标签:解决 abi 高度 特定 common alt 建立 大型 中心
论文地址:Video2GIF: Automatic Generation of Animated GIFs from Video
视频的结构化分析是视频理解相关工作的关键。虽然本文是生成gif图,但是其中对场景RankNet思想值得研究。
文中的视频特征表示也是一个视频处理值得学习的点。以前做的视频都是基于单frame,没有考虑到时空域,文中的参考文献也值得研读一下。
以下是对本文的研读,英语水平有限,有些点不知道用汉语怎么解释,直接用的英语应该更容易理解一些。
从源视频当中提取GIF小片段,在大规模数据集检测中,该方法取得了state-of-the-art。
gif介绍
Animated GIF is an image format that continuously displays multiple frames in a loop, with no sound.
提出了RankNet来处理给一个视频,得出一个片段排列。
1首先用3D convolutional neural networks去represent每个视频。
2然后用排名算法训练去比较一对输入中那个更适合作为gif图。然后用排名算法训练去比较一对输入中那个更适合作为gif图。
3为了增强鲁棒性,在排序中设计一个robust adaptive Huber loss function。
4最后,为了解决用户生成内容的不同程度的质量问题,我们的损失考虑到流行度量进行编码社会媒体上的GIF的影响。
数据集
收集了超过100K用户生成动画GIF与其对应的来自在线来源的视频源。有数百个成千上万的GIF在线可用,许多提供了链接到视频源。
使用这个数据集训练我们的深层神经网络比较超过500KGIF和非GIF对。实验结果表明我们的模型成功地学习了什么内容是适合的GIF,我们的模型很好地推广到其他任务,即视频highlight detection。
三点贡献
1提出了解决自动生成gif任务的方法。
2提出了Robust Deep RankNet with a novel adaptive Huber loss in the ranking formulation
3收集超过100k的用户生成的gif及原视频数据集。
整个流程如图:
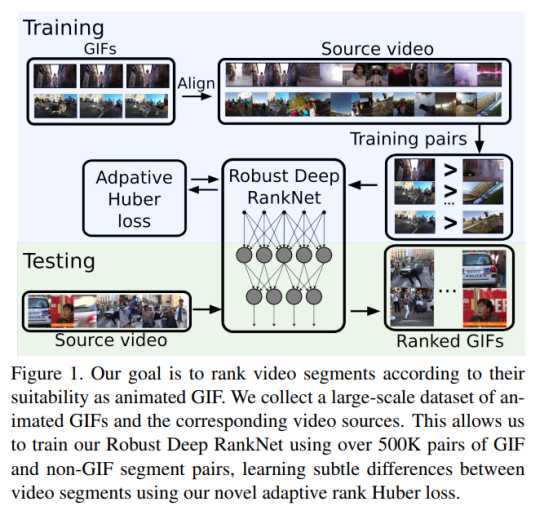
1美学和趣味性aesthetics and interestingness
趣味性方面 Fu et al. [7] propose anapproach accounting for this, by learning a ranking modeland removing outliers in a joint formulation.
提出通过学习排名模型来解决这个问题并以联合方式取消异常值。
Khosla等人[20]分析图像流行度的相关属性。运用大量的Flickr图像数据集,他们分析和预测什么类型的图像比其他图像更受欢迎,表面趋势类似于有趣的趋势[11]。
在类似的方向是Redi等人的工作[31],分析创造力。然而,不是分析图像,他们专注于视频,其长度受限于6秒。
2视频摘要Video summarization
[37]有详细的介绍,这里只讨论图像先验和监督学习方法。
使用网络图像的先验是基于的观察特定主题或查询的网络图像通常是规范的主题的视觉示例。这样就可以进行计算
