标签:网络层 dns idt 恢复 列操作 框架 部分 一键 str
为什么选择混合云架构?
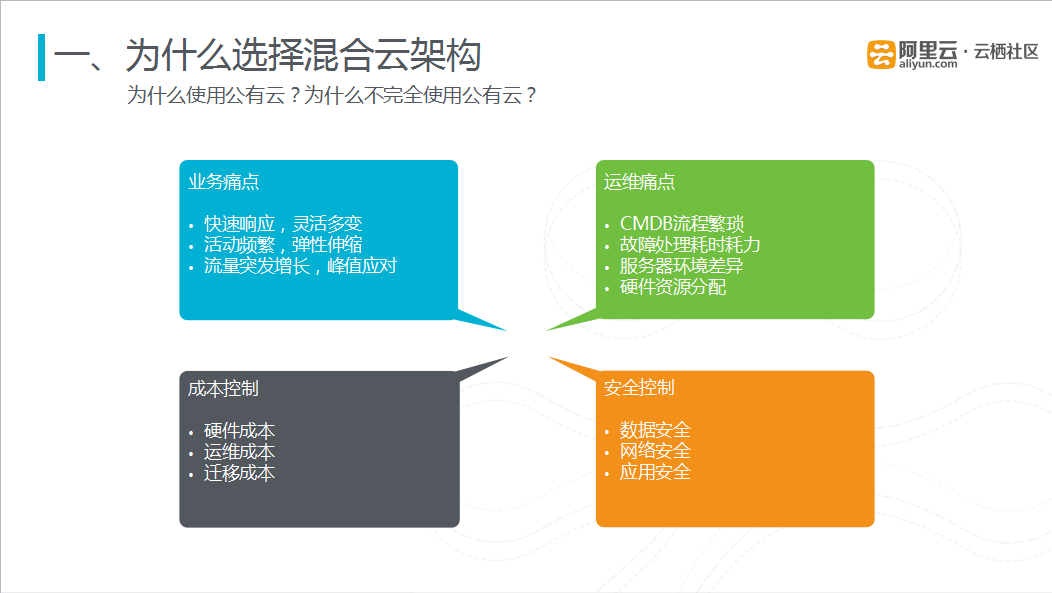
图一 为何选择混合云架构?
为什么选择混合云架构这个问题可以拆成两个问题,一是为什么使用公共云?另一个问题就是为什么不完全使用公共云,为什么还保留原来的IDC?采用这种混合云的架构是基于以下几个痛点考虑的:
- 业务痛点:对于互联网的业务而言,企业必须做到快速响应业务需求,同时互联网业务需求是灵活多变的,传统IDC模式很难保证在短时间内上线一款新的应用。对于公共云来说,其具有的弹性伸缩能力,能应对频繁业务活动;同时像双十一之类的对于流量突发增长活动,公共云可以采取峰值应对,弥补传统IDC的不足;
- 运维痛点:对于传统的IDC,要完成一次具体的扩容,必须要从服务器的采购申请,再到服务器的上架,再去安装操作系统,再去部署应用等等一系列操作,十分复杂。同时在扩容过程中,不仅流程过去繁琐,还有可能遇到一系列的问题,比如因为服务器环境差异导致系统故障等问题。这些问题不仅增加了运维过程中的难度,还使得整个系统的可用性大大降低;
- 成本控制:一方面使用公共云可以降低整体的硬件、运维成本;另一方面从传统的IDC迁移到公共云上的迁移成本,包括迁移过程中对系统进行改造和迁移时间的成本。所以基于两者考虑,最后选择了混合云的模式;
- 安全控制:从安全角度出发,采用混合云模式:将前台应用相关计算、缓存节点全部迁移到阿里云上。核心组数据依然保留在IDC中,保障核心数据的安全。
基于混合云的系统架构
图二 基于混合云的系统架构
