标签:style blog http io 使用 ar strong 数据 2014
一、消失的概念与新鲜的名词
Hadoop V2相对于Hadoop V1的变化主要在于资源管理和任务调度,计算模型仍然保持map/reduce的模型。资源管理和任务调度的变化导致了工作流程的变化,一些概念消失而一些概念又出现。
1、JobTrack与TaskTrack
JobTrack和TaskTrack在Hadoop旧版本(Hadoop0.x及Hadoop1.x)中是非常重要的概念。JobTrack对系统中的所有Job进行统一的管理,同时为Job分配相应的TaskTrack,还需要与所有的TaskTack通信以更新Job的任务进度和运行状况。JobTrack只有一个,尽管Hadoop V1为了降低其容错率,增加了备份JobTrack,但是其单点容错率所造成的瓶颈仍旧是不可避免的。TaskTrack运行本地任务和利用本地资源,向JobTrack报告任务状态并执行JobTrack指令。TaskTrack将任务的执行硬性划分为Map task splot和Reduce Task splot,在资源利用和任务执行上都降低了效率。
JobTrack和TaskTrack的体系是Hadoop V1的鲜明特征,但是其缺点也随着Hadoop集群的Job数量的增加而越来越明显。并且,这种体系要求系统在更新时需要更新每一个JobClient的TaskTrack,而后又需要用户来测试新的系统是否支持原来的程序,系统维护难度增大。因此,在Hadoop V2中,JobTrack和TaskTrack的概念就消失了。
2、资源管理器ResourceManager、应用主体ApplicationMaster和节点管理器NodeManager
Hadoop V2将JobTrack的功能进行了拆分,从而降低其单点容错性,由此出现了资源管理器和应用主体。同时,将TaskTrack所在的JobClient的功能增强,出现了节点管理器,并且通过应用主体来链接到资源管理器。
资源管理器对集群全局的资源进行管理,并且Hadoop V2的资源管理与Hadoop V1的资源又有所区别,主要在于Hadoop V2将内存作为了资源管理单元——资源容器——的核心因素之一。资源管理器分为调度器和应用管理器,调度器主要负责任务资源的分配和任务的调度,而应用管理器负责与应用主体进行通信,获取节点的信息并通知给调度器作为参考。
应用主体伴随着应用而生,每一个应用都有一个应用主体。应用主体存在于节点上,与节点管理器相互协助对节点上的任务和资源进行管理。应用主体统一与应用管理器通信,但是并不是受应用管理器的管理,应用管理器只负责启动应用主体并管理其生命周期(与相应的节点管理器通信来启动应用主体)。如果一个应用的资源容器存在于不同的节点上,其应用主体还需要与其他节点上的节点管理器通信来获取相应资源容器的信息。
