标签:cluster zabbix corosync pacemaker pcs.cman
一、pacemaker 是什么
1.pacemaker 简单说明
2.pacemaker 由来
二、pacemaker 特点
三、pacemaker 内部结构
1.群集组件说明:
2.功能概述
四、centos6.x+pacemaker+corosync实现zabbix高可用
1、环境说明
五、安装pacemaker和corosync(各个节点均要运行)
1、前提条件各个节点完成主机解析工作。
2、各个节点的时间同步
3、各个节点完成互信工作
4、关闭防火墙与SELinux
5、安装pacemaker+corosync+pcs
六、配置corosync
1、设置变量
2、更改corosync配置文件
3.生成密钥文件
七、安装和配置cman
八、编辑cluster.conf
九、检查配置文件并开机自启
十、资源配置
十一、验证
十二、常用命令
十三、zabbix启动脚本
pacemaker(直译:心脏起搏器),是一个群集资源管理器。它实现最大可用性群集服务(亦称资源管理)的节点和资源级故障检测和恢复使用您的首选集群基础设施(OpenAIS的或Heaerbeat)提供的消息和成员能力。
它可以做乎任何规模的集群,并配备了一个强大的依赖模型,使管理员能够准确地表达群集资源之间的关系(包括顺序和位置)。几乎任何可以编写脚本,可以管理作为心脏起搏器集群的一部分。
我再次说明一下,pacemaker是个资源管理器,不是提供心跳信息的,因为它似乎是一个普遍的误解,也是值得的。pacemaker是一个延续的CRM(亦称Heartbeat V2资源管理器),最初是为心跳,但已经成为独立的项目。
大家都知道,Heartbeat 到了V3版本后,拆分为多个项目,其中pacemaker就是拆分出来的资源管理器。
Heartbeat 3.0拆分之后的组成部分:
Heartbeat:将原来的消息通信层独立为heartbeat项目,新的heartbeat只负责维护集群各节点的信息以及它们之前通信;
Cluster Glue:相当于一个中间层,它用来将heartbeat和pacemaker关联起来,主要包含2个部分,即为LRM和STONITH。
Resource Agent:用来控制服务启停,监控服务状态的脚本集合,这些脚本将被LRM调用从而实现各种资源启动、停止、监控等等。
Pacemaker : 也就是Cluster Resource Manager (简称CRM),用来管理整个HA的控制中心,客户端通过pacemaker来配置管理监控整个集群。
主机和应用程序级别的故障检测和恢复
几乎支持任何冗余配置
同时支持多种集群配置模式
配置策略处理法定人数损失(多台机器失败时)
支持应用启动/关机顺序
支持,必须/必须在同一台机器上运行的应用程序
支持多种模式的应用程序(如主/从)
可以测试任何故障或群集的群集状态
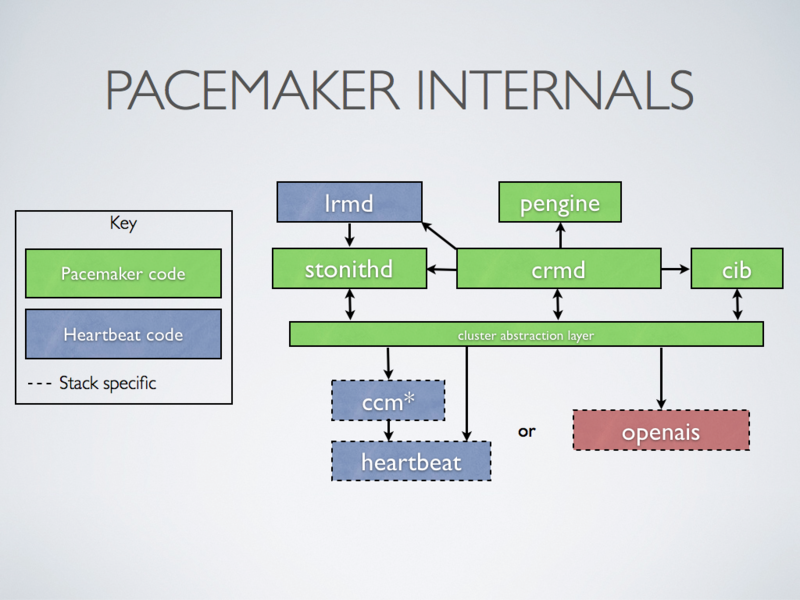
stonithd:心跳系统。
lrmd:本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)。
pengine:政策引擎。根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表。
CIB:群集信息库。包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有群集节点。
CRMD:集群资源管理守护进程。主要是消息代理的PEngine和LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群。
OpenAIS:OpenAIS的消息和成员层。
Heartbeat:心跳消息层,OpenAIS的一种替代。
CCM:共识群集成员,心跳成员层。
CMAN是红帽RHCS套件的核心部分,CCS是CMAN集群配置系统,配置cluster.conf,而cluster.conf其实就是openais的配置文件,通过CCS映射到openais。
CIB使用XML表示集群的集群中的所有资源的配置和当前状态。CIB的内容会被自动在整个集群中同步,使用PEngine计算集群的理想状态,生成指令列表,然后输送到DC(指定协调员)。Pacemaker 集群中所有节点选举的DC节点作为主决策节点。如果当选DC节点宕机,它会在所有的节点上, 迅速建立一个新的DC。DC将PEngine生成的策略,传递给其他节点上的LRMd(本地资源管理守护程序)或CRMD通过集群消息传递基础结构。当集群中有节点宕机,PEngine重新计算的理想策略。在某些情况下,可能有必要关闭节点,以保护共享数据或完整的资源回收。为此,Pacemaker配备了stonithd设备。STONITH可以将其它节点“爆头”,通常是实现与远程电源开关。Pacemaker会将STONITH设备,配置为资源保存在CIB中,使他们可以更容易地监测资源失败或宕机。