帧分数作为帧与一组其他帧之间的相似性网页图像[21,20,33]。
基于学习的方法,使用监督模型来获得对于帧[25,8,27]或段[13]评分功能。
3视频亮点 Video highlights
亮点的定义既是主观的和上下文相关[37]。举例人物特写,体育罚球等。
Sun et al. [35]and Potapov et al. [30]提出了更一般的方法。基于针对特定主题(例如冲浪)的注释视频,他们使用机器学习方法中通用特征来预测两点。为了训练手工大量标记视频注释,进行动作识别。
获取大型视频突出显示数据集很困难。 因此,Yang et al。 [40]提出了一种无监督的方法来寻找亮点。 依靠一个假设事件类别的亮点在短视频中比非亮点更频繁地捕获,他们训练自动编码器。
4学习使用深层神经网络进行排名 Learning to rank with deep neural networks
一些工作使用CNN从排名标签中学习。损失函数通常用pairs 配对[27,9]或三联体triplets [38,39,14,23]。 成对方法通常使用一个CNN,而损失是相对定义的输出。 Gong et al。 学习网络预测图像标签,并要求得分正确的标签要高于不正确标签的分数。 Triplet方法,使用Siamese 网络。特定一个图像triple (查询,正,负),一个损失函数需要查询图像的学习表示更接近正面的,而不是负面的形象,根据一些度量[38,39,14,23]。
5噪声标签的有监督深度学习
几个以前工作已经成功地从弱势学习了模型标签[18,38,27]。 Liu et al。 [27]考虑视频搜索
场景。 给定Bing的点击数据,他们学习联合嵌入查询文本和视频缩略图以查找语义相关的视频帧。相比之下,[18,38]使用通过自动获得的标签训练神经网络的方法。Karpathy等训练用于动作分类的卷积神经网络视频。他们的培训数据来自YouTube通过分析相关的元数据自动标记与视频。王等人 [38]学习特征表示对于细粒度的图像排名。基于现有的图像功能他们生成用于训练的标签神经网络。 这两种方法都获得了最先进的技术表现,显示出强大的弱标签数据集与深度学习相结合。
受到近期成功应用与深层学习结合使用的大量弱标签数据集的启发,我们收集了具有嘈杂,人为生成注释的社交媒体数据。
将GIF与源视频对齐是至关重要的,因为它可以让我们找到非选择的片段,这些细分作为训练的负面样本。 此外,视频提供更高的帧速率和更少的压缩伪影,是获得高质量特征表征的理想选择。
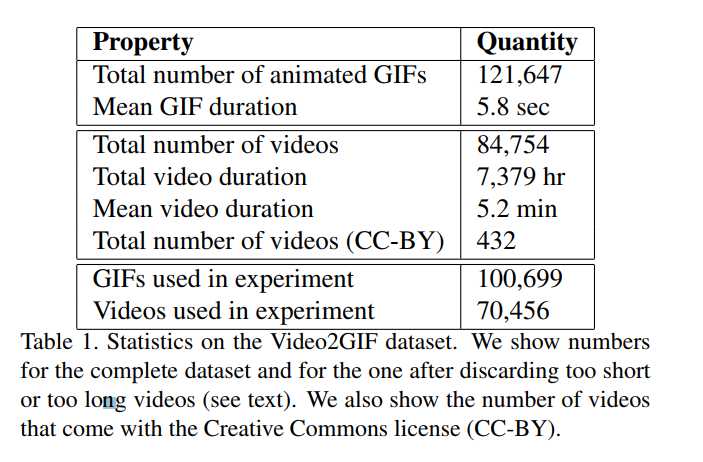
数据库包含120K animated GIFs and more than80K videos, with a total duration of 7,379 hours.
Alignment对准
我们将GIF与对应的对齐视频使用帧匹配。为了有效地做到这一点,我们基于 perceptual hash感知散列对每个帧进行编码discrete cosine transform 离散余弦变换[41]。
感知散列perceptual hash是快速计算的,并且由于其二进制表示,可以是使用汉明距离Hamming distance非常有效地匹配。 我们将GIF帧的集合与其对应视频的帧进行匹配。 这种方法需要O(nk)距离计算,其中n,k分别是视频和GIF中的帧数。 由于GIF的长度受限制并且具有较低的帧速率,因此它们通常仅包含几帧(k <50)。 因此,该方法在计算上保持有效,同时允许对准准确。