节点管理器是节点上的框架管理器,获取整个节点上的资源容器状况,与调度器通信来使用资源容器,与应用管理器通信来启动应用主体。
二、Hadoop V2工作流程
前一篇随笔已经结合源码详细的分析了Hadoop V1的工作流程,在Hadoop V2中工作流程与之有所不同,信息流主要在资源管理器(包括应用管理器和调度器)、应用主体、节点管理器和资源容器之间流动。
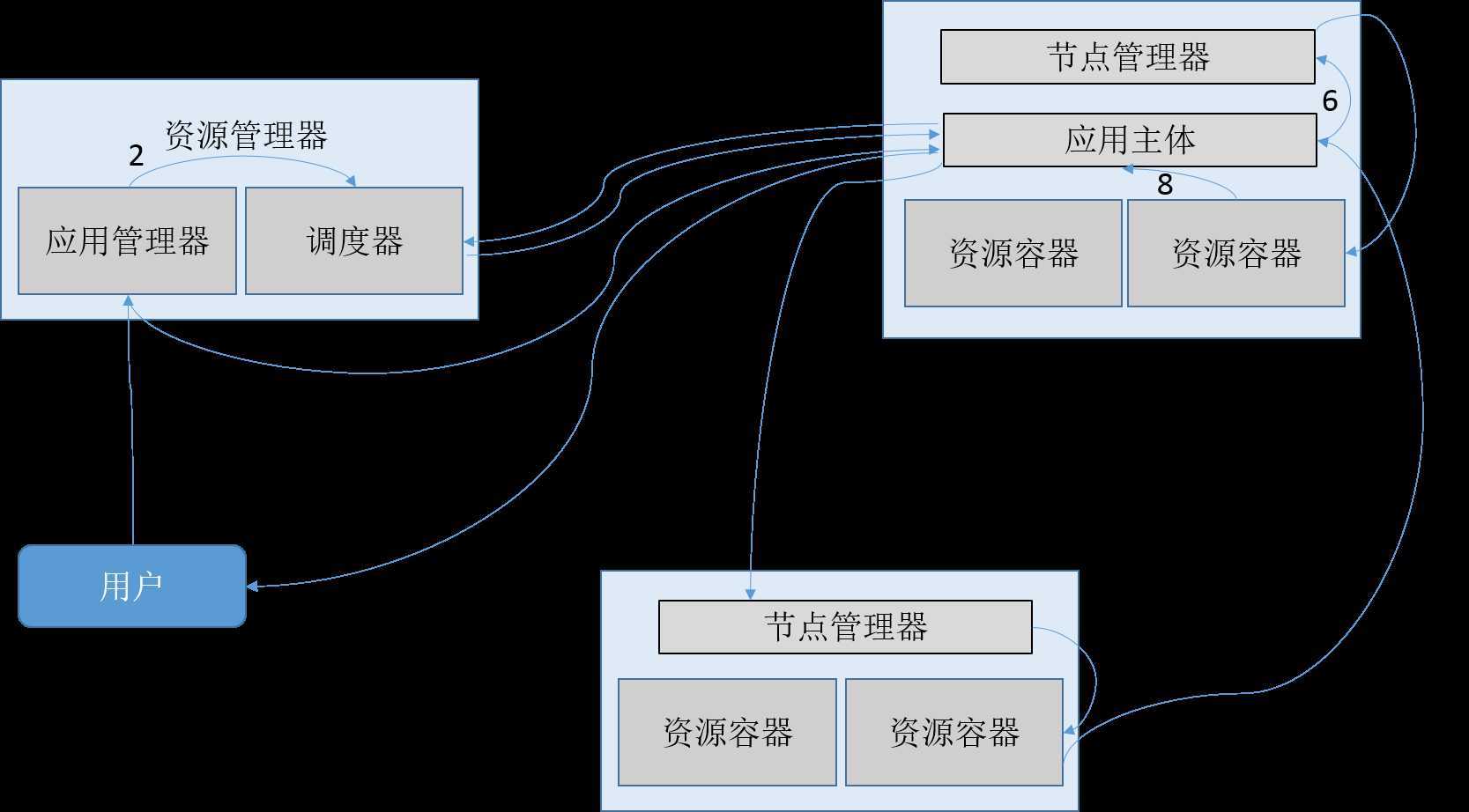
图中每一步的具体功能如下:
1:用户提交任务给资源管理器中的应用管理器,首先会由框架给此任务分配一个任务ID,然后写入HDFS用户应用缓存,再提交该应用给应用管理器。
2:应用管理器与调度器协调获取该应用的应用主体所需要的资源容器
3:由应用管理器启动节点管理器上的应用主体
4:应用主体计算自身所需的资源容器数量并通知调度器
5:调度器根据应用主体的申请和自身的资源统计,为应用主体分配适当的资源容器
6:应用主体与资源容器所在的节点管理器通信,获取资源容器的使用权
7:节点管理器查询自身资源容器的使用情况,启动相应的资源容器来执行任务
8:被确定分配给应用主体的资源容器实时与应用主体通信,报告任务进度和状态
9:应用主体将作业的执行状态反馈给用户
三、容错机制
Hadoop V1的容错机制比较简单,即通过冗余副本解决节点宕机或随机错误。datanode上的任务块在本地存储空间和其他datanode中均存在一份副本,这样可以在任务失败或节点宕机的情况下可以重新运行或由其他节点重新启动任务。而namenode出现问题将是非常严重的错误,只能进行任务的重新运行。
Hadoop V2的容错机制比较完善,是利用log来解决的。应用管理器是记录log的部件,它会在监督任务的Map和Reduce操作的同时记录log,标明已经完成的Map和Reduce任务,因此在节点宕机或者任务出错时只需根据log启动未完成的Map任务和Reduce任务即可。如果资源管理器出现问题,会根据ZooKeeper保存的资源管理器状态进行自我恢复。由于任务运行时主要由应用主体进行监督,所以对资源管理器的依赖度有所减小。
Spark的容错机制与Hadoop V2的有一点类似:RDDs使用lineage来恢复出现问题的RDD,而lineage的作用就是记录粗粒度的数据转换操作,这可以为RDD的恢复提供完整的数据。
Hadoop随笔(二):Hadoop V1到Hadoop V2的主要变化
标签:style blog http io 使用 ar strong 数据 2014
原文地址:http://www.cnblogs.com/zx247549135/p/3955742.html