OS:Centos 6.7 x86_64 mini
APP: Pacemaker 1.1.15
LNMP+Zabbix 3.4.1
corosync+pcs+cman
IP ADDR:vip-192.168.8.47/20
zabbix01-192.168.8.61/20
zabbix02-192.168.8.63/20
zabbixdb-192.168.8.120/20
PS:IP地址需要根据个人具体环境配置,VIP和zabbix要在同一网段。
拓扑结构

PS:接下来会直接介绍pacemaker和corosync的安装和配置,关于zabbix+LNMP环境的部分请参考之前发表的“zabbix3.2编译安装”或“zabbix高可用”两篇文章。
vim /etc/hosts
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.61 zabbix01.okooo.cn zabbix01
192.168.8.63 zabbix02.okooo.cn zabbix02
192.168.8.120 zbxdb.okooo.cn zbxdb
ntpdate 210.72.145.44
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ‘‘
ssh-copy-id -i .ssh/id_rsa.pub root@zabbix01/02/db.okooo.cn
# cat /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - SELinux is fully disabled.
SELINUX=disabled
# SELINUXTYPE= type of policy in use. Possible values are:
# targeted - Only targeted network daemons are protected.
# strict - Full SELinux protection.
SELINUXTYPE=targeted
# /etc/init.d/iptables status
iptables: Firewall is not running.
yum install -y pacemaker corosync pcs
export ais_port=4000
export ais_mcast=226.94.1.1
export ais_addr=192.168.15.0
env|grep ais
cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
sed -i.bak“s /.* mcastaddr:。* / mcastaddr:\ $ ais_mcast / g”/etc/corosync/corosync.conf
sed -i.bak“s /.* mcastport:。* / mcastport:\ $ ais_port / g”/etc/corosync/corosync.conf
sed -i.bak“s /.* bindnetaddr:。* / bindnetaddr:\ $ ais_addr / g”/etc/corosync/corosync.confcat /etc/corosync/corosync.conf
# Please read the corosync.conf.5 manual page compatibility: whitetanktotem { version: 2 secauth: on #启动认证 threads: 2 interface { ringnumber: 0 bindnetaddr: 192.168.15.0 #修改心跳线网段 mcastaddr: 226.94.1.1 #组播传播心跳信息 mcastport: 4000 ttl: 1 } }logging { fileline: off to_stderr: no to_logfile: yes to_syslog: no logfile: /var/log/cluster/corosync.log #日志位置 debug: off timestamp: on logger_subsys { subsys: AMF debug: off } }amf { mode: disabled }#启用pacemakerservice { ver: 0 name: pacemaker }aisexec { user: root group: root }yum install -y cman
sed -i.sed "s/.*CMAN_QUORUM_TIMEOUT=.*/CMAN_QUORUM_TIMEOUT=0/g" /etc/sysconfig/cman
