标签:zed enum bre tran 一点 具体细节 mon targe 检查
你左手是内存,右手是显存,内存可以打死显存,显存也可以打死内存。
—— 请协调好你的主存
大部分Caffe源码解读都喜欢跳过这部分,我不知道他们是什么心态,因为这恰恰是最重要的一部分。
内存的管理不擅,不仅会导致程序的立即崩溃,还会导致内存的泄露,当然,这只针对传统CPU程序而言。
由于GPU的引入,我们需要同时操纵俩种不同的存储体:
一个受北桥控制,与CPU之间架起地址总线、控制总线、数据总线。
一个受南桥控制,与CPU之间仅仅是一条可怜的PCI总线。
一个传统的C++程序,在操作系统中,会被装载至内存空间上。
一个有趣的问题,你觉得CPU能够访问显存空间嘛?你觉得你的默认C++代码能访问显存空间嘛?
结果显然是否定的,问题就在于CPU和GPU之间只存在一条数据总线。
没有地址总线和控制总线,你除了让CPU发送数据拷贝指令外,别无其它用处。
这不是NVIDIA解决不了,AMD就能解决的问题。除非计算机体系结构再一次迎来变革,
AMD和NVIDIA的工程师联名要求在CPU和GPU之间追加复杂的通信总线用于异构程序设计。
当然,你基本是想多了。
可怜的数据总线,加大了异构程序设计的难度。
于是我们看到,GPU的很大一部分时钟周期,用在了和CPU互相交换数据。
也就是所谓的“内存与显存之间友好♂关系”。
你不得不接受一个事实:
GPU最慢的存储体,也就是片外显存,得益于镁光的GDDR技术,目前家用游戏显卡的访存速度也有150GB/S。
而我们可怜的内存呢,你以为配上Skylake后,DDR4已经很了不起了,实际上它只有可怜的48GB/S。
那么问题来了,内存如何去弥补与显存的之间带宽的差距?
答案很简单:分时、异步、多线程。
换言之,如果GPU需要在接下来1秒内,获得CPU的150GB数据,那么CPU显然不能提前一秒去复制。
它需要提前3秒、甚至4秒。如果它当前还有其它串行任务,你就不得不设个线程去完成它。
这就是新版Caffe增加的新功能之一:多重预缓冲。
设置于DataLayer的分支线程,在GPU计算,CPU空闲期间,为显存预先缓冲3~4个Batch的数据量,
来解决内存显存带宽不一致,导致的GPU时钟周期浪费问题,也增加了CPU的利用率。
最终,你还是需要牢记一点:
不要尝试以默认的C++代码去访问显存空间,除非你把它们复制回内存空间上。
否则,就是一个毫无提示的程序崩溃问题(准确来说,是被CPU硬件中断了【微机原理或是计算机组成原理说法】)
在传统的CUDA程序设计里,我们往往经历这样一个步骤:
->计算前
cudaMalloc(....) 【分配显存空间】
cudaMemset(....) 【显存空间置0】
cudaMemcpy(....) 【将数据从内存复制到显存】
->计算后
cudaMemcpy(....) 【将数据从显存复制回内存】
这些步骤相当得繁琐,你不仅需要反复敲打,而且如果忘记其中一步,就是毁灭性的灾难。
这还仅仅是GPU程序设计,如果考虑到CPU/GPU异构设计,那么就更麻烦了。
于是,聪明的人类就发明了主存管理自动机,按照按照一定逻辑设计状态转移代码。
这是Caffe非常重要的部分,称之为SyncedMemory(同步存储体)。
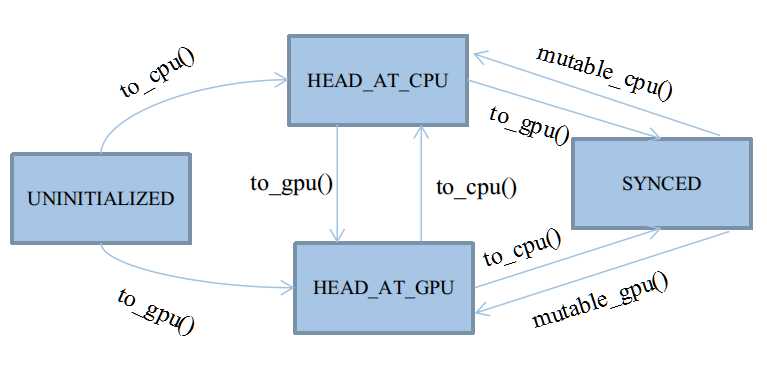
自动机共有四种状态,以枚举类型定义于类SyncedMemory中:
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
这四种状态基本会被四个应用函数触发:cpu_data()、gpu_data()、mutable_cpu_data()、mutable_gpu_data()
在它们之上,有四个状态转移函数:to_cpu()、to_gpu()、mutable_cpu()、mutable_gpu()
前两个状态转移函数用于未进入Synced状态之前的状态机维护,后两个用于从Synced状态中打破出来。
具体细节见后文,因为Synced状态会忽略to_cpu和to_gpu的行为,打破Synced状态只能靠人工赋值,切换状态头head。
后两个mutable函数会被整合在应用函数里,因为它们只需要简单地为head赋个值,没必要大费周章写个函数封装。
★UNINITIALIZED:
UNINITIALIZED状态很有趣,它的生命周期是所有状态里最短的,将随着CPU或GPU其中的任一个申请内存而终结。
在整个内存周期里,我们并非一定要遵循着,数据一定要先申请内存,然后在申请显存,最后拷贝过去。
实际上,在GPU工作的情况下,大部分主存储体都是直接申请显存的,如除去DataLayer的前向/反向传播阶段。
所以,UNINITIALIZED允许直接由to_gpu()申请显存。
由此状态转移时,除了需要申请内存之外,通常还需要将内存置0。
★HEAD_AT_CPU:
该状态表明最近一次数据的修改,是由CPU触发的。
注意,它只表明最近一次是由谁修改,而不是谁访问。
在GPU工作时,该状态将成为所有状态里生命周期第二短的,通常自动机都处于SYNCED和HEAD_AT_GPU状态,
