标签:src block size ret 第一个 hash 分享 vol 可重入锁
一.适应ConcurrentHashMap的原因
HashMap存在线程不安全的问题,HashTable效率十分低下,因此,ConcurrentHashMap有了合适的登场机会。
(1)HashTable的线程不安全性
在并发编程环境中,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发回见下不能够使用HashMap.
如下代码所示:
1 final HashMap<String, String> map=new HashMap<String,String>(2); 2 Thread t=new Thread(new Runnable(){ 3 @Override 4 public void run(){ 5 for(int i=0;i<1000;i++){ 6 new Thread(new Runnable(){ 7 @Override 8 public void run(){ 9 map.put(UUID.randomUUID().toString(),""); 10 } 11 },"ftf"+i).start(); 12 } 13 } 14 },"ftf"); 15 t.start(); 16 t.join();
HashMap在并发执行put时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环型数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死虚幻获取Entry.关于产生死循环的原因这里不再赘述。
(2)效率低下的HashTable
HashTable容器使用synchronized来保证线程安全,但是在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也在访问HashTable的同步方法时,会进入阻塞或者轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法获取元素,所以竞争越激烈效率越低。
(3)ConcurrentHashMap的锁分段技术可有效提升并发访问率
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么多线程访问容器里面不同数据段时,线程间就不会存在锁竞争,从而可以有效提升高并发访问效率,这就是ConcurrentHashMap所使用的分段锁技术。首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据的时候,其他段的数据也能被其他线程访问。
二.ConcurrentHashMap的结构
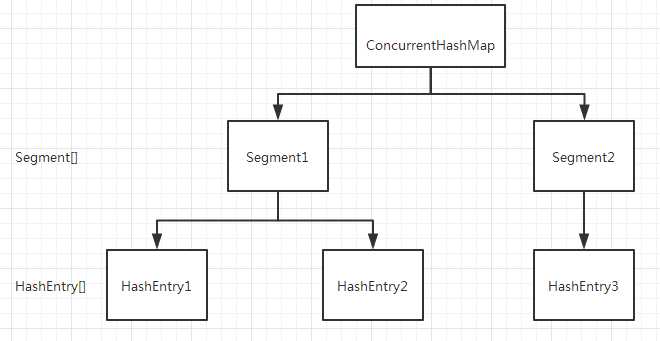
ConcurrentHashMap是由SegMent数组结构和HashEntry数组结构组成。Segment是一种可重入锁(RetreentLock),在ConcurrentHashMap中扮演锁的结;HashEntry则用于存储键值对数据。一个ConcurrentHashMap包含一个Segment数组。SegMent的结构和HashMap类似,是一种数组和链表结构。一个SegMent里面包含一个HashEntry数组里的元素,每一个HashEntry是一个链表结构的元素,每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组里面的数据进行修改时,必须首先获得与它对应的SegMent锁。结构如下所示:
三.ConcurrentHashMap的操作
这里介绍ConcurrentHashMap的三种操作-----get操作、put操作和size操作。
1 .get操作
Segment的get操作实现非常简单和高效。先经过一次散列,然后使用这个散列值通过散列算法定位到Segment,再通过散列算法定位到元素,代码如下。
1 public V get(Object key){ 2 int hash=hash(key.hashCode()); 3 return segmentFro(hash).get(key,hash); 4 }
get操作的高效之处在于这个get过程不需要加锁,除非读到的值为空才会加锁重读。我们知道hashtable的容器的get方法是需要加锁的,ConcurrentHashMap之所以不用加锁是因为它的get方法里面将要使用的共享变量都定义成了volitile类型,如用于统计当前Segment大小的count字段和用于存储值得HashMap的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖与原值),在get操作里面只需要读不需要写功效变量count和value,所以可以不用加锁。之所以不会读到过期的值,是因为根据Java内存模型的hapenn before 原则,对volitile字段的写入操作先于读操作,即使两个线程同事修改和获取volatile变量,get操作也能拿到最新的值,这是用volitile替换锁的经典应用场景。
2put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时,必须加锁。put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个步骤,第一个是判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置,然后将其放在HashEntry数组里。
(1)是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈值,则对数组进行扩容。值得一提的是,Segment的扩容个判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经达到容量的,如果达到了就进行扩容,但是,很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
(2)如果扩容
在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后将原来数组里的元素进行散列后插入到新的数组里。为高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
3.size操作
如果要统计整个ConcurrentHashMap里元素的带下,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,是不是把所有Segment的count相加就可以得到整个ConcurrentHashMap打下了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是可能累加前使用的count发生了变化,那么统计的结果就不准了。所以,最安全的做法是在统计size的时候把所有的segment的put,remove,和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住segment的方式来统计各个Segment大小,如果统计的过程中,容器的cout放生了变化,则在采用加锁的方式来统计所有的Segment大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put,remove和clean方法里面操作元素都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生了变化,从而得知容器的大小是否发生了变化。
标签:src block size ret 第一个 hash 分享 vol 可重入锁
原文地址:http://www.cnblogs.com/rainydayfmb/p/7531470.html