标签:bat pen gets select comm sql语句 一对多 技术分享 cto
1. 延迟加载
resultMap可实现高级映射:association、collection具备延迟加载功能。
延迟加载:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
(1)使用collection 实现延迟加载
查询用户地址,在关联用户表查询用户名。
用户表实体:
package cn.happy.entity;
import java.util.ArrayList;
import java.util.List;
public class DeptOne {
private Integer id;
private String loginName;//登录名
private String userName;//真实姓名
private Coder code;//用户地址(用户地址表)
public Coder getCode() {
return code;
}
public void setCode(Coder code) {
this.code = code;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLoginName() {
return loginName;
}
public void setLoginName(String loginName) {
this.loginName = loginName;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
}
用户地址表:
package cn.happy.entity;
import java.util.ArrayList;
import java.util.List;
public class Coder {
private Integer id;//编号
private Integer userid;//用户表id
private String address;//地址
private List<DeptOne> dept=new ArrayList<DeptOne>();//用户集合
public List<DeptOne> getDept() {
return dept;
}
public void setDept(List<DeptOne> dept) {
this.dept = dept;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getUserid() {
return userid;
}
public void setUserid(Integer userid) {
this.userid = userid;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
dao层方法:
package cn.happy.dao;
import cn.happy.entity.Coder;
public interface ICoderOneDAO {
public Coder getByMonyCoderId(int id);
}
小配置 dao层的 .xml 方法:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--映射文件的根节点
namespace
-->
<mapper namespace="cn.happy.dao.ICoderOneDAO">
<resultMap id="CoderMonyMapper" type="Coder" >
<id column="id" property="id"></id>
<result column="address" property="address"></result>
<collection property="dept" ofType="DeptOne" select="MonyFindById" column="id">
</collection>
</resultMap>
//这是查询用户名的方法
<select id="MonyFindById" resultType="DeptOne">
SELECT id,userName FROM easyby_user
where id=#{id}
</select>
//这是只查询用户地址的方法
<select id="getByMonyCoderId" resultMap="CoderMonyMapper">
SELECT id,address FROM easybuy_user_address
where id=#{id}
</select>
</mapper>
打开延迟加载:在 大配置 mybatis-config.xml 的里头配置。。。。。。。。。。
<settings>
<setting name="lazyLoadingEnabled" value="true"></setting>
<!-- 打开延迟加载的开关 -->