因为大部分数据的修改工作都是GPU触发的。
该状态只有三个来源:
I、由UNINITIALIZED转移到:说白了,就是钦定你作为第一次内存的载体。
II、由mutable_cpu_data()强制修改得到:都要准备改数据了,显然需要重置状态。
cpu_data()及其子函数to_cpu(),只要不符合I条件,都不可能转移到改状态(因为访问不会引起数据的修改)
★HEAD_AT_GPU:
该状态表明最近一次数据的修改,是由GPU触发的。
几乎是与HEAD_AT_CPU对称的。
★SYNCED:
最重要的状态,也是唯一一个非必要的状态。
单独设立同步状态的原因,是为了标记内存显存的数据一致情况。
由于类SyncedMemory将同时管理两种主存的指针,
如果遇到HEAD_AT_CPU,却要访问显存。或是HEAD_AT_GPU,却要访问内存,那么理论上,得先进行主存复制。
这个复制操作是可以被优化的,因为如果内存和显存的数据是一致的,就没必要来回复制。
所以,使用SYNCED来标记数据一致的情况。
SYNCED只有两种转移来源:
I、由HEAD_AT_CPU+to_gpu()转移到:
含义就是,CPU的数据比GPU新,且需要使用GPU,此时就必须同步主存。
II、由HEAD_AT_GPU+to_cpu()转移到:
含义就是,GPU的数据比CPU新,且需要使用CPU,此时就必须同步主存。
在转移至SYNCED期间,还需要做两件准备工作:
I、检查当前CPU/GPU态的指针是否分配主存,如果没有,就重新分配。
II、复制主存至对应态。
处于SYNCED状态后,to_cpu()和to_gpu()将会得到优化,跳过内部全部代码。
自动机将不再运转,因为,此时仅需要返回需要的主存指针就行了,不需要特别维护。
这种安宁期会被mutable前缀的函数打破,因为它们会强制修改至HEAD_AT_XXX,再次启动自动机。
建立synced_memory.hpp,在操作主存之前,你需要封装一些基础函数。
CPU端的函数是C/C++标准的通用函数:


inline void dragonMalloc(void **ptr, size_t size){
*ptr = malloc(size);
CHECK(*ptr) << "host allocation of size " << size << " failed";
}
inline void dragonFree(void *ptr){
free(ptr);
}
inline void dragonMemset(void *ptr,size_t size){
memset(ptr, 0, size);
}
inline void dragonMemcpy(void* dest, void* src,size_t size){
memcpy(dest, src, size);
}
CHECK宏由GLOG提供,条件为假时,会触发assert,终结程序。
GPU端的函数由CUDA提供:
#ifndef CPU_ONLY
#include "cuda.h"
inline void cudaSetDevice(){
int device;
cudaGetDevice(&device);
if (device != -1) return;
CUDA_CHECK(cudaSetDevice(0));
}
inline void dragonGpuMalloc(void **ptr, size_t size){
cudaSetDevice();
CUDA_CHECK(cudaMalloc(ptr, size));
}
inline void dragonGpuFree(void *ptr){
cudaSetDevice();
CUDA_CHECK(cudaFree(ptr));
}
inline void dragonGpuMemset(void *ptr, size_t size){
cudaSetDevice();
CUDA_CHECK(cudaMemset(ptr, 0, size));
}
inline void dragonGpuMemcpy(void *dest, void* src, size_t size){
cudaSetDevice();
CUDA_CHECK(cudaMemcpy(dest, src, size, cudaMemcpyDefault));
}
#endif
#ifndef CPU ONLY ..... #endif 确保本段代码不会被非CUDA模式所编译
cudaSetDevice()是一个通用函数,在后期,你应该移至common.hpp中。
该函数不是必要的,目的只是对当前执行GPU的一个惯性检查,检查失败则终结程序。
需要注意的是cudaMemcpy的最后一个参数,Flag:cudaMemcpyDefault,在CUDA 6.0之后才被使用。
在6.0版本之前,cudaMemcpy需要指明dest和src的来源,是host向device,还是device向host,还是device向device?