# cat /etc/sysconfig/cman
# CMAN_CLUSTER_TIMEOUT -- amount of time to wait to join a cluster
# before giving up. If CMAN_CLUSTER_TIMEOUT is positive, then we will
# wait CMAN_CLUSTER_TIMEOUT seconds before giving up and failing if
# we can‘t join a cluster. If CMAN_CLUSTER_TIMEOUT is zero, then we
# will wait indefinitely for a cluster join. If CMAN_CLUSTER_TIMEOUT is
# negative, do not check to see if we have joined a cluster.
#CMAN_CLUSTER_TIMEOUT=5# CMAN_QUORUM_TIMEOUT -- amount of time to wait for a quorate cluster on
# startup. Quorum is needed by many other applications, so we may as
# well wait here. If CMAN_QUORUM_TIMEOUT is zero, quorum will
# be ignored.
CMAN_QUORUM_TIMEOUT=0# CMAN_SHUTDOWN_TIMEOUT -- amount of time to wait for cman to become a
# cluster member before calling ‘cman_tool‘ leave during shutdown.
# The default is 60 seconds
#CMAN_SHUTDOWN_TIMEOUT=6# CMAN_NOTIFYD_START - control the startup behaviour for cmannotifyd,
# the variable can take 3 values:
# yes | will always start cmannotifyd
# no | will never start cmannotifyd
# conditional (default) | will start cmannotifyd only if scriptlets
# are found in /etc/cluster/cman-notify.d
#CMAN_NOTIFYD_START=conditional# CMAN_SSHD_START -- control sshd startup behaviour,
# the variable can take 2 values:
# yes | cman will start sshd as early as possible
# no (default) | cman will not start sshd
#CMAN_SSHD_START=no# DLM_CONTROLD_OPTS -- allow extra options to be passed to dlm_controld daemon.
#DLM_CONTROLD_OPTS=""# Allow tuning of DLM kernel config.
# do NOT change unless instructed to do so.
#DLM_LKBTBL_SIZE=""
#DLM_RSBTBL_SIZE=""
#DLM_DIRTBL_SIZE=""
#DLM_TCP_PORT=""# FENCE_JOIN_TIMEOUT -- seconds to wait for fence domain join to
# complete. If the join hasn‘t completed in this time, fence_tool join
# exits with an error, and this script exits with an error. To wait
# indefinitely set the value to -1.
#FENCE_JOIN_TIMEOUT=20# FENCED_MEMBER_DELAY -- amount of time to delay fence_tool join to allow
# all nodes in cluster.conf to become cluster members. In seconds.
#FENCED_MEMBER_DELAY=45# FENCE_JOIN -- boolean value used to control whether or not this node
# should join the fence domain. If FENCE_JOIN is set to "no", then
# the script will not attempt to the fence domain. If FENCE_JOIN is
# set to "yes", then the script will attempt to join the fence domain.
# If FENCE_JOIN is set to any other value, the default behavior is
# to join the fence domain (equivalent to "yes").
# When setting FENCE_JOIN to "no", it is important to also set
# DLM_CONTROLD_OPTS="-f0" (at least) for correct operation.
# Please note that clusters without fencing are not
# supported by Red Hat except for MRG installations.
#FENCE_JOIN="yes"# FENCED_OPTS -- allow extra options to be passed to fence daemon.
#FENCED_OPTS=""# NETWORK_BRIDGE_SCRIPT -- script to use for xen network bridging.
# This script must exist in the /etc/xen/scripts directory.
# The default script is "network-bridge".
#NETWORK_BRIDGE_SCRIPT="network-bridge"# CLUSTERNAME -- override clustername as specified in cluster.conf
#CLUSTERNAME=""# NODENAME -- specify the nodename of this node. Default autodetected.
#NODENAME=""# CONFIG_LOADER -- select default config parser.