上图是有货抽象化的混合云系统架构的整个层次结构。中间是整个服务注册中心,主要分为六层。客户端采用多种高可用策略,在客户端完成降级、缓存、Http DNS等操作;客户端下侧的入口层主要涉及智能DNS、高防DDOS、负载均衡、Nginx等;从入口层再往下是网关层,在网关层内完成安全、流控、降级等操作;核心业务服务层完成所有的核心业务逻辑,包括服务注册、服务发现、服务调用等等;从服务层再往下就是缓存层,在缓存层内一是对热点数据进行加速,同时也需要考虑缓存数据的更新时效等问题;最下面一层是数据层,主要的数据存储在MySQL中,同时进行数据双活操作,保证数据的一致性。
六层结构的左侧是垂直运维平台,平台在每一层都有相关的运维监控工作,右边是基于大数据平台的数据分析系统。
图三 客户端
下面来具体对每一层架构进行分析。在客户端:
- 通过使用HttpDNS,解决LocalDNS的潜在问题。在移动端采取Http直连的模式,防止DNS劫持问题,通过HttpDNS Server获取后端服务的IP列表,避免LocalDNS缓存问题,避免域名解析慢或者解析失败,能快速应对故障处理。同时在高可用方面,混合云的模式下,如果其中一个数据中心出现问题时,可以通过HttpDNS快速进行流量切换;
- 在前端使用阿里云的CDN加速图片、Js等静态资源,极大的提升了用户体验;
- App客户端通过Cache-Control HTTP头来定义自己的缓存策略,通过预加载和客户端缓存,实现离线化,大幅度提升性能;
- 服务降级,客户端根据降级策略可在特定条件下对非关键业务进行降级,以保证核心关键业务的高可用;
- 对网络质量监测,根据用户在2G/3G/4G/Wi-Fi等不同网络环境下设置不同的超时参数,以及网络服务的并发数量。同时根据不同的网络质量设计不同的产品体验;
- 业务异常监测,在客户端监测用户使用过程中的异常情况、快照信息,实时上报异常数据,实时定位分析问题;
- 如果App出现大面积故障,可快速切换至Web App模式,保障了系统的高可用。
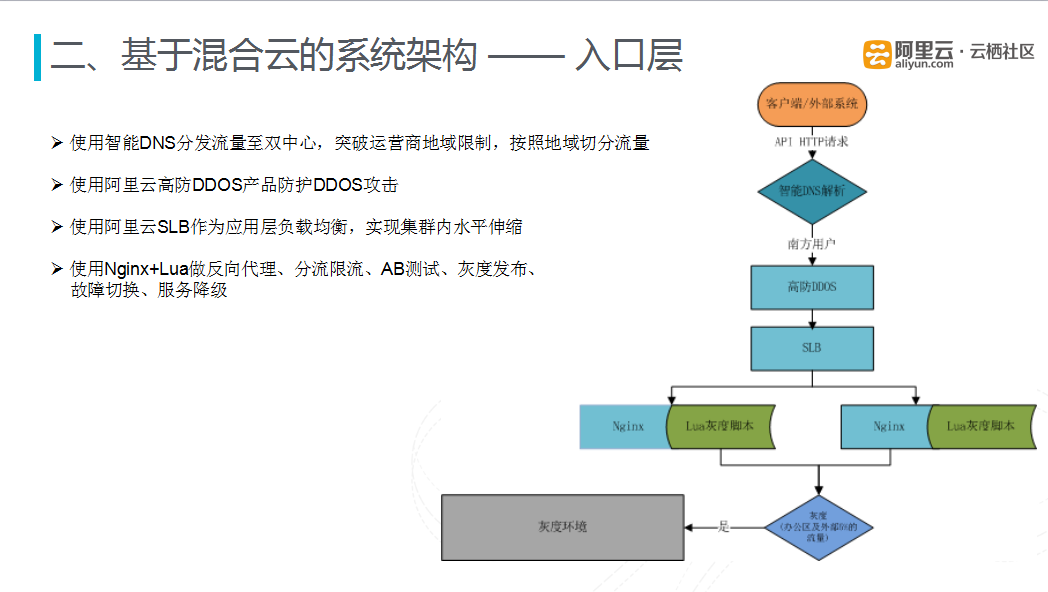
图四 入口层
