标签:src ons loader spider 简介 通过 调度 spi 生成
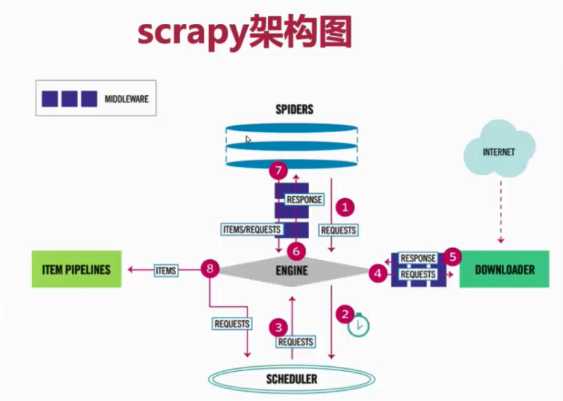
1、SPIDERS的yeild将request发送给ENGIN
2、ENGINE对request不做任何处理发送给SCHEDULER
3、SCHEDULER( url调度器),生成request交给ENGIN
4、ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
5、DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
6、ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
7、将解析出来的items或者requests发送给ENGIN
8、ENGIN获取到items或者requests,将items发送给ITEM PIPELINES,将requests发送给SCHEDULER
标签:src ons loader spider 简介 通过 调度 spi 生成
原文地址:http://www.cnblogs.com/zylq-blog/p/7565276.html