# This can be:
# xmlconfig - read directly from cluster.conf and use ricci as default
# config propagation method. (default)
#CONFIG_LOADER=xmlconfig# CONFIG_VALIDATION -- select default config validation behaviour.
# This can be:
# FAIL - Use a very strict checking. The config will not be loaded if there
# are any kind of warnings/errors
# WARN - Same as FAIL, but will allow the config to load (this is temporarily
# the default behaviour)
# NONE - Disable config validation. Highly discouraged
#CONFIG_VALIDATION=WARN# CMAN_LEAVE_OPTS -- allows extra options to be passed to cman_tool when leave
# operation is performed.
#CMAN_LEAVE_OPTS=""# INITLOGLEVEL -- select how verbose the init script should be.
# Possible values:
# quiet - only one line notification for start/stop operations
# terse (default) - show only required activity
# full - show everything
#INITLOGLEVEL=terse
ccs_config_validate
service cman start
cman_tool nodes
service pacemaker start
chkconfig cman on
chkconfig pacemaker on
pcs cluster auth zabbix01 zabbix02 #节点间认证
pcs cluster start --all #启动集群中所有节点
pcs resource create ClusterIP IPaddr2 ip=192.168.8.47 cidr_netmask=32 op monitor interval=2s #创建一个名为ClusterIP,类型是IPadd2,VIP是192.168.8.47/32 每隔2秒检测一次的资源
pcs property set stonith-enabled=false #因我们没有STONITH设备,所以我们先关闭这个属性
pcs resource create zabbix-server lsb:zabbix_server op monitor interval=5s #创建一个名为zabbix-server、标准是lsb、应用是zabbis_server,每隔5秒检测一次的资源。lsb指/etc/init.d/下的启动脚本
pcs resource group add zabbix ClusterIP zabbix-server #将ClusterIP zabbix-server资源加入到zabbix资源组中
pcs property set no-quorum-policy="ignore" #忽略法定人数不足时进行仲裁
pcs property set default-resource-stickiness="100" #资源粘性为100
pcs constraint colocation add zabbix-server ClusterIP #资源共置
pcs constraint order ClusterIP then zabbix-server #资源限制,确保VIP和service在同一个节点上运行,而且VIP要在service之前完成。
pcs constraint location ClusterIP prefers zabbix01 #ClusterIP更喜欢在zabbix01节点上,可用于节点故障恢复
pcs constraint location zabbix-server prefers zabbix01 #zabbix-server更喜欢在zabbix01节点上,可用于故障恢复
1、在zabbix01上操作停止zabbix_server 服务

PS:集群可以保证服务的高可用
root@zabbix01:~
# pcs resource
Resource Group: zabbix
ClusterIP (ocf::heartbeat:IPaddr2): Started zabbix01
zabbix-server (lsb:zabbix_server): Started zabbix01
root@zabbix01:~
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:50:56:bb:68:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.61/20 brd 192.168.15.255 scope global eth0
inet 192.168.8.47/32 brd 192.168.15.255 scope global eth0
inet6 fe80::250:56ff:febb:6849/64 scope link
valid_lft forever preferred_lft forever
PS:此时VIP和资源均在zabbix01上运行
root@zabbix01:~
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:50:56:bb:68:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.61/20 brd 192.168.15.255 scope global eth0
inet6 fe80::250:56ff:febb:6849/64 scope link
valid_lft forever preferred_lft forever
root@zabbix01:~
# ssh zabbix02 "pcs resource"
Resource Group: zabbix
ClusterIP (ocf::heartbeat:IPaddr2): Started zabbix02
zabbix-server (lsb:zabbix_server): Started zabbix02
root@zabbix01:~
# pcs cluster start zabbix01
zabbix01: Starting Cluster...
root@zabbix01:~
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:50:56:bb:68:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.61/20 brd 192.168.15.255 scope global eth0
inet 192.168.8.47/32 brd 192.168.15.255 scope global eth0
inet6 fe80::250:56ff:febb:6849/64 scope link
valid_lft forever preferred_lft forever
root@zabbix01:~
# pcs resource
Resource Group: zabbix
ClusterIP (ocf::heartbeat:IPaddr2): Started zabbix01
zabbix-server (lsb:zabbix_server): Started zabbix01
PS:重启集群后资源和VIP均被zabbix02接管,但zabbix01恢复后资源与VIP又再次回到zabbix01.