入口层使用智能DNS分发流量至混合云的双数据中心,将应用做成无状态模式,在两个应用中心做对等的部署,突破运营商地域限制,按照地域切分流量,比如将南方的数据流量切入到阿里云上,将北方的流量切换到自建的IDC中。
安全方面,使用阿里云高防DDOS产品防护DDoS攻击。使用阿里云负载均衡作为应用层负载均衡,实现集群内水平伸缩,同时结合阿里云的云服务器,很好地应对流量高峰时、高峰过后的复杂情况。此外,接口层还使用自建Nginx+Lua做反向代理、分流限流、AB测试、灰度发布、故障切换、服务降级等处理措施。
图五 网关层
入口层之下的网关层内也做了很多措施来保障系统高可用性。安全控制方面,在网关层统一完成客户端请求的身份认证,统一完成数据的加密解密;分流与限流方面,将流量按业务切分,路由至后端不同业务线的服务中心,以实现后端服务的实时动态水平扩展。当流量超过预定阀值,系统出现瓶颈的时候自动限制流量进入后端服务,以防止雪崩效应。服务降级方面,在系统出现瓶颈是,自动降级非关键业务,以保证核心业务的正常运转。
熔断机制方面,根据后端服务的健康状况,自动熔断对服务的调用,以防止雪崩效应。异步化方面,网关异步化调用后端服务,避免长期占用请求线程,快速响应处理结果,快速释放线程资源。
在网关层,一级缓存用于加速热点数据;二级缓存用户容灾。请求进入网络层后首先调用一级缓存,如果一级缓存命中,直接将结果返回给客户端;如果没有命中,网关层会调用后端服务,从服务中返回数据,在这个过程中如果服务出现故障无法访问时,网关会访问二级缓存,因为二级缓存是用于容灾处理,所以二级缓存的时间非常长,数据保存24小时。
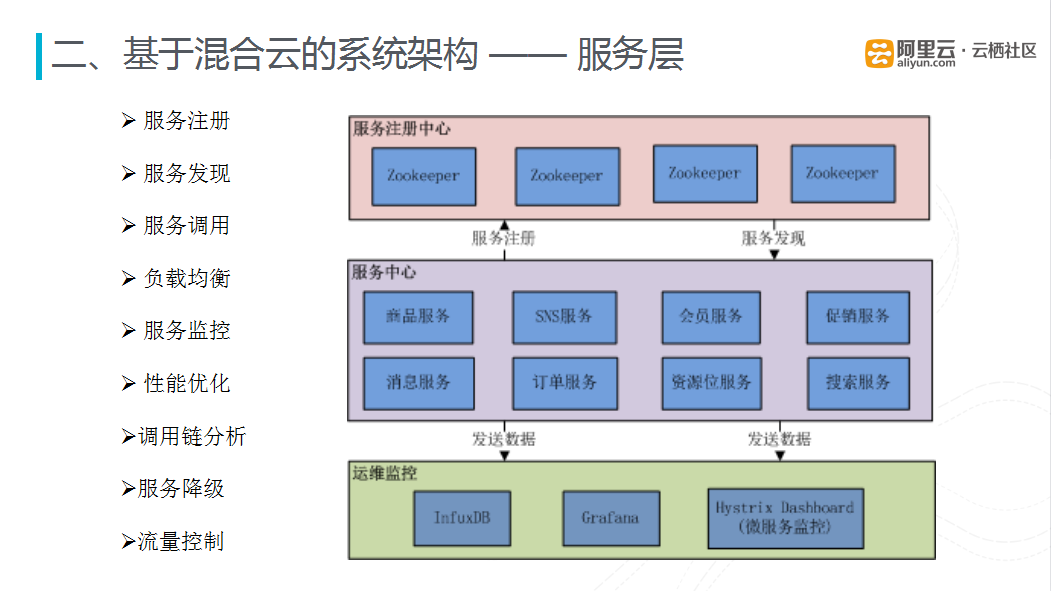
图六 服务层
服务层主要用于服务化的改造,将在之后的服务化章节详解讲解。
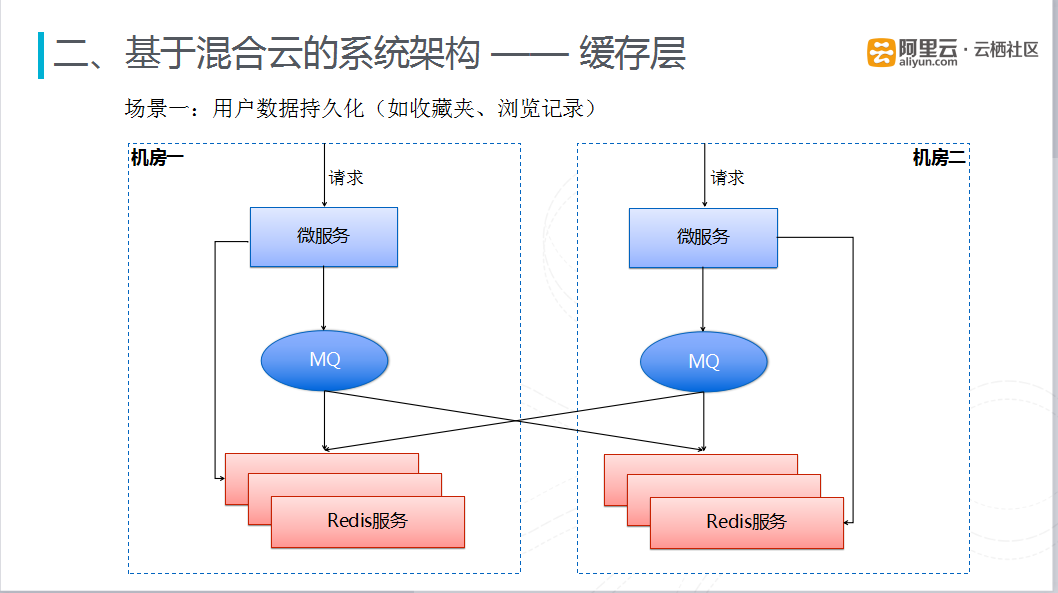