因为这个方法想要建立的是数据库,那么结果准确度是十分重要的。在之前的工作中,其他方法都是用一个大团块blocks of 50
frames,比如50帧一起检测,结果会比较粗糙,并不适用于当前这种情况。
Dataset Analysis.数据集分析
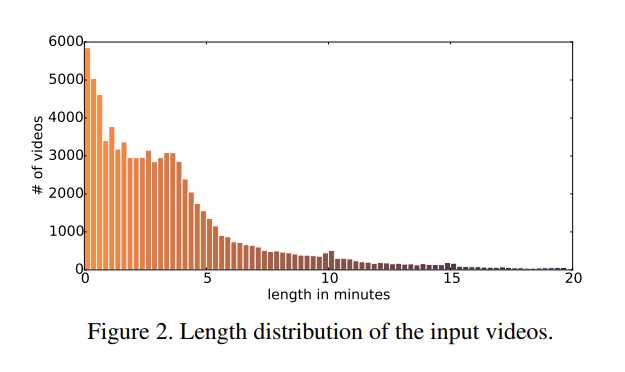
我们分析什么类型的视频经常用于创建动画GIF。 图3显示最多我们的数据集中的视频频繁标签,图4显示视频的类别分布。 几个标签给了感觉视频中存在什么,这可能是潜在的帮助GIF创建,例如 可爱和足球。 其他的不是视觉信息,例如2014或YouTube。 图2显示视频长度的直方图(中位数:2m51s,平均值:5m12s)。 可以看出,大多数源视频都很短,中位持续时间少于3分钟。


Splits.拆分
training and validation sets about 65K and5K videos
test set 357 videos Creative Commons licence 表1显示了我们使用的数据集的统计信息。
本节介绍了我们对Video2GIF任务的方法,在排名配方中引入了一种新颖的适应性Huber损失,使得学习过程对异常值更robust鲁棒; 我们称之为鲁棒深度网络。
4.1. Video Processing
将一段长视频,切割成小片段 采用boundary detection algorithm Song et al. [33]
结果的重合度达到66%以上,就认定为是正例。没有任何重合overlap的最为负例。
4.2. Robust Deep RankNet
Architecture overview 结构总览 图五所示。
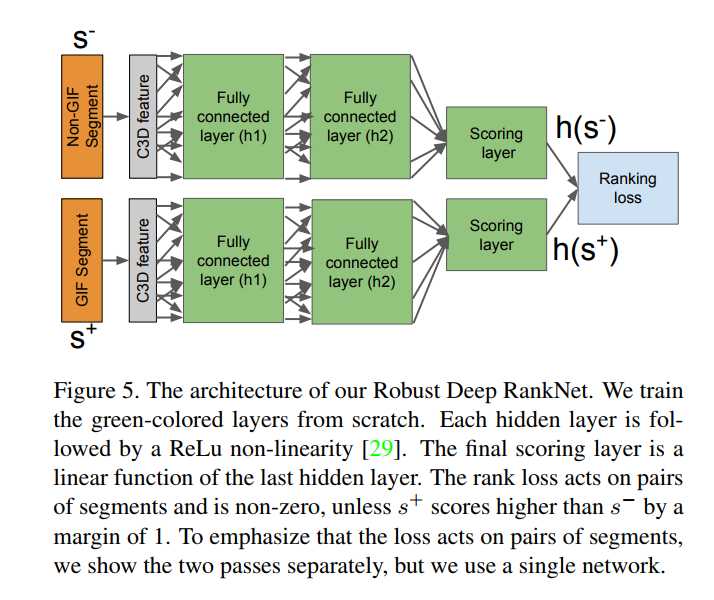
训练过程中输入是GIFand non-GIF segments
模型学习一个maps a segment s to its GIF-suitability score h(s)
学习一个函数,通过比较训练的片段对,然后GIF segment gets a higher score than a nonGIFsegment
测试阶段,采用带个segment输入,计算GIF-suitability score,然后计算出所有视频所有片段的得分,产生segments排名列表,选适合的作为动画gif。
Feature representation 特征表征
动画GIF包含高度动态视觉内容,特征表示至关重要。捕捉视频段的空间和时间动态,我们使用在Sport-1M数据集[18]上预先训练的C3D [36]作为我们的特征提取器。
C3D通过用时空卷积层代替传统的2D卷积层,将AlexNet [22]的图像中心网络架构扩展到视频域,并已被证明在多个视频分类任务上表现良好[36]。 以前的方法使用类别具体模型[35,30],我们可以选择为段表示添加上下文功能。 这些可以被认为是元信息,补充视觉特征。 他们有可能消除细分排名的歧义,并允许模型根据视频的语义类别进行分数。 特征包括类别标签,视频标签的语义嵌入(在word2vec表示[28]上的意义))和位置特征。 对于位置特征,我们使用片段在视频中的时间戳,秩和相对位置。
Problem formulation 问题公式
简单的方式是可以把这个问题归结为分类问题,但是不能完美的解决这个问题,因为因为那里对于什么是好的或坏的细分没有明确的定义。
