标签:过程 方案 stream bit 新建 nbsp 方式 永久 types
最近在看nodejs的源码,看到stream的实现里面满地都是encoding,不由想起以前看过的一篇文章——在前面的随笔里面有提到过——阮一峰老师的《字符编码笔记:ASCII,Unicode和UTF-8》。
好的文章有一个好处,你每次看都会有新的收获,它就像一款拼图,你每次看都能收获几块碎片,补齐之前的认识;而好文章与拼图不一样的是,好文章是一块无垠的世界,当你不愿局限于当前的眼界的时候,你可以主动走出去,外面要更宽广、更精彩的多。
闲话说到这,开始聊聊所谓的编码。
大家都知道,计算机只认识0和1,不认识什么abc。如果想让计算机显示abc,那么就要有一张1对1的表,用这张表告诉计算机,什么样的二进制串——比如(010101011100)——代表的是a,什么样的串代表的是b,这个表描述二进制串到符号的对应关系。ASCII就是这么一张最早也是最简单的表,这张表简单到包含128个符号,比如10个数字、26个小写字母、26个大写字母,和一堆标点符号(如英文句号、逗号等)还有控制字符(如回车、tab等)。那为什么是128,不是100或182?因为128正好用7个bit(一个0或者1为一个bit)表示。那么为什么不是256对或者更多?因为对于英语地区128个符号够用了,而在ASCII推出的那个年代(1967),大家还没开始着眼全球——这点从名字就可以看出来,ASCII = American Standard Code for Information Interchange(美国信息交换标准码),根本就没打算让别人上车。
然后其他语言地区很快入场了,而且随着八位机的普及,1字节=8bit成为了共识,大家都盯上了多出来的128个位置。这个时代群魔乱舞,基本是个公司就想染指这块标准,乱象直到1985年才通过ISO/IEC 8859把EASCII确定下来。
而在这个过程中,有一个地区的人根本就不跟你玩,就是意表文字地区,明白的说,主要是中日韩。开玩笑,256个位置,你全让出来都不够我做两句诗。老司机不带怎么办,只能自己开车了,首先是日本站出来,于1978年出台了最早的汉字编码,然后中国大陆、中国台湾、韩国都在80年代出台了自己的汉字编码。这个时候,大家各自玩各自的没什么问题,聚在一起,问题就来了。比如一篇文章中包含中日韩三种文字,一串01的组合在中国的编码对应的是某个字,在日本的编码对应的却是另一个字,那计算机最后到底显示哪个字,计算机也很为难。有冲突怎么办,开个会通通气吧,于是大家坐在一起成立了个组织,叫CJK-JRG(China, Japan, Korea Joint Research Group)。虽然这个组织折腾了很多年,而且最终提案也被否决了,但是为另一个方案提供了足够的信息,就是Unicode。
Unicode项目于1987年启动,在吸收了CJK-JRG的方案后于1992年6月份发布1.0.1版(之前的1.0.0没有包含汉字),迄今为止还在增修,最新的版本是2017.6.20公布的10.0.0。最早的Unicode被设计为16bit,即每个符号占2byte,最多表示65536个符号。而后随着内容的增加,又基于原有设计不变的原则,将最早的65536个字符集合称为基本多文种平面(Basic Multilingual Plane, BMP),并添加16个辅助平面(总共支持65536 * 17 = 1114112个符号)。这样一来,原来的16bit就不够用了,需要21bit才能准确描述一个符号,相当于3byte不到,但是为了以后扩展方便及统一,辅助平面的符号要求使用4byte描述。
Unicode解决了全世界人民用一套符号编码的问题,但却没有解决另一个问题,就是怎么存储的问题。按照一般的想法,所有的符号都必须以最长的Unicode符号的标准来存储,也就是4byte,这样才不会有信息丢失。但是这样的话,对于全部是英文的文档,要浪费掉3/4的区域,对于大多数汉字,即BMP中的汉字,也要浪费掉1/2的区域。所以野蛮的使用4byte进行存储是不可取的,那么就要设计一套变长的规则来处理不同类型的符号,这时候UTF8、UTF16等就应运而生了,也就是说UTF8、UTF16是Unicode的一种实现方案(标准的说法,是Unicode字符编码五层模型的第三层,如果你对五层模型感兴趣,跳转《刨根究底字符编码》)。
先说UTF8,UTF8是完全变长的,占用1-6byte,乍一看,怎么比直接用4byte存储还多出一半呢?其实占用4byte的情况是很少的,少到在几乎可以忽略不计,而5、6byte基于当前16个辅助平面的情况下还用不上。一般来说,英文占用1byte,中文占用3byte(CJK-JRG最早提供给Unicode的20000多个符号位于位于U+4E00–U+9FFF,这块区域的符号统一都占3byte),所以一般来说使用UTF8可以节省1/4到3/4的存储区域。这样似乎解决了存储的问题,但却带来了另一个问题,即识别的问题。比如我给你3byte的二进制信息,告诉你这代表了一个字,那你肯定很快能知道是什么字,但我如果不告诉你字数呢,是一个字,两个字,还是三个字?你根本识别不出来这一串二进制是什么。这就是变长的方案需要解决的第二个问题,告诉读取方哪几个byte是一组的,UTF8的规则很简单,我直接从阮老师的博客里搬运过来。
