标签:div c++编程 微软 接口 时钟 assert 大内存 选择 数据结构
请以“仰望星空与脚踏实地”作为题目,写一篇不少于800字的文章。除诗歌外,文体不限。
——2010·北京卷
Caffe诞生于12年末,如果偏要形容一下这个框架,可以用"须敬如师长"。
这是一份相当规范的代码,这个规范,不应该是BAT规范,那得是Google规范。
很多自称码农的人应该好好学习这份代码,改改自己丑陋的C++编程习惯。
下面列出几条重要的规范准则:
★const
先说说const问题,Google为了增加代码的可读性,明确要求:
不做修改的量(涵盖函数体内、函数参数列表),必须以const标记。
相对的,对于那些改变的量,可选择用mutable标记。
因为mutable关键词不是很常用,所以一般在自设函数中使用。
严格的const不在于担心变量是否被误修改,而在于给代码阅读者一个清晰的思路:
这个值不会改变,这个值肯定要改变。
★引用
"引用"是C/C++设计的一个败笔,因为C/C++默认是深拷贝,这在大内存数据结构操作的时候,
容易让新手程序员写出弱智低能的代码。假设Datum结构A使用了2G内存,令:
Datum B=A;
那么,内存会占用4G空间,而且,我们大概需要几秒的时间去拷贝A的2G内存。
这个几秒看起来不是很成问题,但是在多线程编程中,两个异步线程共享数据:
如果你不用引用会怎么样?
很有趣,这个复制再赋值的操作会被CPU中断,变成无效指令。
这在Caffe的多线程I/O设计架构中,是个关键点。
另外,对于基本数据类型(char/int/float/double),引用是没用必要的。
但是,string、vector<int>等容器,引用就相当有必要了。
★const引用
const引用最常见于函数参数列表,用于传递常、大数据结构量。
与此相对的,如果你要修改一个大数据结构量,应当在参数列表中传入指针,而不是引用。
传入引用来修改是C规范,传入指针来修改是C++规范,Caffe严格遵照C++规范,这点要明确。
★常成员函数
常成员函数,在OO里通常容易被新手忽略掉。(Java就没那么复杂),通常写作:
void xxx() const,目的是:
const标记住传入成员函数的this指针。
常成员函数其实不是必要的,但是在一定情况下,就会变成必要的。
这个情况相当有趣,而且在Caffe中也经常发生:
void xxx(const Blob& blob){
blob.count();
}
如果我们遵照Google的编程规范,用const引用锁定传入的Blob。
那么,blob.count()这个成员函数的调用就会被编译器的语义分析为:成员变量不可修改。
如果你的代码写成这样,那就会被编译器拦下,错误信息为:this指针不一致。
class Blob{
public:
int count() {} //错误
int count() const {} //正确
};
★public、private、protected
OO的封装性是比较难定位的一个规范,成员变量及成员函数如何访问权限是个问题。
Caffe严格遵照标准的OO封装概念:方法是public,变量是private或者是protected。
区别private和protected就一句话:
private成员变量或是函数,不可能被继承。通常只用在本Class独有,而派生类不直使用的函数/变量上。
比如im2col和col2im,这两个为卷积做Patch预变换的函数。
protected和private的成员函数和成员变量都不可能从外部被访问,应当在public里专门设置访问接口。
并且接口根据需要,恰当使用const标记,避免越权访问。
有趣的是,如果这么做,会增加相当多的代码量,而且都是一些复制粘贴的废品代码。
为了避免这种情况,Google开发了Protocol Buffer,将数据结构大部分访问接口自动生成,且独立安排。
这样,在主体代码里,我们不会因为数据的访问接口的规范,而导致阅读代码十分头疼(想想那一扫下来的废代码)。
如果你研究过Word2Vec的源码,应该就知道,为什么Word2Vec必须跑在Linux下。。
因为Mikolov同学在写代码的时候,用了POSIX OS的API函数pThread,来实现内核级线程。
这为跨平台带来麻烦,一份优秀的跨平台代码,必须具有相当出色的平台独立性。
在这点上,Caffe使用了C++最强大的Boost库,来避免对OS API函数的使用。
Boost库,又称为C++三千佳丽的后宫,内涵1W+头文件,完整编译完大小达3.3G,相当庞大。
它的代码来自世界上顶级的C++开发者,是C++最忠实的第三方库,并且是ISO C++新规范的唯一来源。
Boost在Caffe中的主要作用是提供OS独立的内核级线程。
当然,已经于C++11中被列入规范的boost::shared_ptr其实也算。
还有一个十分精彩的boost::thread_specific_ptr,也在Caffe中起到了核心作用。
不足之处也有,而且其中一处还成了Bug,那就是API函数之一的open。
linux的open默认是以二进制打开的,而Windows则是以文本形式打开的。
移植到Windows时,需要补上 O_BINARY作为flag。
大家都知道Caffe能跑GPU,一个关键点是:
它是在何处,又是怎么进行CPU与GPU分离的?