所以把这问题确定为排序问题。在数据集D上构建一个排序,是正样本得分排名大于负样本。
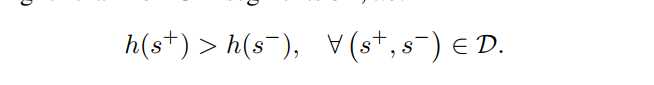
这个公式比较是两个片段,即使它们来自不同的视频。 这是有问题的,因为两个片段的比较仅在视频的上下文中是有意义的,例如,一个视频中的GIF片段可能不被选择为另一个视频中的GIF。 为了看到这一点,一些视频包含许多感兴趣的部分(例如,编译),而在其他视频中,甚至所选择的部分质量低。 这个概念因此,GIF的适用性在单个视频的上下文中是非常有意义的。
为了解决这个问题,我们将排名计算公式指定为特定视频。在同一视频中gif的正样本排名大于负样本。
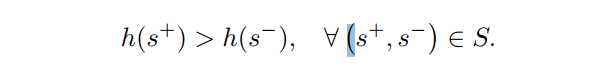
Loss function. 损失函数
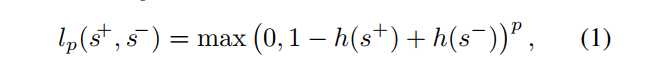
其中p = 1 [17]和p = 2 [35,24]是最受欢迎的选择。 lp损失强制排名约束,要求一个积极的分数比其负面对手的得分高于1.如果边界被违反,损失的损失在l1损失的误差中是线性的,而对于l2的损失 是二次的。 l2损失的一个缺点是相对于l2损失来说,是过度惩罚小额违约。 l2损失没有这样的问题,但是它会对边际违规进行二次惩罚,因此受到异常值的影响更大(见图6)。
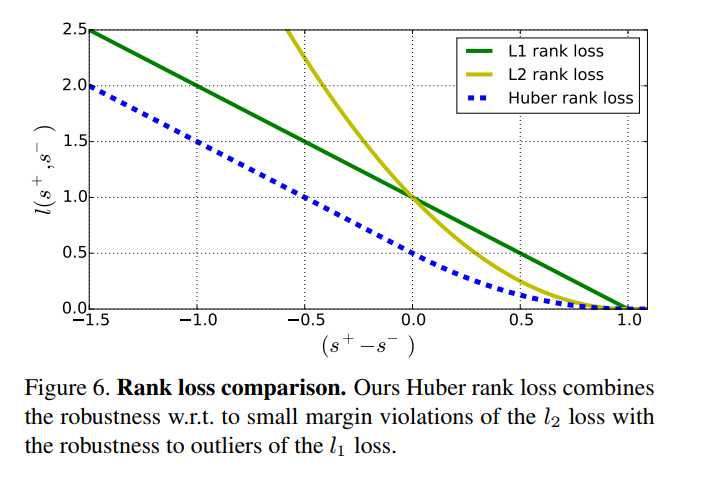
因为数据包含线上制作的,有的质量低,所以提出了robust rank loss,来适应Huber loss formulation。对边界违反小的样本给更低的惩罚。公式如2.图6中定义了三种不同形式的函数。
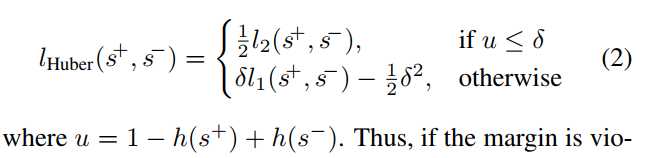
Objective function.目标函数
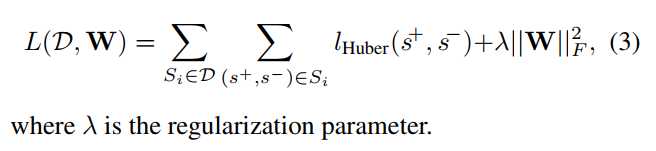
4.3. Implementation Details 实现细节
选择了2个全连接隐层,每个层后面RELU。第一层512个节点,第二层128个节点。输出h(s)的最终预测层是一个简单的单线性单位,预测非标准化标量得分。
网络共2,327,681个参数。
反向传播采用[32]采用mini-batch stochastic gradient descent。mini-batches=50 pairs
采用Nesterov’s Accelerated Momentum [2]加速权重更新。
momentum is set to 0.9
weight decay λ =0.001
learning rate = 0.001 10个epoch减少一次
应用dropout [34] regularization input =0.8 after the first hidden layer=0.25
用500k个训练集对,每个视频中所有的正样本和视频中随机抽取4个负样本并把负样本结合。对于具有固定δ的Huber损失,我们根据验证集的性能设置δ= 1.5。 对于自适应Huber损失,我们设置δ= 1.5 + p,其中p是在[20]中提出的归一化视图计数。为了进一步减少我们的模型的方差,我们使用模型平均,其中我们从不同的初始化训练多个模型, 平均预测分数。 模型使用Theano [3]与Lasagne [6]进行实施。
Evaluation metrics.
