启了TLAB选项,如果是则继续,否则跳到7;
4). 从线程的TLAB进行内存分配;
5). 判断TLAB内存分配是否成功,如果失败,则继续,否则跳到7;
6). 如果TLAB内存分配失败,且未定义CC_INTERP_PROFILE,则通过CAS继续进行快速内存分配;
7). CAS内存分配成功(如果失败,则会抛出OutOfMemoryError的异常,而导致程序终止),则根据实际情况看是否要对对象的内存进行初始化操作(置零);
8). 设置对象的头的MarkWord和对象所属类的元数据信息;
9). 设置PC的地址为下一条字节码的地址,并继续执行下一条字节码,本次内存分配结束;
10). 进入JVM的慢速内存分配通道,进行内存分配。
四、总结
本文首先阐述了一下让笔者在学习之初比较困惑的3个问题,然后结合有关参考资料和Hotspot的源码分析对JVM的内存布局以及对象内存的分配过程做了比较细致的学习和分析,同时对对象在JVM中的表示进行分析。基本上弄清楚了JVM中的内存概念布局。后续还需要在JMM和垃圾回收的算法等方面加强对JVM的内存模型理解。
参考资料:
2. http://blog.csdn.net/shiyong1949/article/details/52585256
内存区域介绍
3. http://www.cnblogs.com/douba/p/a-simple-example-demo-jvm-allocation-and-gc.html
最简单例子图解JVM内存分配和回收
4.http://www.idouba.net/java-gc-policies/
java 垃圾回收策略
5. 虚拟机配置相关参数
JDK7及以前版本:http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html
JDK8: http://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
6. java并发之内存模型(JMM)
http://www.idouba.net/topics/jvm/
7.http://www.cnblogs.com/SaraMoring/p/5713732.html
JVM内存堆布局图解分析
8. http://blog.csdn.net/yangzl2008/article/details/43202969
Java中的逃逸分析和TLAB中以及Java对象分配
9. http://blog.csdn.net/zhoufanyang_china/article/details/54601311
不得不了解的对象头
标签:stp 记录 sha bsp 内存区域 do it psi demo for
原文地址:http://www.cnblogs.com/scofield-1987/p/7502969.html