1、查看集群状态
# pcs cluster status
Cluster Status:
Stack: cman
Current DC: zabbix01 (version 1.1.15-5.el6-e174ec8) - partition with quorum
Last updated: Thu Sep 21 02:13:20 2017 Last change: Wed Sep 20 09:13:10 2017 by root via cibadmin on zabbix01
2 nodes and 2 resources configured
PCSD Status:
zabbix01: Online
zabbix02: Online
2、查看配置
# pcs config show
Cluster Name: zabbixcluster
Corosync Nodes:
zabbix02 zabbix01
Pacemaker Nodes:
zabbix01 zabbix02
Resources:
Group: zabbix
Resource: ClusterIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: ip=192.168.8.47 cidr_netmask=32
Operations: start interval=0s timeout=20s (ClusterIP-start-interval-0s)
stop interval=0s timeout=20s (ClusterIP-stop-interval-0s)
monitor interval=2s (ClusterIP-monitor-interval-2s)
Resource: zabbix-server (class=lsb type=zabbix_server)
Operations: start interval=0s timeout=15 (zabbix-server-start-interval-0s)
stop interval=0s timeout=15 (zabbix-server-stop-interval-0s)
monitor interval=5s (zabbix-server-monitor-interval-5s)
Stonith Devices:
Fencing Levels:
Location Constraints:
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
Alerts:
No alerts defined
Resources Defaults:
No defaults set
Operations Defaults:
timeout: 60s
Cluster Properties:
cluster-infrastructure: cman
dc-version: 1.1.15-5.el6-e174ec8
default-resource-stickiness: 100
have-watchdog: false
last-lrm-refresh: 1505857479
no-quorum-policy: ignore
stonith-enabled: false
# pcs cluster cib
<cib crm_feature_set="3.0.10" validate-with="pacemaker-2.5" epoch="82" num_updates="182" admin_epoch="0" cib-last-written="Thu Sep 21 02:56:11 2017" update-origin="zabbix01" update-client="cibadmin" update-user="root" have-quorum="1" dc-uuid="zabbix02">
<configuration>
<crm_config>
<cluster_property_set id="cib-bootstrap-options">
<nvpair id="cib-bootstrap-options-have-watchdog" name="have-watchdog" value="false"/>
<nvpair id="cib-bootstrap-options-dc-version" name="dc-version" value="1.1.15-5.el6-e174ec8"/>
<nvpair id="cib-bootstrap-options-cluster-infrastructure" name="cluster-infrastructure" value="cman"/>
<nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="false"/>
<nvpair id="cib-bootstrap-options-no-quorum-policy" name="no-quorum-policy" value="ignore"/>
<nvpair id="cib-bootstrap-options-default-resource-stickiness" name="default-resource-stickiness" value="100"/>
<nvpair id="cib-bootstrap-options-last-lrm-refresh" name="last-lrm-refresh" value="1505857479"/>
</cluster_property_set>
</crm_config>
<nodes>
<node id="zabbix02" uname="zabbix02"/>
<node id="zabbix01" uname="zabbix01"/>
</nodes>
<resources>
<group id="zabbix">
<primitive class="ocf" id="ClusterIP" provider="heartbeat" type="IPaddr2">
<instance_attributes id="ClusterIP-instance_attributes">
<nvpair id="ClusterIP-instance_attributes-ip" name="ip" value="192.168.8.47"/>
<nvpair id="ClusterIP-instance_attributes-cidr_netmask" name="cidr_netmask" value="32"/>
</instance_attributes>
<operations>
<op id="ClusterIP-start-interval-0s" interval="0s" name="start" timeout="20s"/>
<op id="ClusterIP-stop-interval-0s" interval="0s" name="stop" timeout="20s"/>
<op id="ClusterIP-monitor-interval-2s" interval="2s" name="monitor"/>
</operations>
<meta_attributes id="ClusterIP-meta_attributes"/>
</primitive>
<primitive class="lsb" id="zabbix-server" type="zabbix_server">
<instance_attributes id="zabbix-server-instance_attributes"/>
<operations>
<op id="zabbix-server-start-interval-0s" interval="0s" name="start" timeout="15"/>
<op id="zabbix-server-stop-interval-0s" interval="0s" name="stop" timeout="15"/>
<op id="zabbix-server-monitor-interval-5s" interval="5s" name="monitor"/>