<setting name="aggressiveLazyLoading" value="false"></setting>
<!-- 将积极加载改为消息加载即按需加载 -->
</settings>
延迟加载实现========使用单侧:
//一对多 多个sql
@Test
public void getByMonyCoderId() throws IOException {
SqlSession session = sessionFactory.getSqlSession();
ICoderOneDAO mapper = session.getMapper(ICoderOneDAO.class);
Coder code = mapper.getByMonyCoderId(1);
System.out.println(code.getAddress());
for (DeptOne dept: code.getDept()) {
System.out.println(dept.getUserName());
}
session.close();
}
如果你使用的是idea 工具,那么像实现延迟加载 需要 上面的依赖。
单侧的结果:
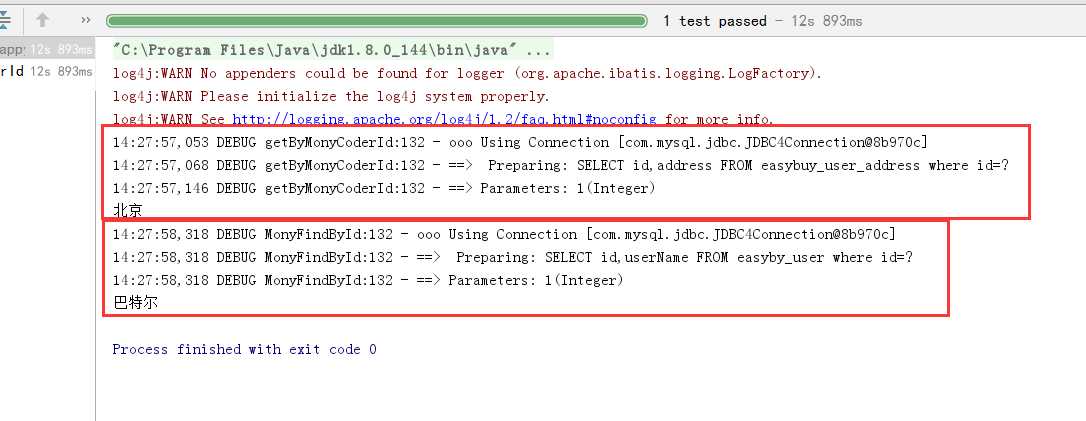
这就是延迟加载, 先 执行对 用户地址的加载,在加载 用户名。
2.一级缓存
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,我们使用mybatis的一级缓存。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存。
(1)证明一级缓存的 存在
查询用户名的方法
dao层:
public interface IDeptOneDAO {
public DeptOne getByno(int id);
}
dao层的 xml 文件:
<mapper namespace="cn.happy.dao.IDeptOneDAO">
<resultMap id="DeptMapper" type="DeptOne">
<id column="id" property="id"></id>
<result column="userName" property="userName"></result>
<association property="code" javaType="Coder">
<id column="id" property="id"></id>
<result column="address" property="address"></result>
</association>
</resultMap>
<select id="getByno" resultMap="DeptMapper">
SELECT easybuy_user_address.id,address,easyby_user.id,userName FROM easyby_user,easybuy_user_address
where easybuy_user_address.userid=easyby_user.id AND easyby_user.id=#{id}
</select>
</mapper>
单侧的方法:
@Test
public void onefind() throws IOException {
SqlSession session = sessionFactory.getSqlSession();
IDeptOneDAO mapper = session.getMapper(IDeptOneDAO.class);
DeptOne dept = mapper.getByno(1);
System.out.println(dept.getUserName());
//第一次查询完毕
System.out.println("=============中间分割线===============");
//第二次查询开始
IDeptOneDAO mapper2= session.getMapper(IDeptOneDAO.class);
DeptOne dept2 = mapper2.getByno(1);
System.out.println(dept2.getUserName());
session.close();
}
查看结果:
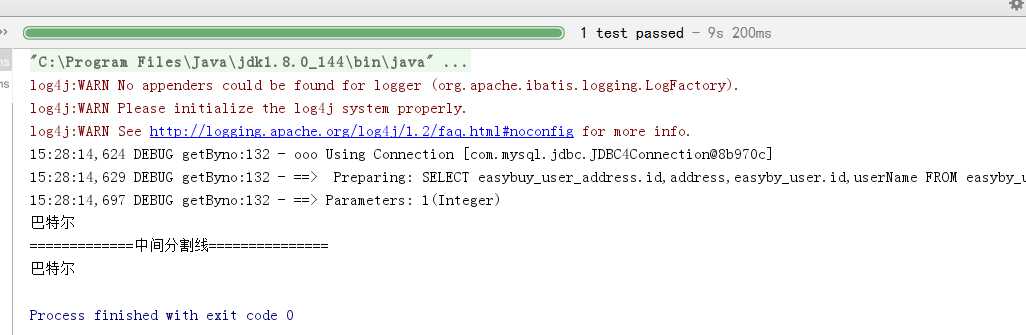
查看结果,第一次是查询数据获得结果。第二次是没有走数据库的。证明一级缓存的存在。
3. 二级缓存
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
在这里我说明,在mybatis中二级缓存是默认开启的。
mybatis-----的延迟加载-----缓存(一级缓存和二级缓存)
标签:bat pen gets select comm sql语句 一对多 技术分享 cto
原文地址:http://www.cnblogs.com/bb1008/p/7581914.html