标签:code 能力 依次 历史 主从复制 str scribe 准备 action
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:安斌
导语: 由于信息过载,推荐系统基本成为互联网产品的标配, 如何快速的让自己的产品具有推荐的能力呢?稀缺专业人员投入、用户数据积累、用户冷启动问题等等都是自建推荐系统必须跨越的障碍。本文介绍如何接入腾讯云智能推荐, 快速获得上百人专业算法团队、二十亿+用户画像、几乎覆盖全部网民的推荐系统能力。
本文介绍如何使用豆瓣图书的openAPI抓取图书信息,上报图书信息、用户浏览点击行为到腾讯云智能推荐系统,通过API获取推荐结果。主要的步骤包括:
物料准备;
物料上报;
场景id申请;
获取推荐结果;
用户行为上报;
首先介绍下什么物料, 物料就是我们需要推荐的物品。推荐系统通过物料的属性、用户和场景的属性以及用户的历史行为,生产推荐结果。
为了方便的获取物料属性,这里我们使用douban图书API获取图书的基本信息。Api参考:https://developers.douban.com/wiki/?title=book_v2
其中,重要的信息包括:
isbn13: 可以作为图书物料的唯一标识;
title/author/pubisher: 与图书相关的重要信息;
rating: 用户评分;
tags: 图书的标签;
price: 价格

接下来, 我们购买主机和CDB,使用python脚本遍历豆瓣图书api,我们将感兴趣的属性记录到db中, 获得原始的物料库,如下表所示:
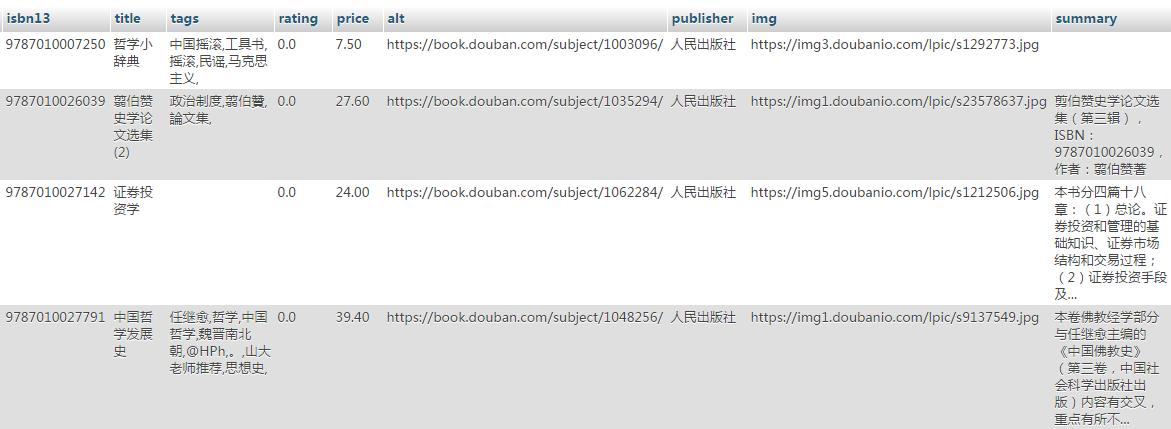
步骤1我们已经获取到了物料库, 接下来通过腾讯云智能推荐item上报API上报物料,API详情参考API文档。
物料上报协议中, 重要的字段包括:
item_id:物料唯一标识, 推荐结果将返回物料id, 暂时不支持中文; 图书推荐使用图书的唯一标号isbn13作为item_id;
pool_id: 自定义物料池, 物料池将物料分类,在获取推荐结果时,可以指定在哪个物料池获取推荐结果, 适配不同的产品场景。同一个物品可以属于多个物料池; 本示例中, 所有物品都可以出现在任意场景下, 所以, 物料没有指定物料池, 需要分物料池时, 可以添加物料池分类, 重新上传物料信息。
tags: 物料的标签, 是物品推荐使用的关键属性,可以使用物品的标签描述、分级类目名、品牌等等信息, 越详细的信息, 对推荐结果越有帮助。 同时, 每个物品的描述应该具有可区分性,在给用户推荐时,如果每个物品都具有相同的tag, 那么, 推荐系统将无法通过这个tag,区分出当前用户对每个物品的喜好, 也就没法产生有效的推荐,所以tag的描述尽量准确、具有区分性。本示例中,标签使用douban提供的tags;
物料上报协议如下所示:
{ ‘data_type‘: 1, ‘tags‘: u‘\u9c81\u8fc5,\u4e2d\u56fd\u6587\u5b66....‘, ‘bid‘: ‘b_teg_openrecom_xxxx, ‘describe‘: u ‘\u9c81\u8fc5\u5168\u96c6(2)‘, ‘free‘: 0, ‘item_id‘: u ‘9787020015252‘, ‘MD5‘: ‘8764084918781ab51493eaf43e6d0166‘, ‘url‘: u ‘https://book.douban.com/subject/1002055/‘, ‘publish‘: 1, ‘platform‘: 1, ‘score‘: 9.5, ‘request_id‘: ‘1488358987‘, ‘vender‘: u ‘\u4eba\u6c11\u6587\u5b66\u51fa\u7248\u793e‘, ‘price‘: 31.75 }