在video highlight detection中流行的评价指标是mean Average Precision(mAP)和p
因为上述方法对视频长度敏感,本文使用的normalized version of MSD。
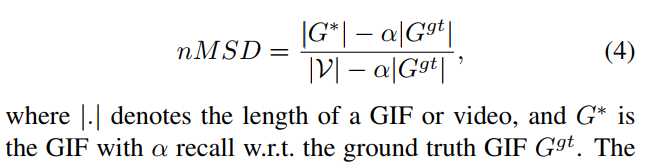
5.1. Compared Methods
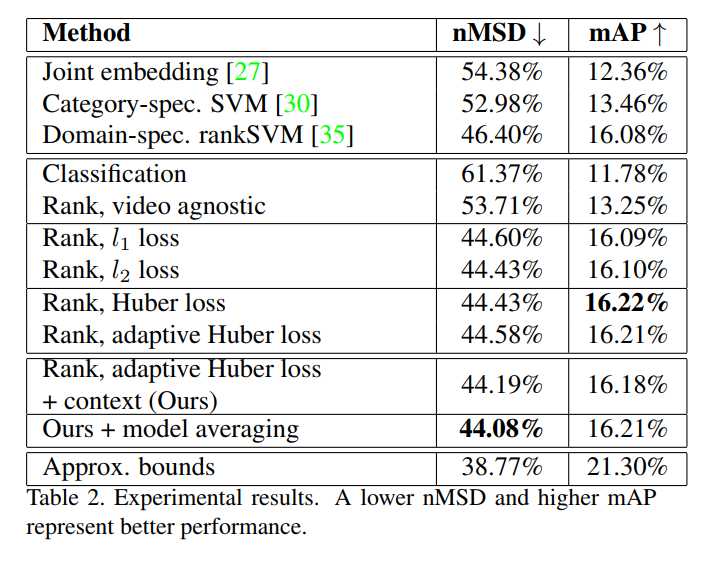
5.2. Results and Discussions

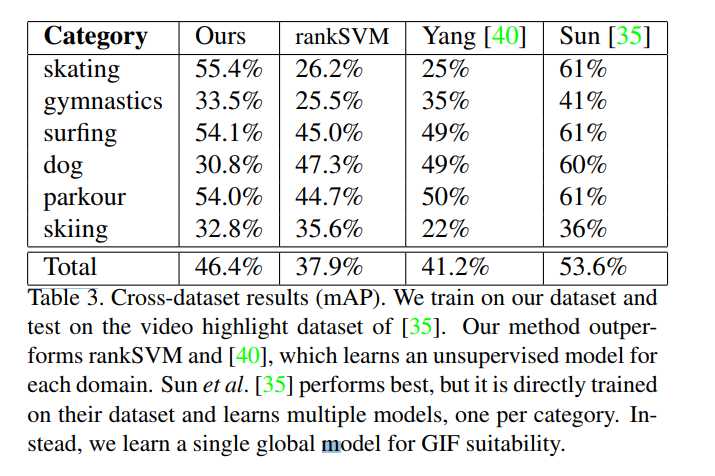
5.3. Cross Dataset Performance
我们介绍了从视频自动生成动画GIF的问题,并提出了一个强大的Deep RankNet,它预测了适合的GIF视频片段。
我们的方法利用新的自适应Huber等级丢失来处理嘈杂的网络数据,该优点具有对异常值的鲁棒,并能够将内容质量的概念直接编码到损失中。
在我们新的动画GIF数据集我们展示了我们的方法成功地学习了细微差异的分级,优于现有的方法。
此外,它概括了很好的亮点检测。我们的新颖的Video2GIF任务,以及我们的新的大型数据集,为未来的研究开辟了自动GIF创建方向。
例如,可以应用更复杂的语言模型来利用视频元数据,因为并不是所有的标签都是信息丰富的。因此,我们认为学习专门用于视频标签的嵌入可以改善语境模型(我认为就是利用视频元数据可以向NLP中word2vec那样来处理)。
虽然这项工作集中在获得有意义的GIF排名,但我们只考虑了单一片段。由于一些GIF范围超过多个镜头,因此看看何时组合片段甚至连合分割和选择也将是有趣的。
Automatic Generation of Animated GIFs from Video论文研读及实现
标签:解决 abi 高度 特定 common alt 建立 大型 中心
原文地址:http://www.cnblogs.com/vincentqliu/p/7529240.html