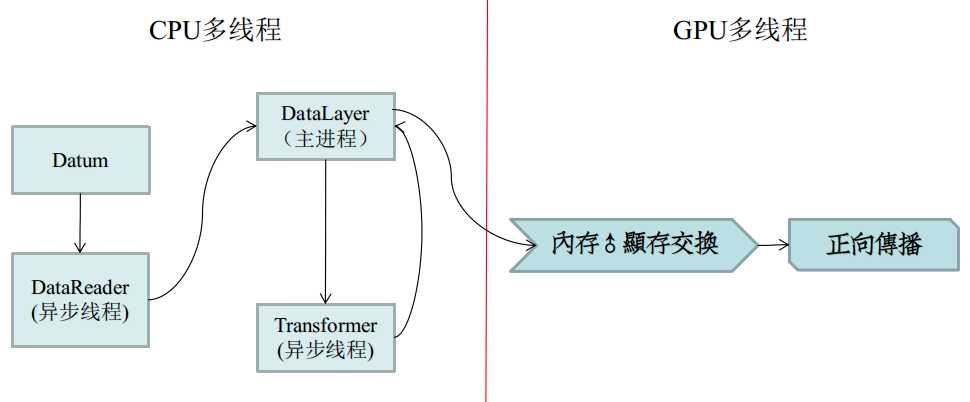
这个模型实际上应当算是CUDA标准模型。
由于内存显存不能跨着访问(一个在北桥,一个在南桥),又要考虑的CPU和GPU的平衡。
所以,数据的读取、转换不仅要被平摊到CPU上,而且应当设计成多线程,多线程的生产者消费者模型。
并且具有一定的多重缓冲能力,这样保证最大化CPU/GPU的计算力。
在一个机器学习系统当中,我们要珍惜计算设备的每一个时钟周期,切实做到计算力的最大化利用。
实际使用的设计模式只有两个。
第一个是MVC,这个其实是迫不得已。
异构编程决定着,数据、视图、控制三大块必须独立开来。
但视图和控制并不是很明显,在设计接口/可视化GUI的时候,将凸显重要性。
第二个称为工厂模式,这是一个存在于Java的概念,尽管C++也可以模仿。
具体来说,工厂模式是为了弥补面向对象型编译语言的不足,会被OO的多态所需要。
以Caffe为例:
我们当前有一个基类指针Layer* layer;
在程序运行之前,计算机并不知道这个指针究竟要指向何种派生类。是卷积层?Pooling层?ReLU层?
鬼才知道。一个愚蠢的方法:
if(type==CONV) {....}
else if(type==POOLING) {....}
else if(type==RELU} {.....}
else {ERROR}
看起来,还是可以接受的,但是在软件工程专业看来,这种模式相当得蠢。
工厂模式借鉴了工厂管理产品的经验,将各种类型存在数据库中,需要时,拿出来看看。
这种模式相当得灵活,当然,在Caffe中作用不是很大,仅仅是为了花式好看。
要实现这个模式,你只需要一个关联容器(C++/JAVA),字典容器(Python)。
将string与创建指针绑定即可。
C/C++中有函数指针的说法,如:
typedef boost::shared_ptr< Layer<Dtype> > (*NEW_FUNC)(const LayerParameter& );
经过typdef之后,NEW_FUNC就可以指向函数:
boost::shared_ptr< Layer<Dtype> > xxx(const LayerParameter& x); NEW_FUNC yyy=boost::shared_ptr< Layer<Dtype> > xxx(const LayerParameter& x); yyy(); //相当于xxx() xxx();
需要访问工厂时,我们只需要访问这个代替工厂管理数据库的容器,而不是幼稚地使用if(.....)
