标签:引用 log sspi scrapy 语句 handle att stat 一个队列
下载scrapy-redis:
https://github.com/rmax/scrapy-redis
下载zip文件之后解压
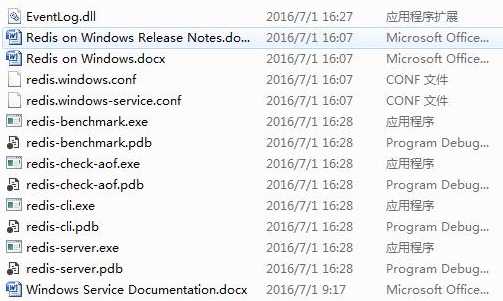
建立两个批处理文件,start.bat和clear.bat
start.bat的内容为redis-server redis.windows.conf
clear.bat的内容为redis-cli flushdb
双击start.bat启动
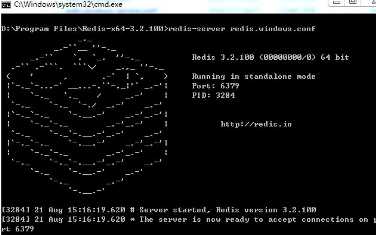
这样就说明下好了,运行正常。
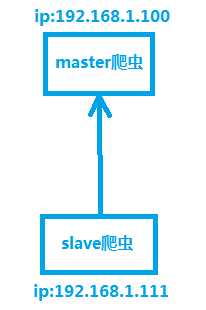
我们需要构建一个分布式爬虫系统:由一个master爬虫和slave爬虫组成,master端部署了redis数据库,master端从本地获取redis中的url,slave端通过网络连接访问master端的redis数据库,从中获取url进行爬取,而redis数据库本身的调度功能保证了master爬虫和slave爬虫不会爬取到重复的url。
新建爬虫项目,打开cmd:
scrapy startproject scrapyRedis
将src中的scrapy_redis这个文件夹复制到刚才新建的爬虫项目中。
按照scrapy-redis git上的说明,创建爬虫时,在新建的爬虫文件中粘贴这段代码到文件中

继承了RedisSpider这个类之后,爬虫爬取的数据就会首先存入redis,接下来再从redis里面读取,就相当于是一个队列,不断地往redis里面写入url,然后从redis里面读取网址。就不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从list中pop出来成为请求的url地址。
引用scrapy-redis之后,写分布式爬虫就和写普通的scrapy爬虫一样,具体代码如下:
#encoding:utf-8 from scrapy_redis.spiders import RedisSpider class MySpider(RedisSpider): name = ‘jobbole‘ allowed_domains = ["blog.jobbole.com"] # 其实如果不设置以下语句,scrapy-redis也会默认生成一个redis-key“爬虫名+:start_urls” redis_key = "jobbole:start_urls"
#slave端爬虫注释掉下面的内容
start_urls = [‘http://blog.jobbole.com/all-posts/‘]
# 收集伯乐在线所有404的url以及404页面数 handle_httpstatus_list = [404] def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse """ # 解析列表页中的所有文章url并交给scrapy下载后并进行解析 if response.status == 404: self.fail_urls.append(response.url) self.crawler.stats.inc_value("failed_url") post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url}, callback=self.parse_detail) # 提取下一页并交给scrapy进行下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, post_url), callback=self.parse) def parse_detail(self, response): pass
在爬虫的settings.py中,我们需要部署一下,master爬虫和slave爬虫其他地方都差不多,唯独settings.py部署方式上有区别:
master爬虫部署,访问本地的redis数据库:
REDIS_URL = None REDIS_HOST = ‘localhost‘ REDIS_PORT = 6379
slave爬虫部署,需要访问master端的redis数据库:
REDIS_URL = ‘redis://192.168.1.100:6379‘ REDIS_HOST = None REDIS_PORT = None
新建一个方便pycharm运行的文件main.py
from scrapy import cmdline cmdline.execute("scrapy crawl jobbole".split())
分别运行master,slave爬虫一个简单的分布式爬虫就做好了。
标签:引用 log sspi scrapy 语句 handle att stat 一个队列
原文地址:http://www.cnblogs.com/zylq-blog/p/7565171.html