图七 缓存层-用户数据持久化场景
在不同的场景下,采用不同的缓存策略。在用户数据(收藏夹、浏览记录)持久化场景中,采用混合云双数据中心完全对等的部署方式、做双写双活。每个数据中心微服务将数据写入缓存时,均是将数据发送到当前数据中心的MQ中,读取数据是直接从当前数据中心的Redis集群读取。Redis集群同时订阅两个数据中心的MQ的数据,确保两个数据中心部署的Redis集群完全对等,同时Redis集群中的数据也是全量数据,当一个数据中心出现问题时,可以将流量切换到另一个数据中心。
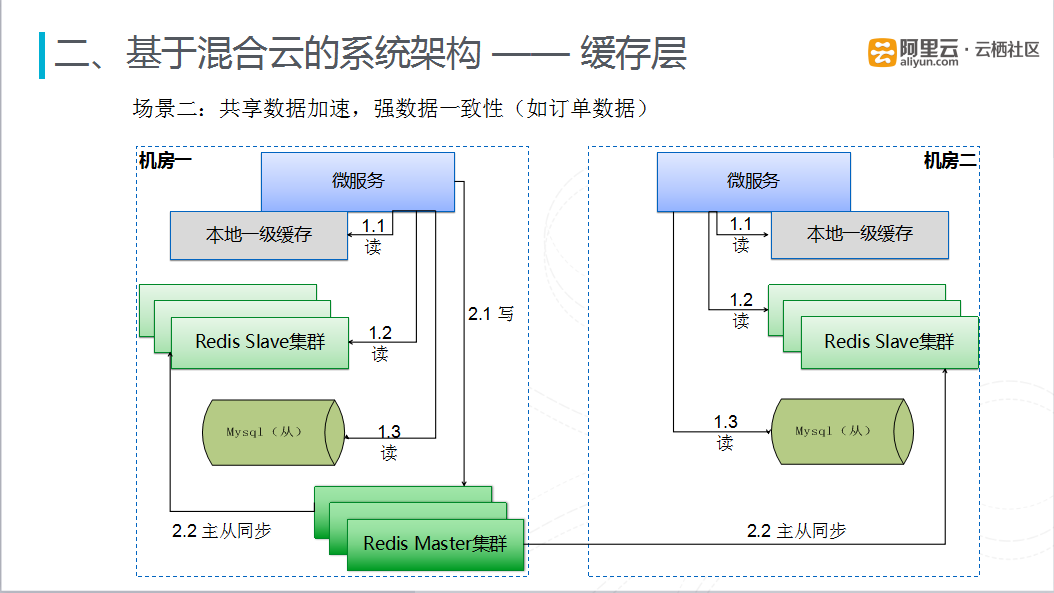
图八 缓存层-共享数据加速,保持数据一致性场景
在共享数据加速,保持数据(如订单数据)一致性的场景下,采用单主多从的缓存模式,在两个数据中心更新缓存时,是先写到一个Redis Master集群中,然后从一个Redis Master集群同步到两个数据中心的Redis Slave集群中,整个请求的逻辑就是:请求进入其中一个机房的微服务中,微服务首先会读取微服务本地的一级缓存,如果没有命中,再去本数据中心的Redis Slave集群进行查询,如果还是没有命中,再回源到本数据中心的数据库中进行查询,将读取后的数据写入到Redis Master集群,同时更新本地的一级缓存和Redis Slave集群,当然Redis Master集群也会将数据同步更新到另一个数据中心的Redis Slave集群中。这种单写多读的缓存模式实现数据加速以及保证数据一致性的要求。目前这种跨机房的主从同步延时并不明显,延迟在一两毫秒左右。
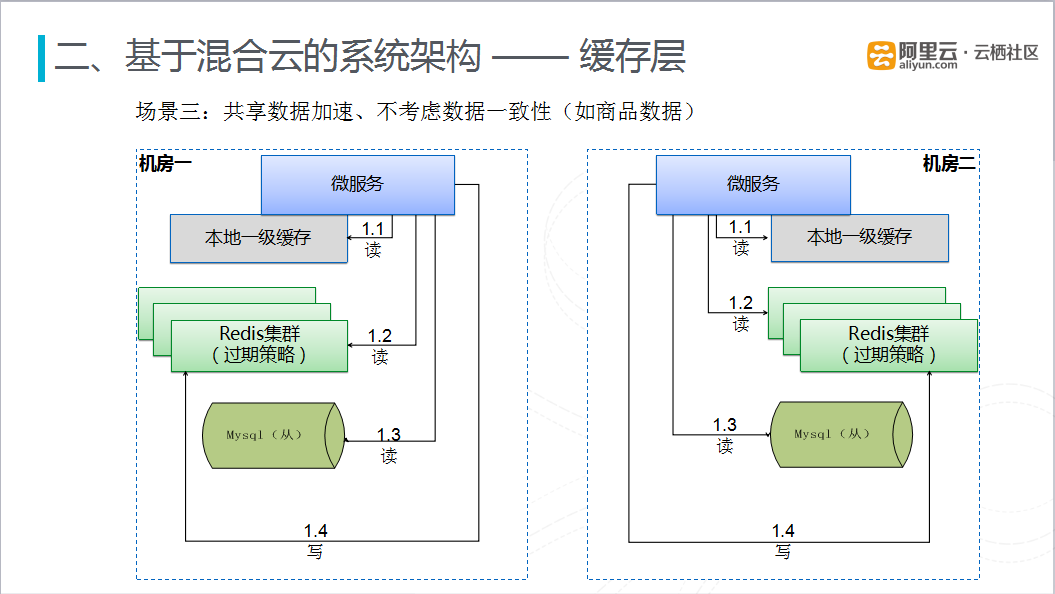
图九 缓存层-共享数据加速但不考虑数据致性场景