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。 2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
| Unicode符号范围 | UTF-8编码方式 |
| (十六进制) | (二进制) |
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-001F FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0020 0000-03FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0400 0000-7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
简单的说,你收到很多个byte的二进制,从第一个byte开始读,数第一个0出现之前的1,有几个1就代表前面几个byte是一组的,0个1就代表当前的这个byte孤家寡人一个。然后跳过这个组的所有byte,继续之前数1的环节。分好组后,按组找到上表右边的规则,把规则内x的位置保留下来,01的位置全部扔掉(01代表的位置是UTF8的元数据,x代表的位置才是Unicode的数据),拼成新的二进制串,这个串就是Unicode了。举个栗子:
11100110 10001000 10010001 11100110 10011000 10101111 01110100 01100001 01110010 01101111 01101100
以上有11个byte,我们从第一个byte11100110开始,数第一个0前面的1的数量,有3个1,代表3个byte是一组的。然后我们跳过这3个,第四个byte是11100110,继续数1得出有3个1,然后又给这3个byte分组。跳过这三个,到了第7个byte,这往后的5个byte都是以0开头,说明每个byte为1组。现在我们分好组了,有7个组,分别是
[11100110, 10001000, 10010001], [11100110, 10011000, 10101111], [01110100], [01100001], [01110010], [01101111], [01101100]
现在我们按组找到表右对应的行,第一组、第二组对应第五行,其他组对应第三行,我们把行内x对应的位置保留,10的位置删除,得到新的数组
[0110, 001000, 010001], [0110, 011000, 101111], [1110100], [1100001], [1110010], [1101111], [1101100]
然后把组内的二进制串起来得到Unicode
[0110001000010001], [0110011000101111], [1110100], [1110100], [1100001], [1110010], [1101111], [1101100]
这时候我们再按byte进行拆分以便阅读,并且在高位补0
[01100010 00010001], [01100110 00101111], [01110100], [01110100], [01100001], [01110010], [01101111], [01101100]
再转换成16进制
[62 11], [66 2F], [74], [61], [72], [6F], [6C]
这时候我们打开F12,在控制台输入对应的Unicode(语法要求必须使用4位16进制数字)
‘\u6211\u662f\u0074\u0061\u0072\u006f\u006c‘
得到了对应的字符串“我是tarol”。
好了,以上是UTF8的内容,之所以叫UTF8是因为这个规则下的符号,最少占8bit。那么UTF16就好理解了,在这个规则下,每个符号最少占16bit。UTF16的规则说起来更简单,当符号位于BMP中时,占用2byte,在符号位于辅助平面时,占用4byte。那既然是变长的,又碰到了上面的问题,怎么识别这一块是4byte为一组还是2byte为一组?
这里就要提到Unicode的保留区块了,Unicode规定从U+D800到U+DFFF之间是永久保留不赋予任何符号的。也就是正常情况下,2byte如果落在这个范围内,那么就是Unicode的非法字节。而UTF16的做法就是把辅助平面的Unicode码进行处理,变成4个字节,并且两两落在非法区域内,读取方读到了非法字节,就可以界定这里是4byte为一组,不然就是2byte为一组。那么UTF16这个转换的算法又是怎样的呢?