</operations>
<meta_attributes id="zabbix-server-meta_attributes"/>
</primitive>
</group>
</resources>
<constraints>
<rsc_colocation id="colocation-zabbix-server-ClusterIP-INFINITY" rsc="zabbix-server" score="INFINITY" with-rsc="ClusterIP"/>
<rsc_order first="ClusterIP" first-action="start" id="order-ClusterIP-zabbix-server-mandatory" then="zabbix-server" then-action="start"/>
<rsc_location id="location-ClusterIP-zabbix01-INFINITY" node="zabbix01" rsc="ClusterIP" score="INFINITY"/>
<rsc_location id="location-zabbix-server-zabbix01-INFINITY" node="zabbix01" rsc="zabbix-server" score="INFINITY"/>
</constraints>
<op_defaults>
<meta_attributes id="op_defaults-options">
<nvpair id="op_defaults-options-timeout" name="timeout" value="60s"/>
</meta_attributes>
</op_defaults>
</configuration>
<status>
<node_state id="zabbix01" uname="zabbix01" in_ccm="true" crmd="online" crm-debug-origin="do_update_resource" join="member" expected="member">
<lrm id="zabbix01">
<lrm_resources>
<lrm_resource id="zabbix-server" type="zabbix_server" class="lsb">
<lrm_rsc_op id="zabbix-server_last_0" operation_key="zabbix-server_start_0" operation="start" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="10:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;10:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix01" call-id="12" rc-code="0" op-status="0" interval="0" last-run="1505940302" last-rc-change="1505940302" exec-time="44" queue-time="0" op-digest="f2317cad3d54cec5d7d7aa7d0bf35cf8"/>
<lrm_rsc_op id="zabbix-server_monitor_5000" operation_key="zabbix-server_monitor_5000" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="11:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;11:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix01" call-id="13" rc-code="0" op-status="0" interval="5000" last-rc-change="1505940302" exec-time="27" queue-time="1" op-digest="873ed4f07792aa8ff18f3254244675ea"/>
</lrm_resource>
<lrm_resource id="ClusterIP" type="IPaddr2" class="ocf" provider="heartbeat">
<lrm_rsc_op id="ClusterIP_last_0" operation_key="ClusterIP_start_0" operation="start" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="7:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;7:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix01" call-id="10" rc-code="0" op-status="0" interval="0" last-run="1505940302" last-rc-change="1505940302" exec-time="117" queue-time="0" op-digest="31f0afcca8f5f3ffa441c421e2c65fe1"/>
<lrm_rsc_op id="ClusterIP_monitor_2000" operation_key="ClusterIP_monitor_2000" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="8:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;8:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix01" call-id="11" rc-code="0" op-status="0" interval="2000" last-rc-change="1505940302" exec-time="160" queue-time="0" op-digest="e05b48764ef09ebc8e21989b06afa924"/>
</lrm_resource>
</lrm_resources>
</lrm>
<transient_attributes id="zabbix01">
<instance_attributes id="status-zabbix01">
<nvpair id="status-zabbix01-shutdown" name="shutdown" value="0"/>
</instance_attributes>
</transient_attributes>
</node_state>
<node_state id="zabbix02" uname="zabbix02" crmd="online" crm-debug-origin="do_update_resource" in_ccm="true" join="member" expected="member">
<transient_attributes id="zabbix02">
<instance_attributes id="status-zabbix02">
<nvpair id="status-zabbix02-shutdown" name="shutdown" value="0"/>
</instance_attributes>
</transient_attributes>
<lrm id="zabbix02">
<lrm_resources>
<lrm_resource id="zabbix-server" type="zabbix_server" class="lsb">