在共享数据加速但不考虑数据(商品)一致性的场景下,也是采用多活的理念,即在两个数据中心部署完全对等的缓存集群。在上图的机房一中,当有数据请求时,首先从本地一级缓存进行查询,如果没有命中,再去查本地的Redis集群,依旧没有命中时,回源到本地的数据库进行查询,同时将查询到的数据更新到本数据中心的Redis集群。虽然两个数据中心的缓存集群部署一致,但是在Redis集群中存的数据可能不一致。
图十 数据层
数据层作为六层架构中的最底层,主要的应用还是基于MySQL的主从模式。下面提到的特点是在非核心业务上的一些尝试,并没有大面积应用:
- 同城双活,即由业务层来控制数据的实时性和最终一致性,而不是通过数据同步来保证实时性和一致性。
- 业务层双写,数据异步分发至两个数据中心,任意机房写入的数据通过异步消息的方式分发到另一个机房,以此来保证两个机房数据的最终一致性。
- 业务层通过二级查询保证数据的实时一致性,由于业务层双写只能保证数据的最终一致性,无法保证实时一致性,因此,针对具有实时一致性要求的业务场景,我们通过业务层的二级查询来保证。
- 重复写入应对单机房故障,当任意机房出现故障时,如果写入的数据还没有分发至另一个机房,则由业务层在可用机房重复写入数据,通过算法来生成相同的ID。
- 通过failover库为高可用提供双重保险,针对流水型业务数据,在数据库故障时,需要进行主从切换,此时通过业务层将所有数据的读写切换至failover库,主库恢复以后再将流量切回主库。
- 垂直拆分与水平拆分结合使用。
服务化
之所以需要服务化,是因为在做服务化之前系统高度耦合,牵一发而动全身,直接影响到系统可用性;同时业务相互影响,系统很难维护;系统逻辑过于耦合,很难进行水平扩展;也无法通过流控、降级等手段保障系统的可用性;此外由于系统的高度耦合,极易产生雪崩效应。因此基于上述原因,服务化改造势在必行。
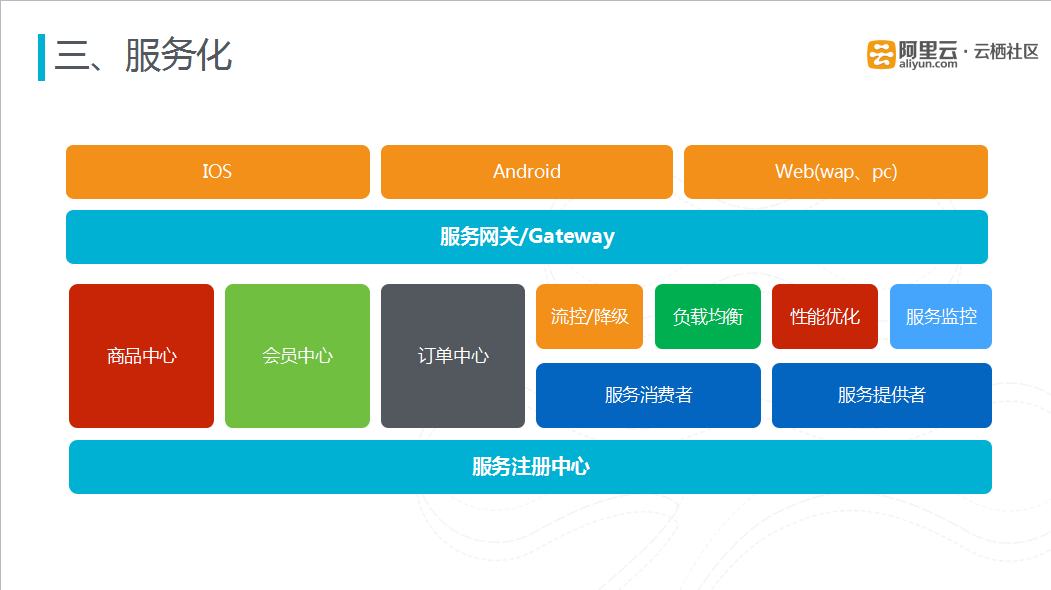
图十一 服务系统框架
