标签:cap ++i title 技术分享 演示 length wait 开始 python脚本
我们在实际工作中,遇到了一个这样的用例,在每天例行扫描活动中,发现有些应用系统不定期的被扫挂,因为我们不是服务的制造者,没有办法在不同的系统里打印日志,所以我们就想用一个工具来获取特定服务的输入数据流。我们如果不在IDS上看应用的服务,可以直接针对服务所在服务位置,针对应用端口进行,有针对性的监听分析。
Tshark和tcpdump、windump这些监听工具提供了比较丰富的命令行参数来监听流量数据。wireshark、burpsuite这些工具也提供相应的lua、python脚本的机制用于去处理监听的流量数据。但有些场景我们不会使用体积这么大的工具,命令行方式的监听工具又不能加入更多数据处理逻辑,细化对数据的操作。实际上我们可以自制一个小型的工具,做流量监听,是除了命令联合shell脚本,、wireshark、suricata等插件开发的另一种形式。现在很多的监听工具都是基于pcap的,我们基于pcap底层开发一个监听工具。
pcap支持C、python两种开发方式,基于C和pcap库的开发效率比pyton的性能高,这样在高性能的场景python就不太适合,但是从开发效率角度看,用python开发比C又要快很多,毕竟用C开发工具,需要进行边编译,一是有技术门槛,另外的确维护相对比较麻烦。
鉴于以上的原因,既要性能相对够高一些,又能便于维护,在命令行这个粒度上,又可以嵌入自己数据处理逻辑,定制化自己的运行时序,因些,我们选择了C和LUA配合的这种方式。实施方面,就是用C来处理pcap的主件循环,接受pcap监听的buffer数据。然后,将监听的数据通过C与LUA之间的通信,将数据推送给LUA。
数据交给LUA之后,如何管理数据的复杂性就靠LUA的设计方式来解决,因为流量数据是文本流式的,程序原型就想到了pipeline管道的方式进行组织管理。
有了管道的方式,我们就可以在一个监听数据流上,叠加各种插件进地监听数据的处理,可以把复杂的业务,拆解成若干个小的插件处理单元,写作完成任务。演示原型代码的C部分是很少的,主要的任务是获取buffer的数据,推送lua,代码如下:
#include <pcap.h>
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <lua.h>
#include <lauxlib.h>
#include <lualib.h>
lua_State* L = NULL;
void getPacket(u_char * arg, const struct pcap_pkthdr * pkthdr, const u_char * packet)
{
L = lua_open();
luaL_openlibs(L);
if (luaL_loadfile(L, "buffer.lua") || lua_pcall(L, 0,0,0))
printf("Cannot run configuration file:%s", lua_tostring(L, -1));
lua_getglobal(L, "buffer");
char *buffer = NULL;
buffer = (u_char*)malloc(pkthdr->len);
memcpy(buffer, packet, pkthdr->len);
lua_newtable(L);
int idx = 0;
for (idx=1; idx < pkthdr->len; idx++) {
lua_pushnumber(L, idx);
lua_pushnumber(L, packet[idx]);
lua_settable(L, -3);
}
lua_pcall(L, 1,0,0);
int * id = (int *)arg;
printf("id: %d\n", ++(*id));
printf("Packet length: %d\n", pkthdr->len);
printf("Number of bytes: %d\n", pkthdr->caplen);
printf("Recieved time: %s", ctime((const time_t *)&pkthdr->ts.tv_sec));
int i;
for(i=0; i<pkthdr->len; ++i) {
//printf(" %02x", packet[i]);
if( (i + 1) % 16 == 0 ) {
//printf("\n");
}
}
printf("\n\n");
free(buffer);
buffer = NULL;
}
int main()
{
char errBuf[PCAP_ERRBUF_SIZE], * devStr;
/* get a device */
devStr = "eth1";
if(devStr)
{
printf("success: device: %s\n", devStr);
}
else
{
printf("error: %s\n", errBuf);
exit(1);
}
/* open a device, wait until a packet arrives */
pcap_t * device = pcap_open_live(devStr, 65535, 1, 0, errBuf);
if(!device)
{
printf("error: pcap_open_live(): %s\n", errBuf);
exit(1);
}
/* construct a filter */
struct bpf_program filter;
pcap_compile(device, &filter, "dat port 80", 1, 0);
pcap_setfilter(device, &filter);
/* wait loop forever */
int id = 0;
pcap_loop(device, -1, getPacket, (u_char*)&id);
pcap_close(device);
return 0;
}
C部分将监听的流量buffer的数据,以数组的形式给lua,在lua中array其实就是一个table,我们在lua部分重组了一下数组数据,生成了一个字符串,代码如下:
buffer = function(tbl)
local tmpstr=‘‘
for k,v in pairs(tbl) do
tmpstr = tmpstr..string.char(v)
end
io.write(tmpstr,"\n")
end编译C程序就靠下面的命令行,后期我们也可以生成一个makefile简化编译流程。
gcc watch.c -I/usr/include/lua5.1 -ldl -lm -llua5.1 -lpcap -o watch为了方便 ,我们写了一个Makefile:
LUALIB=-I/usr/include/lua5.1 -lpcap -ldl -lm -llua5.1
.PHONY: all win linux
all:
@echo Please do \‘make PLATFORM\‘ where PLATFORM is one of these:
@echo win linux
win:
linux: watch
watch : watch.c
gcc $^ -o$@ $(LUALIB)
clean:
rm -f watch 为什么要使用管道插件的方式拆分和组织模块?以什么形式传送数据变成了一个手艺,解耦最直接的方法是分层,先把数据与为业分开,再把业务代码和共通代码分开。数据层对我们系统来说就是规则,系统使用的共通代码都封装到了框架层,而系统功能业务共通的部分,以插件为机能单位分开并建立联系。数据是面象用户的,框架是面向插件开发者的, 插件的实现就是机能担当要做的事情,不同的插件组合相对便捷的生成新机能,也是插件便利的益处与存在的意义。
因为管道中的插件是会被顺序调用的,因此插件模板中的init和action函数也会被正常的回调,而这些回调函数在被调用时,管道系统会把流数据push给单元插件,而接到数据流的插件在接到回调push过来的数据后,进行相应的判断筛选,将编辑后的数据通过sink插槽push给后面的插件,直到管道尾端的插件报警或是记日志,一次管道启动运行的时序就结束了。
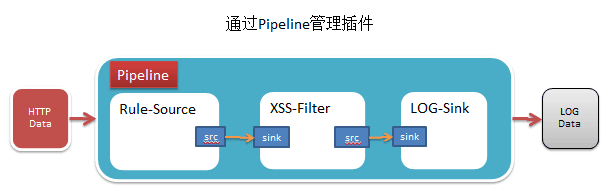
这是一个稍微图型化的pipeline示意图:
我们用代码说明管道的实现更直观,代码如下:
local pipeline = require "pipeline"
local status = pipeline:new {
require"plugin.source_plugin",
require"plugin.filter_plugin",
}
return pipeline字符型式的管道图示:
+------------------+ +----------------+
| source-plugin | | filter-plugin |
src - sink src
+------------------+ +-----------------+
我们通过LUA特有的类组织方式构建了一个顺序的管道数据结构,管道中的插件是按声明的先后顺序来执行的。pipeline管道程序的主要逻辑就是管理回调函数的调用,代码如下:
local Pipeline = {}
local Pobj = {}
function Pipeline.output(self, list, flg)
if flg == 0 then
return
end
for k,v in pairs(list) do
print(k,v)
end
end
function Pipeline.new(self, elements)
self.element_list = elements
self:output(elements, 0)
return PObj
end
function Pipeline.run(self, pcapdata)
local src = {
metadata= {
data= pcapdata,
request = {
uri="http://www.candylab.net"
}
}
}
for k,v in pairs(self.element_list) do
v:init()
v:push(src)
local src, sink = v:match(pcapdata)
if type(sink) == "table" then
self:output(sink, 0)
end
src = sink
end
end
return Pipeline插件抽像出了几个特的函数给开发用户,时序是事先设计好的,最主要的数据和回调也明确了,主要是Pipeline.run统一回调了几个模板的函数,init、push、match函数,这样顶层的设计几乎是固定的,之后所有的业务逻辑都在模板了,按这个时序执行,而插件之间的数据传递依靠的就src和sink这个插件。
基于管道插件的设计特点就是之前的插件会把源头的数据推送给后面的插件,如果管道中的数据在之前被编辑过,会体现在后面的插件接受数据后看见变化,具体的实现,代码如下:
local source_plugin = {}
local src = {
args="source args"
}
local sink = {
name = "source_plugin",
ver = "0.1"
}
function source_plugin.output(self, list, flg)
if flg == 0 then
return
end
for k,v in pairs(list) do
print(k,v)
end
end
function source_plugin.push(self, stream)
for k,v in pairs(stream.metadata) do
self.source[k]=v
end
end
function source_plugin.init(self)
self.source = src
self.sink = sink
end
function source_plugin.action(self, stream)
end
function source_plugin.match(self, param)
self.sink[‘found_flg‘]=false
for kn,kv in pairs(self.source) do
self.sink[kn] = kv
end
