标签:工作 命令 bsp 分享 应该 evel 时间序列 回归 显示
一、拟合
1、自动拟合模型
要使用auto.arima( )函数需要先下载zoo和forecast程序包,并用library调用这两个程序包。auto.arima()函数的命令格式如下
auto.arima(x, max.p=5, max.q=, ic=)
其中:
-x:需要定阶的序列名。
-max.p:自相关系数最高阶数,不特殊指定的话,系统默认值为5。
-max.q:自相关系数最高阶数,不特殊指定的话,系统默认值为5。
-ic:指定信息量准则。ic有三个选项"aicc","aic"和"bic"。
2、人为设定模型
如果不是通过auto.arima()函数自动定阶并自动得到模型的拟合结果,通常我们需要分两步来完成auto.arima()函数自动完成的工作。第一步就是模型定阶,第二步就是参数估计。参数估计通过arima( )函数完成,该函数的命令格式为:
arima(x, order = , include.mean = , method = )
-x:要进行模型拟合的序列名
-order:指定模型阶数。order =c(p,d,q),p为自回归阶数,d为差分阶数,本章不涉及差分问题,所以d=0,q为移动平均阶数。
-include.mean :要不要常数项。include.mean =T需要拟合常数项,这也是系统默认设置。如果不需要拟合常数项,需要特别指定include.mean =F。
-method :指定参数估计方法,默认的是条件最小二乘与极大似然估计结合的方法method="CSS-ML" ,也可以特别指定为极大似然估计方法method="ML", 或者条件最小二乘估计方法method="CSS"。
二、显著性检验
1、参数的显著性检验
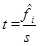
调用t分布P值函数pt( )即可获得该统计量的P值。pt( )函数的命令格式为
pt(t, df=, lower.tail=)
其中:
-t:t统计量的值
-df:自由度
-lower.tail:确定计算概率的方向。如果lower.tail=T,计算Pr(X ≤ x)。反之lower.tail=F,计算Pr(X >x)。对于参数检验,如果参数估计值为正,选择lower.tail=F,如果参数估计值为负,选择lower.tail=F。
2、方程的显著性检验:
白噪声检验
假如残差序列的白噪声检验结果显示,残差为非白噪声序列。这意味着拟合模型对信息的提取不够充分,残差序列里蕴含着值得进一步提取的相关信息。这时可以调用tsdiag( )函数,诊断一下残差序列残存的相关信息特征。tsdiag( )函数的命令格式为:
tsdiag(object)
其中:
-object:拟合信息文件名。例:x.fit
如果:
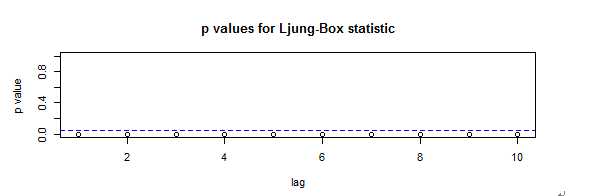
我们应该重新定阶,重新拟合模型。
三、预测
如果拟合模型通过了白噪声检验,我们可以使用该模型进行序列预测。在下载并调用forecast包之后。我们可以调用forecast( )函数完成预测工作。
forecast( )函数的命令格式为
forecast(object, h = , level=)
其中:
-object:拟合信息文件名
-h:预测期数
-level:置信区间的置信水平。不特殊指定的话,系统会自动给出置信水平分别为80%和95%的双层置信区间。
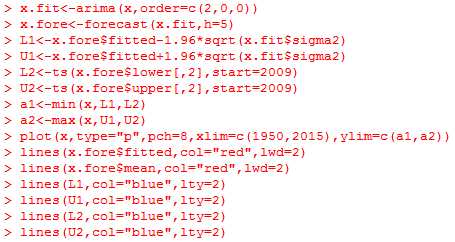
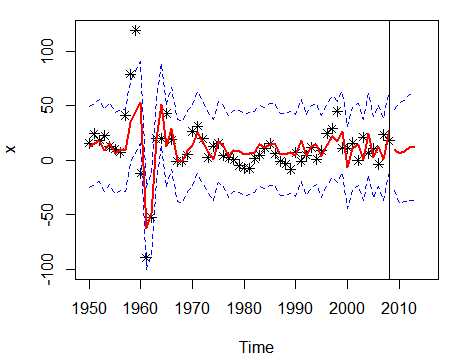
使用如下命令可以获得图3-21:
标签:工作 命令 bsp 分享 应该 evel 时间序列 回归 显示
原文地址:http://www.cnblogs.com/EXODUS1917/p/7582710.html