上图是服务化系统的架构,最上面一层是客户端,客户端下面就是服务网关层,再往下就是具体的业务服务中心,目前对电商而言三大核心就是商品、会员、订单中心。围绕服务中中心的是一些服务治理策略,如流控/降级、负载均衡等。系统的最低层是服务注册中心。
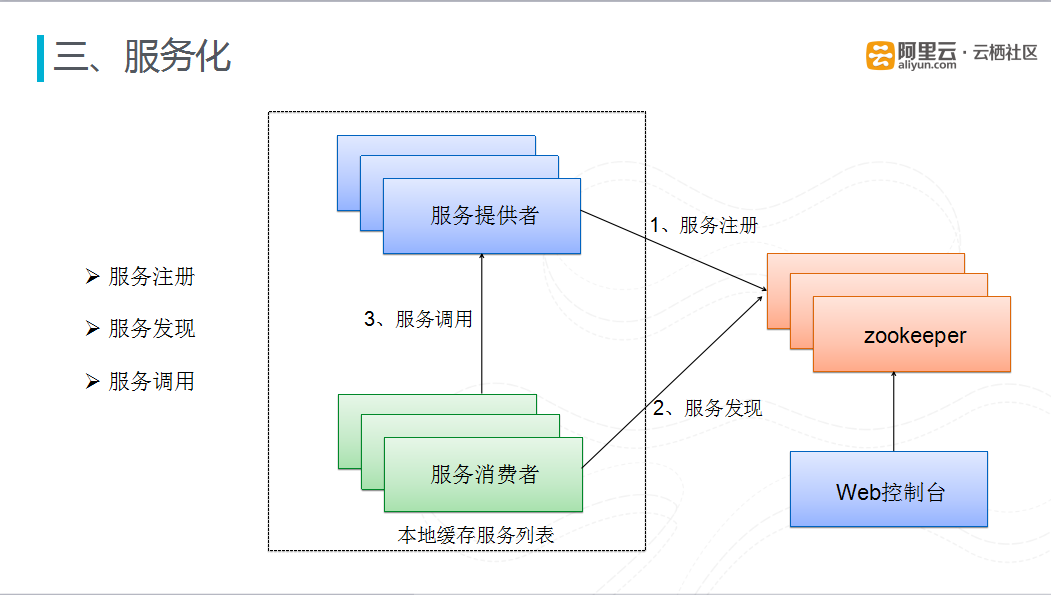
图十二 服务注册、发现、调用
对于服务化而言,最核心的就是服务的发现、注册、调用。目前有货采用的是Spring+Register+Zookeeper搭建的最简单的服务框架,通过Zookeeper完成的服务注册和发现,通过Register完成服务的调用。
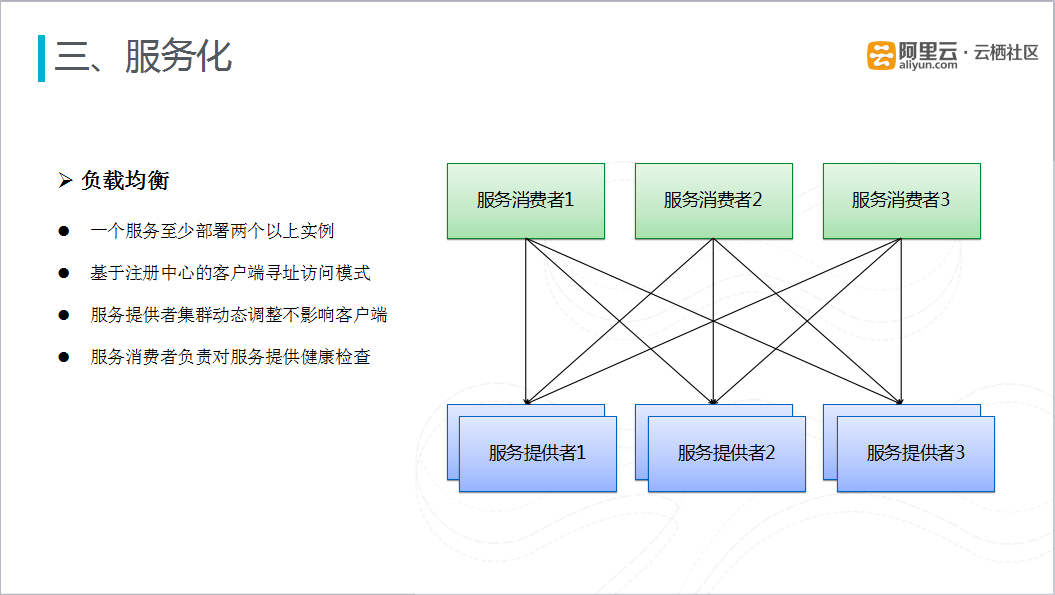
图十三 服务化负载均衡
服务化还有一个很重要的要求就是服务化负载均衡,一般是有两种方案:
- 集中式的LoadBalance,在服务消费者和提供者之间通过阿里云的负载均衡或者F5搭建独立的LoadBalance,通过集中式的负载均衡设备完成对服务调用的负载均衡;
- 在进程内做负载均衡,即软负载的方式,将负载均衡策略渗入到服务框架里面,服务消费者作为负载均衡的客户端,请求只需要从服务注册中心获取最新的服务列表,利用服务框架自身携带的负载均衡策略,完成负载均衡的调用。
图十四 服务降级和流量控制
在服务降级方面,通过使用开源的Hystrix配置服务超时时间,当服务调用超时时,直接返回或执行Fallback逻辑。另外基于Hystrix提供的熔断器组件,可以自动运行或手动调用对当前服务进行暂停后再重新调用服务。流量控制方面,通过计数器服务限定单位时间内当前服务的最大调用次数(比如600次/分钟),如果超过则拒绝,以保证系统的可用性;同时为每个服务提供一个小的线程池,如果线程池已满,调用将被立即拒绝,默认不采用排队,加速失败判定时间。