还是举个例子。
??,这个字是个异体字,通“碎”,位于辅助平面,Unicode码位是U+24B62,我们来算一下它的UTF16编码结果
然后我们验证一下答案,照常打开控制台,键入‘??‘.charCodeAt(0).toString(16)得到’d852‘,键入‘??‘.charCodeAt(1).toString(16)得到’df62‘,验证成功!而且这里还透露了一个细节,ES规定string是经过UTF16编码的(ES5标准文档)。
UTF16的事还没完,如果用过nodejs里面的string_decoder接口的人肯定注意到了,其中对UTF16编码的支持叫utf16le,这个le是什么?其实这个是Little Endian的简称,对应的是Big Endian。我们之前举的例子就是Big Endian,Little Endian不同在于每个2byte组里面的顺序是反过来的,即上面的0xD852和0xDF62改成0x52D8和0x62DF就是??的utf16le编码了。至于为什么会有这么蛋疼的区分,那是操作系统的遗留问题,就像window的CRLF和unix的LF一样。
UTF16告一段落了,新问题又来了。我们有UTF8、UTF16LE、UTF16BE这么多种编码,那一串二进制流过来我们用哪种编码方式去解析呢?尤其是UTF16LE和UTF16BE,它们大部分规则是一样的,只是反过来了罢了。这里就要提到文件的一个元数据叫BOM(byte-order mark)了,BOM位于文件二进制流的最前方,标识当前文件的编码格式。UTF16LE的BOM为FF FE,UTF16BE的BOM为FE FF,UTF8的BOM为EF BB BF,但是一般不建议UTF8文件带BOM。举个栗子,如果文件内容只有’0‘(十六进制编码为30),那么三种编码方式生成的文件的十六进制编码分别为
| 编码 | 十六进制内容 |
| UTF8 |
EF BB BF 30
|
| UTF16BE |
FE FF 00 30
|
| UTF16LE | FF FE 00 30 |
从上面的例子也可以看到,UTF16最大的问题在于:哪怕是ASCII标准字符0,也占用了2byte。这不仅仅浪费了存储空间,关键在于UTF16和ASCII不兼容,比如我新建一个文件,内容为1234567890,使用系统自带的记事本打开,再另存为Unicode编码(就是UTF16LE)
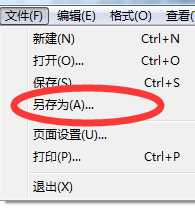

然后再选择打开,选择当前文件,再ANSI编码
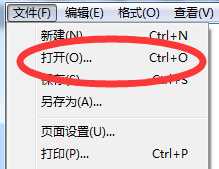
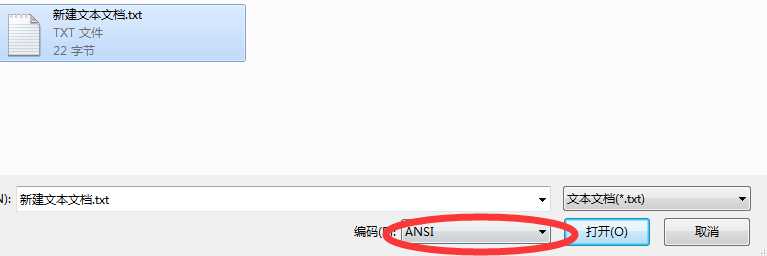
你会看到这个样子的内容
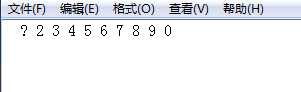
可以发现,不仅信息错乱了,每个数字之间还有空格。
本来这篇文章到此就结束了,直到我在nodepad++里面看到了这个

UCS-2是什么鬼,好像在哪里见过?瞬间脑子里像侦探回忆线索般闪过画面,后来整理发现这就是UTF16的low版。为什么说是low版,因为USC-2是定长的,是不支持辅助平面的UTF16。我们验证下,把‘??’复制到用notepad++打开的以UCS-2编码的文件里,没看出有什么问题,这时候关闭notepad++再打开。
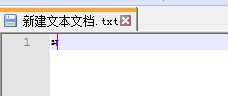
可以看到,‘??’字碎的只剩渣了。
所谓编码--泛谈ASCII、Unicode、UTF8、UTF16、UCS-2等编码格式
标签:过程 方案 stream bit 新建 nbsp 方式 永久 types
原文地址:http://www.cnblogs.com/tarol/p/7523642.html