如果Caffe不使用Protocol Buffer,那么代码量将扩大一倍。
这不是危言耸听,在传统系统级程序设计中,序列化与反序列化一直是一个码农问题。
尤其是在机器学习系统中,复杂多变的数据结构,给序列化和反序列化带来巨大麻烦。
Protocol Buffer在序列化阶段,是一个高效的编码器,能将数据最小体积序列化。
而在反序列化阶段,它是一个强大的解码器,支持二进制/文本两类数据的解析与结构反序列化。
其中,从文本反序列化意义颇大,这就形成了Caffe著名的文本配置文件prototxt,用于net和solver。
相对灵活的配置方式,尤其适合超大规模神经网络,这点在早期机器学习系统中独领风骚(很多人认为这比图形界面还要方便)。
据说写库狂人都是用宏狂人。
C/C++提供了强大了自定义宏函数(#define),Caffe通过宏,大概减少了1000~2000行代码。
宏函数大致有如下几种:
① #define DISABLE_COPY_AND_ASSIGN(classname)
俗称禁止拷贝和赋值宏,如果你熟悉Qt,就会发现,Qt中大部分数据结构都用了这个宏来保护。
这个宏算是最没用的宏,用在了所有Caffe大型数据结构上(Blob、Layer、Net、Solver)
目的是禁止两个大型数据结构直接复制、构造、然后赋值。
实际上,Caffe也没有去编写复制构造函数代码,所以最终还是会被编译器拦下。
前面以及说过了,两个大型数据结构之间的复制会是什么样的下场,这是绝对应该被禁止的。
如果你要使用一个数据结构,请用指针或是引用指向它。
如果你有乱赋值的编程陋习,请及时打上这个宏,避免自己手贱。反之,可以暂时无视它。
当然,从库的完整性角度,这个宏是明智的。
Java/python不需要这个宏,因为Java对大型数据结构,默认是浅拷贝,也就是直接引用。
而Python,这个没有数据类型的奇怪语言,则默认全部是浅拷贝。
②#define INSTANTIATE_CLASS(classname)
非常非常非常重要的宏,重要的事说三遍。
由于Caffe采用分离式模板编程方法(据说也是Google倡导的)
模板未类型实例化的定义空间和实例化的定义空间是不同的。
实际上,编译器并不会理睬分离在cpp里的未实例化的定义代码,而是将它放置在一个虚拟的空间。
一旦一段明确类型的代码,访问这段虚拟代码空间,就会被编译器拦截。
如果你想要让模板的声明和定义分离编写,就需要在cpp定义文件里,将定义指定明确的类型,实例化。
这个宏的作用正是如此。(Google编程习惯的宏吧)。
更详细的用法,将在后续文章中详细介绍。
③#define INSTANTIATE_LAYER_GPU_FUNCS(classname)
通样是实例化宏,专门写这个宏的原因,是因为NVCC编译器相当傲娇。
打在cpp文件里的INSTANTIATE_CLASS宏,NVCC在编译cu文件时,可不会知道。
所以,你需要在cu文件里,为这些函数再次实例化。
其实也没几个函数,也就是forward_gpu和backward_gpu
④#define NOT_IMPLEMENTED
俗称偷懒宏,你要是这段代码不想写了,打个NOT_IMPLEMENTED就行了。
就是宣告:“老子就是不想写这段代码,留空,留空!”
但是注意,宏封装了LOG(FATAL),这是个Assert(断言),会引起CPU硬件中断。
一旦代码空间转到你没写的这段,整个程序就会被终止。
所以,偷懒有度,还是认真写代码吧。
⑤#define REGISTER_LAYER_CLASS(type)
Layer工厂模式用的宏,也就是将这个Layer的信息写到工厂的管理数据库里。
此宏省了不少代码,在使用工厂之前,记得要为每个成品(Layer)打上这个宏。
Caffe为了与Boost等库接轨,几乎为所有结构提供了以caffe为关键字的命名空间。
设置命名空间的主要目的是防止Caffe的函数、变量与其他库产生冲突。
在我们的山寨过程中,为了代码的简洁,将忽略全部的命名空间。
Caffe中普遍采用下划线命名法。
我们对其作出了部分修改,整体采用两种命名法:
①针对变量而言: 采用下划线命名法
②针对函数而言:采用驼峰命名法
Caffe几乎是C++ Primer 第五版的鲜活例子,如果你需要读懂它,经常翻一翻C++ Primer是一个不错的主意。
(另:不要阅读C++ Primer Plus,它的作者仅仅是一个普通教师,
而C++ Primer作者则包含C++协发明者、ISO C++委员会的人,是权威圣经)
注意你接触的是一个系统级程序,Windows还是全球5000位微软工程师开发的。
系统级程序相当庞大和复杂,切记不要心浮气躁,不要以套库的心理去学习。
更不要认为,看看高层代码就可以了,这简直是噩梦,最后你会发现你根本读不懂。
为自己的工程取个名字是一件有趣的事,本项目默认名为:Dragon。
因为深度神经网络活像一头蠢龙。
标签:div c++编程 微软 接口 时钟 assert 大内存 选择 数据结构
原文地址:http://www.cnblogs.com/mengmengmiaomiao/p/7511364.html