图十五 服务化的监控、优化、调用链分析
服务化中,对于服务的监控、性能优化以及调用链的分析也尤为重要。通过Hystrix提供的服务化监控工具实时观察在线服务的运行状态,有了监控之后可以进行相应的性能优化。对于调用链分析,当请求从网关层进入时,追加一个Trace ID,Trace ID会在整个调用过程中保留,最后通过分析Trace ID将整个请求的调用链串联起来。
自动化运维平台
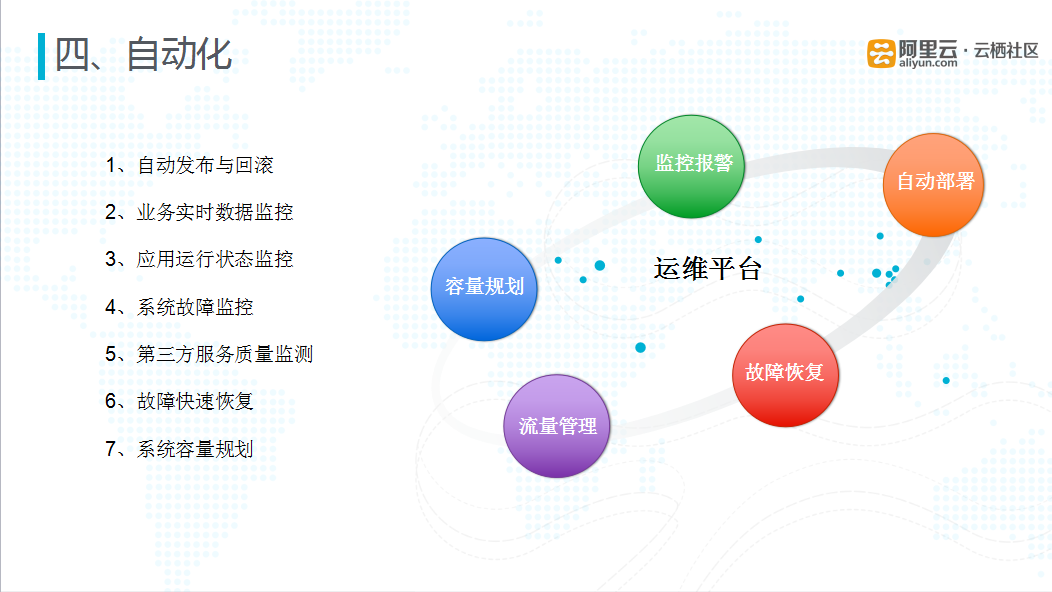
图十六 自动化运维
目前采用的混合云双数据中心模式,如果依旧采用传统的手工部署应用,做文件拷贝、同步等工作,很容易出现版本不一致、文件更新异常等问题。因此在混合云模式下构建自动化运维平台需要考虑以下核心问题:
- 首先在运维平台上要能完成对双云的一键式的自动化部署发布,以及部署失败后的一键快速回滚;
- 在运维平台中需要完成对流量的管理控制,可以完成对整个应用系统的容量规划;
- 最核心的部分是运维平台实现监控和报警,包括对业务层级监控、应用系统的监控、以及系统层级的IO、磁盘、网络的监控。
- 在运维平台中,需要做到应对故障快速恢复的预案,分析系统可能出现的故障点,在出现故障时,通过自动化的脚本对故障进行恢复。
QA环节:
1、有货历史架构的演变历程,达到什么样的规模时才选用混合云模式?
答:企业到了一定阶段,需要去考虑效率和成本时,以及系统的稳定性,自然会选择混合云的方式,目前是将需要弹性伸缩、流量突发的业务迁移到公共云上,后台运营等相对稳定的业务保留在传统的IDC。当流量访问并发达到500-1000时,通过IDC中增加物理机支撑带来维护和成本上的问题时,去考虑选择混合云模式。
2、如何完成多中心的自动化部署?
答:有货在这一方面做的比较简单,通过简单的脚本方式,使用Shell脚本打通版本管理、编译打包、目标服务器,将它们串联起来,在此基础之上,再简单的封装一个图形化的界面,方便操作和权限控制,底层就是调用这一套脚本来完成的。