所以,早期的CUDA代码可能需要三个if来指明Flag的值,而cudaMemcpyDefault会自动检测,相当智能。
class SyncedMemory
{
public:
SyncedMemory():cpu_ptr(NULL), gpu_ptr(NULL), size_(0), head_(UNINITIALIZED) {}
SyncedMemory(size_t size) :cpu_ptr(NULL), gpu_ptr(NULL), size_(size), head_(UNINITIALIZED) {}
void to_gpu();
void to_cpu();
const void* cpu_data();
const void* gpu_data();
void set_cpu_data(void *data);
void set_gpu_data(void *data);
void* mutable_cpu_data();
void* mutable_gpu_data();
#ifndef CPU_ONLY
void async_gpu_data(const cudaStream_t& stream);
#endif
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
void *cpu_ptr, *gpu_ptr;
size_t size_;
bool own_cpu_data, own_gpu_data;
SyncedHead head_;
SyncedHead head() { return head_; }
size_t size() { return size_; }
~SyncedMemory();
};
成员变量包括:
★两个主存指针:cpu_ptr、gpu_ptr
★主存大小size以及状态标记head
★共享标记:own_cpu_data、 own_gpu_data
成员函数包括:
★状态转移函数:void to_gpu()、void to_cpu()
★常访问函数:const void* cpu_data()、 const void* gpu_data()
★修改函数:void* mutable_cpu_data()、void* mutable_gpu_data()
★共享函数:void set_cpu_data(void *data)、void set_gpu_data(void *data)
★封装访问函数:SyncedHead head()、size_t size()
★异步流同步函数与析构函数:void async_gpu_data(const cudaStream_t& stream)、~SyncedMemory()
值得注意的是,两个共享函数以及共享标记不属于自动机范围。
共享函数的唯一用处是用于局部主存的共享,只用于DataLayer的Transformer中。
在Blob级别的共享中,存在两种共享:
I、共享另一个Blob的全部数据:只需要让SyncedMemory指针重新指向另一个Blob的SyncedMemory指针
II、共享另一个Blob的部分数据:
这利用了C/C++内存指针的一个Trick,内存首指针可以做代数加减运算,做一定偏移。
set_xxx_data(void *data)提供了最底层的指针修改,可以直接指向偏移之后的内存,而共享部分数据。
建立synced_memory.cpp。
void SyncedMemory::to_cpu()
{
switch (head_){
case UNINITIALIZED:
dragonMalloc(&cpu_ptr, size_);
dragonMemset(cpu_ptr, size_);
head_ = HEAD_AT_CPU;
own_cpu_data = true;
break;
case HEAD_AT_GPU:
#ifndef CPU_ONLY
if (cpu_ptr == NULL){
dragonMalloc(&cpu_ptr, size_);
own_cpu_data = true;
}
dragonGpuMemcpy(cpu_ptr,gpu_ptr,size_);
head_ = SYNCED;
#endif
break;
case HEAD_AT_CPU:
case SYNCED:
break;
}
}
需要注意的是共享标记own_xxx_data,只要申请了内存,就必须做标记。
共享标记在析构时是必要的,因为你不能将宿主数据一并释放掉。
void SyncedMemory::to_gpu()
{
#ifndef CPU_ONLY
switch (head_){
case UNINITIALIZED:
dragonGpuMalloc(&gpu_ptr,size_);
dragonGpuMemset(gpu_ptr, size_);
head_ = HEAD_AT_GPU;
own_gpu_data = true;
break;
case HEAD_AT_CPU:
if (gpu_ptr == NULL){
dragonGpuMalloc(&gpu_ptr,size_);
own_gpu_data = true;
}
dragonGpuMemcpy(gpu_ptr, cpu_ptr, size_);
head_ = SYNCED;
break;
case HEAD_AT_GPU:
case SYNCED:
break;
}
#endif
}
GPU的转移函数是与CPU版本对称的。
const void* SyncedMemory::cpu_data(){
to_cpu();
return (const void*)cpu_ptr;
}
const void* SyncedMemory::gpu_data(){
to_gpu();
return (const void*)gpu_ptr;
}
常访问函数,注意const指针的强制转换,访问之前需要运行一次自动机。
void* SyncedMemory::mutable_cpu_data(){
to_cpu();
head_ = HEAD_AT_CPU;
return cpu_ptr;
}
void* SyncedMemory::mutable_gpu_data(){
#ifndef CPU_ONLY
to_gpu();
head_ = HEAD_AT_GPU;
return gpu_ptr;
#endif
}
修改函数,运行自动机、强制修改自动机状态,最后返回指针,用于从外部修改。
void SyncedMemory::set_cpu_data(void *data){
if (own_cpu_data) dragonFree(cpu_ptr);
cpu_ptr = data;
head_ = HEAD_AT_CPU;
own_cpu_data = false;
}
void SyncedMemory::set_gpu_data(void *data){
#ifndef CPU_ONLY
if (own_gpu_data) dragonGpuFree(gpu_ptr);
gpu_ptr = data;
head_ = HEAD_AT_GPU;
own_gpu_data = false;
#endif
}
共享函数,共享之前,先释放旧主存,修改共享标记,强制修改自动机状态。
SyncedMemory::~SyncedMemory(){
if (cpu_ptr && own_cpu_data) dragonFree(cpu_ptr);
#ifndef CPU_ONLY
if (gpu_ptr && own_gpu_data) dragonGpuFree(gpu_ptr);
#endif
}
析构函数,注意检查共享标记,不能释放宿主内存。
异步流概念,是CUDA 5.0中引入的。
与Intel CPU的流水线架构一样,NVIDIA的GPU也采用了I/O和计算分离的流水线做法。
cudaMemcpy使用的是默认流cudaStreamDefault,编号为0。
异步流编程API开放之后,允许程序员在CPU端多线程编程中,向GPU提交异步的同步复制流,
以此增加GPU端的I/O利用率。
简单来说,默认流只允许主进程与显存复制数据,而我们实际上不可能这么干,原因有二:
I、效率低,主进程就是单线程啊。
II、很多情况下,数据复制完之前,需要阻塞。阻塞主进程不是一个好主意。
Caffe中只有一处是这么做的,那就是DataLayer正向传播一个Batch的时候,这个阻塞是必然的。
但是,在构成Batch之前,只要采取多线程设计,那么异步流复制只会阻塞旁支线程,而不会影响主进程。
这是为什么NVIDIA开放异步流API的原因,它鼓励了CPU用于多线程I/O,让GPU计算如虎添翼。
#ifndef CPU_ONLY
void SyncedMemory::async_gpu_data(const cudaStream_t& stream){
CHECK(head_ == HEAD_AT_CPU);
// first allocating memory
if (gpu_ptr == NULL){
dragonGpuMalloc(&gpu_ptr, size_);
own_gpu_data = true;
}
const cudaMemcpyKind kind = cudaMemcpyHostToDevice;
CUDA_CHECK(cudaMemcpyAsync(gpu_ptr, cpu_ptr, size_, kind, stream));
head_ = SYNCED;
}
#endif
异步流的底层代码接受一个异步流作为参数,使用cudaMemcpyAsync()向GPU提交复制任务。
它等效于HEAD_AT_CPU+to_gpu(),所以需要更新同步标记。
完整代码将在DataLayer中完成,该函数将由多线程调用。
标签:zed enum bre tran 一点 具体细节 mon targe 检查
原文地址:http://www.cnblogs.com/mengmengmiaomiao/p/7511374.html