self.sink[‘metadata‘] = { data=self.source[‘data‘] }
self:action(self.sink)
return self.source, self.sink
end
return source_plugin
source_plugin是一个典型的插件模板,所有被pipeline回调函数都一目了然,但对于插件的使用来说,可以完全不用关心内部细节,只关心一个函数就行了,就action(self, stream)这个函数,能提供的所有数据都已经被保存到stream这个数据结构里了,对监听的所有后期处理都从这里开始。如果创建一个新插件呢?就是复制源文件改一个名就行了,创建了一个filter_plugin的插件,代码如下:
local filter_plugin = {}
local src = {
args="filter args"
}
local sink = {
name = "filter_plugin",
ver = "0.1"
}
function filter_plugin.output(self, list, flg)
if flg == 0 then
return
end
for k,v in pairs(list) do
print(k,v)
end
end
function filter_plugin.push(self, stream)
for k,v in pairs(stream.metadata) do
self.source[k]=v
end
end
function filter_plugin.init(self)
self.source = src
self.sink = sink
end
function filter_plugin.action(self, stream)
io.write(stream.data, "\n")
end
function filter_plugin.match(self, param)
self.sink[‘found_flg‘]=false
for kn,kv in pairs(self.source) do
self.sink[kn] = kv
end
self.sink[‘metadata‘] = { data=self.source[‘data‘] }
self:action(self.sink)
return self.source, self.sink
end
return filter_plugin生成了这个文件,我们在管理里加入这个插件就OK了,代码:
local pipeline = require "pipeline"
local status = pipeline:new {
require"plugin.source_plugin",
require"plugin.filter_plugin",
require"plugin.syslog_plugin",
}
return pipeline管道图示:
+---------------+ +-----------------+ +------------------+
| source-plugin | | filter-plugin | | syslog-plugin |
src - sink src - sink ....
+---------------+ +-----------------+ +------------------+
我们在这个管道图示的后面,看到多了一个syslog-plugin的插件,这个插件追加的功能就是将前面插件处理的流数据,通过syslog协议,将数所存到远端的syslog服务器上,集中到大数据日志中心进行分析展示,这样这个程序就是一个简单的监控代理的模型。下面我们将程序过行起来,看一下执行的效果。
当你取得了流量数据后,理论上我们想干什么,由我们的想象力决定,在实际的应用场景中,我们像不深入一个应用的部分,就想得到这个应用的输入数据,比如这个应用是一个HTTP SEVER,Openrety服务,我们能不能通过启动这个监听程序,来取得对某个nginx服务的用户请求的agent数据呢,其实这个演示程序可以做到,我们构造一个简单的请求。
curl --user-agent "pcap testcase" www.lua.ren
然后我们,启动这个脚本程序:
./watch
我们只是在 flter-plugin这个lua插件中,对action()回调函数,添加了一个简单的处理,就捕获到了User-Agent的信息含有”pcap”的数据。
function filter_plugin.action(self, stream)
io.write(stream.data, "\n")
local flg = string.find(stream.data, "pcap")
if flg then
print("###########[ OK ]#############")
end
end
实际上我们通过把流量数据转发给Lua,让Lua处理更高级的数据检索需求,在实际的工作中,有些应用的访问者会给出非正常的垃圾信息。如果某些应用输入脏数据,直接会造成程序崩溃,程序又不输出日志,这种机制的流量监听就会有应用场景了,比方说,我们进行大量的扫描行为了,会发出一些某些程序之前预料之外的数据,为了还原是具体那条扫描把程序弄挂了,我们就可以灵活的写一个lua插件,捕获脏数据。
这程序只是一个抛砖引玉,我们直接通过C加Lua的方式,灵感来自至Nginx + lua , 就是现在流行的openresty服务器,又可以用到C的高性能,又使用Lua提高了后续处理的灵活性。如果要处理更大流量的单机流量监听,应该后续加入环形buffer 缓存数据,如果直接将日志数据syslog到远端口的syslog服务上,我们就可以使lua开发一个插件,做syslog转发就好,这就是当时考虑使用lua管道设计做这个实验工具的目地。
现在我们做的工作就类似是,让tcpdump支持lua插件扩展。
文中提到的代码,放到了Github上:https://github.com/shengnoah/riff
标签:cap ++i title 技术分享 演示 length wait 开始 python脚本
原文地址:http://www.cnblogs.com/h2zZhou/p/7514176.html