标签:lib 包括 grant 过程 err 生成 服务 grep man
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
良好的容错性,节点出现问题SQL仍可完成执行。
Jobtracker是hadoop1.x中的组件,它的功能相当于: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
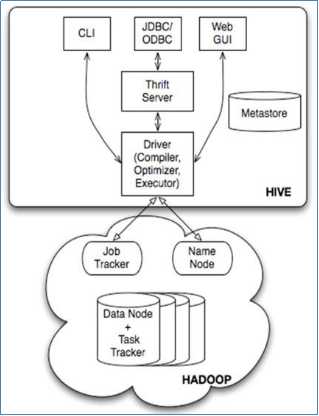
基本组成
Hive利用HDFS存储数据,利用MapReduce查询数据

Hive与传统数据库对比
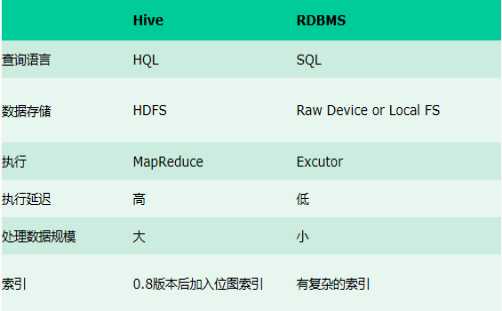
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
² db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
² table:在hdfs中表现所属db目录下一个文件夹
² external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
² partition:在hdfs中表现为table目录下的子目录
² bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
单机版:
元数据库mysql版:
Hive只在一个节点上安装即可
1.上传tar包
2.解压
tar -zxvf hive-0.9.0.tar.gz -C /cloud/
3.安装mysql数据库(切换到root用户)(装在哪里没有限制,只有能联通hadoop集群的节点)
mysql安装仅供参考,不同版本mysql有各自的安装流程
rpm -qa | grep mysql
rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps
rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm
rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm
修改mysql的密码
/usr/bin/mysql_secure_installation
(注意:删除匿名用户,允许用户远程连接)
登陆mysql
mysql -u root -p
4.配置hive
(a)配置HIVE_HOME环境变量 vi conf/hive-env.sh 配置其中的$hadoop_home
(b)配置元数据库信息 vi hive-site.xml
添加如下内容:
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
5.安装hive和mysq完成后,将mysql的连接jar包拷贝到$HIVE_HOME/lib目录下
如果出现没有权限的问题,在mysql授权(在安装mysql的机器上执行)
mysql -uroot -p
#(执行下面的语句 *.*:所有库下的所有表 %:任何IP地址或主机都可以连接)
GRANT ALL PRIVILEGES ON *.* TO ‘root‘@‘%‘ IDENTIFIED BY ‘root‘ WITH GRANT OPTION;
FLUSH PRIVILEGES;
6. Jline包版本不一致的问题,需要拷贝hive的lib目录中jline.2.12.jar的jar包替换掉hadoop中的
/home/hadoop/app/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar
启动hive
bin/hive
bin/hive
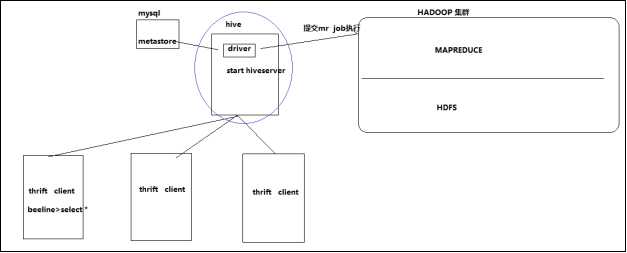
启动方式,(假如是在hadoop01上):
启动为前台:bin/hiveserver2
启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
启动成功后,可以在别的节点上用beeline去连接
v 方式(1)
hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//mini1:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
v 方式(2)
或者启动就连接:
bin/beeline -u jdbc:hive2://mini1:10000 -n hadoop
[hadoop@hdp-node-02 ~]$ hive -e ‘sql’
标签:lib 包括 grant 过程 err 生成 服务 grep man
原文地址:http://www.cnblogs.com/duan2/p/7565106.html