标签:style 问题 容量 src 个人 之间 add bsp sql
1.表连接的根本条件是共同字段,也叫关联字段也叫冗余字段,有关联字段(冗余字段)才能将两张表的记录匹配起来嘛。
其中关联字段,也即形成了表之间的关系,即1对1,还是1对多,还是多对多。
这些表之间的关系,就是通过关联字段形成的1对1,还是1对多,还是多对多关系。
也正因为表通过关联字段,联系起来了。关联字段所在的几张表又形成了几对几的关系。也就造成了关联结果表,即关联后产生的表。会存在记录(行冗余问题)。
即,想一想,为什么将一对多拆成两张表?因为怕冗余记录太多嘛。
举个例子:table(uid,age,address),一个人是有很多个地址的。所以就要把uid和address单独隔离出来的。否则放在一张表里,就会出现这样的记录:
张三,18,深圳南山区1路1号
张三,18,深圳福田区x路x号
发现张三,18这个字段无故出现了多次,白费。所以为了考虑数据库容量,直接将uid addres字段拆出来。这就是见表第二范式。
结关系:表关联->关联字段->防止记录和字段冗余
表关系,
1对多,是为了防止记录的某些不相关字段冗余,所以字段出现1对多关系必须要建立两张表。
1对1,是因为两个不相关的领域,虽然放在一张表里也可以,也不会出现记录无关系字段额外冗余,但这样会形成一张宽表。涉及insert,更改记录操作时,会很麻烦。所以1对1也要建立两张表。
多对多,
表关联刚好对原来的表之间关系拆分进行了你想处理,所以表关联的结果必然是
2.表连接冗余字段问题:
表连接就是将两个表连起来,字段默认都会有。除非你select 指定你想要的字段。
查询语句:select * from t_test t1 left join t_test2 t2 on t1.uid = t2.uid;
因为select *,所以默认俩表的全部字段会显示出来。如下:
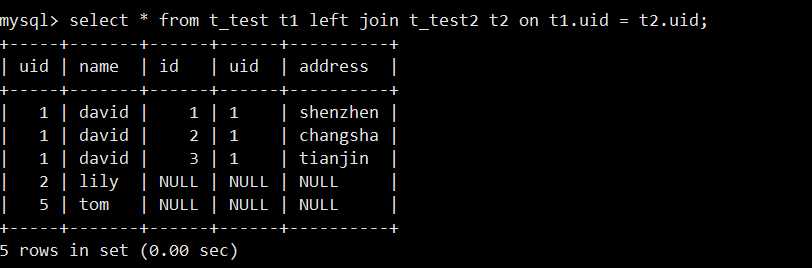
此时就会发现,进行表关联的字段(此处是uid),就会有两个。因为两张表能有联系,全是靠共同字段嘛,select * 肯定会有两列相同的字段出来,所以这时候,你就需要手动指定显示哪个表的共同字段,否则迷惑性太强,俩字段显示出来。太难看了。
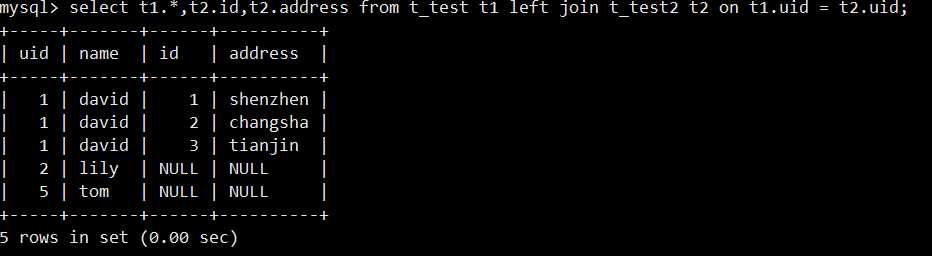
改正后的sql:select t1.*,t2.id,t2.address from t_test t1 left join t_test2 t2 on t1.uid = t2.uid;
显示某张表的全部字段:t1.*即可。
查询结果如下:,你看,就没有多余的公共字段了吧,因为你select 指定了显示哪些字段。
标签:style 问题 容量 src 个人 之间 add bsp sql
原文地址:http://www.cnblogs.com/panxuejun/p/7565713.html