智能推荐的所有行为都是围绕场景展开的, 首先上传适合当前场景的物料,接下来, 拉取当前场景下对用户的推荐结果;再上报用户在当前场景的流量、点击、转换等行为数据, 修正推荐结果。 场景可以理解为产品的一个推荐位, 比如很多产品有猜你喜欢的栏目。
可以在腾讯云官网智能推荐控制台创建场景, 获得场景id。 本文规划两个场景: 首页推荐和详情页推荐,申请两个场景id。
物料库上报以后, 就可以通过用户id从物料库中生成推荐结果了。这里使用请求服务接口。注意, 请求服务的地址与物料上报、行为上报地址不同。重要的字段包括:
scene_id: 场景id, 步骤3申请的bid;
pool_id: 物料池编码, 指定在特定的物料池中选择推荐结果; 如果不指定, 默认在全部物料中选择;
cid: 当前页面物料id, 用于详情页获取推荐的场景,cid使用当前物料id。 在本示例中,在详情页场景使用。
推荐结果请求如下所示:
{ ‘scene_id‘: 538659, ‘request_num‘: 50, ‘uid‘: ‘3496892xx‘, ‘request_id‘: ‘1487861252‘, ‘service_type‘: 3, ‘bid‘: ‘b_teg_openrecom_xxxx‘, ‘uid_type‘: ‘0‘, ‘MD5‘: ‘05bae728925ee937e760b06669089c27‘ }
用户行为上报接口, 上报某个时间点、某个场景下、某个用户发生了特定行为。 利用用户行为可以进一步优化推荐结果。 用户行为包括: 曝光、点击、转化、点赞等等; 行为上报时,需要保证事件发生的时间顺序,严格按照先有曝光,点击,再有转化, 否则系统会认为用户点击、转化行为行为无效。重要的字段:
? trace_id: 用户一系列行为的会话id。通过trace_id, 推荐系统可以串联用户行为。 trace_id的生命周期从曝光开始,依次在点击、转化、点赞等行为中传递。 下一次曝光需要生成新的trace_id;
协议如下所示:
{ ‘uid‘: ‘3496892xx‘, ‘data_type‘: 2, ‘bid‘: ‘b_teg_openrecom_xxx‘, ‘item_id‘: u ‘9787109061385‘, ‘scene_id‘: u ‘538659‘, ‘MD5‘: ‘8764084918781ab51493eaf43e6d0166‘, ‘action_time‘: 1487905960, ‘trace_id‘: u ‘1487905944‘, ‘action_type‘: 2, ‘request_id‘: ‘1487905960‘, ‘uid_type‘: ‘0‘ }
标签:code 能力 依次 历史 主从复制 str scribe 准备 action
原文地址:http://www.cnblogs.com/qcloud1001/p/7526695.html