3、为什么要进行异地的双写,这样做成本是不是比较高?
答:异地的双写是针对不同的应用场景,对一些实时性和一致性要求很是很高的场景,整个应用允许一定的延迟,可以选择异地双写。异地双写的成本是非常高的,目前有货是同城双写,IDC和公共云之间通过专线连接,有效降低了时间延迟。
4、前台后台进了系统解耦,如何做到两者互不影响?
答:刚开始整个应用系统都在一个数据中心部署,前台和后台都采用同一套数据库,后台的批量操作有可能影响到前台的运行。首先需要做数据库的解耦,即前台和后台不共用数据库,目前通过MQ的方式做前后台的数据交互。
5、如何进行合理的服务拆分?
答:目前服务拆分是针对不同的业务线进行的,对于电商来讲,会分为商品、订单、会员等几个大的业务线,业务线对应着各种业务中心,服务中心下面还分布着不同的服务集群,目前采用的是面向领域的模式进行拆分。例如商品服务,将商品的价格、库存等销售属性和非销售属性分别拆成不同的模型,针对不同的模型,进行提供服务。
6、保证系统高可用的核心理念?
答:核心理念不是让系统很稳健,不出故障。而是恰恰相反,任何系统的节点,软件或者硬件出现故障时,整个系统依旧可用,即某一点的故障不使得整个系统瘫痪。
关于分享者:
李健 有货CTO
有货旨打造中国潮流生态圈,其核心业务包括有货App、YOHO、Mars应用。有货也积极举办线下活动,例如举办潮流嘉年华等活动。YOHO!将在2016年5月在艾尚开3000平方米的旗舰店,将集理发、拍照、咖啡、读书等为一体。该店将采用完全的电子货架,也是全球唯一一个完全的电子货架模式。
混合云自动化运维平台
标签:网络层 dns idt 恢复 列操作 框架 部分 一键 str
原文地址:http://www.cnblogs.com/webgrip/p/7581676.html