<lrm_rsc_op id="zabbix-server_last_0" operation_key="zabbix-server_stop_0" operation="stop" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="9:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;9:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix02" call-id="39" rc-code="0" op-status="0" interval="0" last-run="1505940302" last-rc-change="1505940302" exec-time="50" queue-time="0" op-digest="f2317cad3d54cec5d7d7aa7d0bf35cf8"/>
<lrm_rsc_op id="zabbix-server_monitor_5000" operation_key="zabbix-server_monitor_5000" operation="monitor" crm-debug-origin="build_active_RAs" crm_feature_set="3.0.10" transition-key="9:53:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;9:53:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix02" call-id="37" rc-code="0" op-status="0" interval="5000" last-rc-change="1505940185" exec-time="17" queue-time="0" op-digest="873ed4f07792aa8ff18f3254244675ea"/>
</lrm_resource>
<lrm_resource id="ClusterIP" type="IPaddr2" class="ocf" provider="heartbeat">
<lrm_rsc_op id="ClusterIP_last_0" operation_key="ClusterIP_stop_0" operation="stop" crm-debug-origin="do_update_resource" crm_feature_set="3.0.10" transition-key="6:56:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;6:56:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix02" call-id="41" rc-code="0" op-status="0" interval="0" last-run="1505940302" last-rc-change="1505940302" exec-time="93" queue-time="0" op-digest="31f0afcca8f5f3ffa441c421e2c65fe1"/>
<lrm_rsc_op id="ClusterIP_monitor_2000" operation_key="ClusterIP_monitor_2000" operation="monitor" crm-debug-origin="build_active_RAs" crm_feature_set="3.0.10" transition-key="6:53:0:76f2a258-6d10-4819-8063-54875d8f896a" transition-magic="0:0;6:53:0:76f2a258-6d10-4819-8063-54875d8f896a" on_node="zabbix02" call-id="35" rc-code="0" op-status="0" interval="2000" last-rc-change="1505940185" exec-time="118" queue-time="0" op-digest="e05b48764ef09ebc8e21989b06afa924"/>
</lrm_resource>
</lrm_resources>
</lrm>
</node_state>
</status>
</cib>
3、查看资源
# pcs resource
Resource Group: zabbix
ClusterIP (ocf::heartbeat:IPaddr2): Started zabbix01
zabbix-server (lsb:zabbix_server): Started zabbix01
4、查看资源组
#pcs resource group list
zabbix: ClusterIP zabbix-server
# cat /etc/init.d/zabbix_server
#!/bin/bash
#Location of zabbix binary. Change path as neccessary
DAEMON=/usr/local/zabbix/sbin/zabbix_server
NAME=`basename $DAEMON`
#Pid file of zabbix, should be matched with pid directive in nginx config file.
PIDFILE=/tmp/$NAME.pid
#this file location
SCRIPTNAME=/etc/init.d/$NAME
#only run if binary can be found
test -x $DAEMON || exit 0
RETVAL=0
start() {
echo $"Starting $NAME"
$DAEMON
RETVAL=0
}
stop() {
echo $"Graceful stopping $NAME"
[ -s "$PIDFILE" ] && kill -QUIT `cat $PIDFILE`
RETVAL=0
}
forcestop() {
echo $"Quick stopping $NAME"
[ -s "$PIDFILE" ] && kill -TERM `cat $PIDFILE`
RETVAL=$?
}
reload() {
echo $"Graceful reloading $NAME configuration"
[ -s "$PIDFILE" ] && kill -HUP `cat $PIDFILE`
RETVAL=$?
}
status() {
if [ -s $PIDFILE ]; then
echo $"$NAME is running."
RETVAL=0
else
echo $"$NAME stopped."
RETVAL=3
fi
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
force-stop)
forcestop
;;
restart)
stop
start
;;
reload)
reload
;;
status)
status
;;
*)
echo $"Usage: $0 {start|stop|force-stop|restart|reload|status}"
exit 1
esac
exit $RETVAL
</pre>
参考资料
https://www.zabbix.org/wiki/Docs/howto/high_availability_on_Centos_6.x
https://ericsysmin.com/2016/02/18/configuring-high-availability-ha-zabbix-server-on-centos-7/
本文出自 “Dr小白” 博客,请务必保留此出处http://metis.blog.51cto.com/1203503/1967400
pacemaker+corosync实现zabbix高可用集群
标签:cluster zabbix corosync pacemaker pcs.cman
原文地址:http://metis.blog.51cto.com/1203503/1967400