标签:size 顺序 详细介绍 功能 部分 ima pytho soup bsp
Beautiful Soup库是解析xml和html的功能库。html、xml大都是一对一对的标签构成,所以Beautiful Soup库是解析、遍历、维护“标签树”的功能库,只要提供的是标签类型Beautiful Soup库都可以进行很好的解析。
Beauti Soup库的导入
from bs4 import BeautifulSoup
import bs4
html文档 == 标签树 == BeautifulSoup类 可以认为三者是等价的
>>>from bs4 import BeautifulSoup >>>soup = BeautifulSoup(‘<html>data</html>‘,‘html.parser‘) >>>soup1=BeautifulSoup(open(r‘D:\demo.html‘),‘html.parser‘)
简单来说一个BeautifulSoup类对应一个html文档的全部内容。如上面的soup、soup1都对应一个html文档。
soup.标签名 可获得该标签信息,当存在多个一样的标签时,默认返回第一个标签的信息。
>>> soup=BeautifulSoup(demo,‘html.parser‘) >>> soup.title <title>四大美女</title> >>> soup.a <a href="http://www.baidu.com" target="_blank"><img heigth="200" src="picture/1.png" title="貂蝉" width="150"/></a>
soup.标签.name 可获取标签的名字,以字符串形式返回
>>> soup.a.name #获取a标签的名字 ‘a‘ >>> soup.a.parent.name #获取a标签的上级标签名字 ‘p‘ >>> soup.a.parent.parent.name #获取a标签的上上级标签的名字 ‘hr‘
soup.标签.attrs 可获得标签的属性,以字典形式返回
>>> soup.a.attrs #获取a标签的属性,字典返回
{‘href‘: ‘http://www.baidu.com‘, ‘target‘: ‘_blank‘}
>>> tag = soup.a.parent
>>> tag.name #获取p标签的属性,字典返回
‘p‘
>>> tag.attrs
{‘align‘: ‘center‘}
因为返回的是字典可以采用字典的方法对其进行信息的提取。
>>> for i,j in soup.a.attrs.items(): #for循环遍历字典
print(i,j)
href http://www.baidu.com
target _blank
>>> soup.a.attrs[‘href‘] #获取某个key的value值
‘http://www.baidu.com‘
>>> soup.a.attrs.keys() #获取字典所有的keys
dict_keys([‘href‘, ‘target‘])
>>> soup.a.attrs.values() #获取字典所有values
dict_values([‘http://www.baidu.com‘, ‘_blank‘])
soup.标签.string 可以获取标签之间的文本,返回字符串
>>> soup.title.string #获取title表之间的文本 ‘四大美女‘ >>> soup.a.string #获取a标签之间的文本,没有返回空 >>> soup.a <a href="http://www.baidu.com" target="_blank"><img heigth="200" src="picture/1.png" title="貂蝉" width="150"/></a>
HTML基本格式
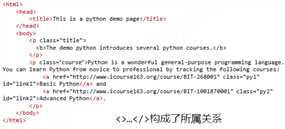
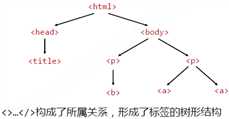
属性及说明
>>> soup.head
<head>
<meta charset="utf-8">
<title>四大美女</title>
</meta></head>
>>> soup.head.contents #获取head标签下的儿子节点
[‘\n‘, <meta charset="utf-8">
<title>四大美女</title>
</meta>]
>>> len(soup.body.contents) #通过len函数获取body标签的儿子节点个数
3
>>> for i in soup.body.children: #遍历body标签的儿子节点
print(i)
>>> for i in soup.body.descendants: #遍历body标签所有的儿子、子孙节点
print(i)
总结如下图:
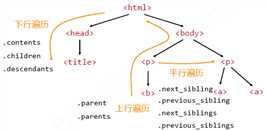
bs4库的prettify()方法--让HTML内容更加“友好”的显示

Beautiful Soup库提供了<>.find_all()函数,返回一个列表类型,存储查找的结果。
详细介绍如下:
<>.find_all(name, attrs, recursive, string,**kwargs)
<tag>(...) == <tag>.find_all(...)
soup(...) == soup.find_all(...)
>>> soup.find_all(‘p‘,target=‘_blank‘) #查找p标签,而且属性值是_blank的 [] >>> soup.find_all(id=‘su‘) #查找id属性值是su的标签 [<input class="bg s_btn" id="su" type="submit" value="百度一下"/>]
标签:size 顺序 详细介绍 功能 部分 ima pytho soup bsp
原文地址:http://www.cnblogs.com/P3nguin/p/7532410.html