标签:gre 占位符 float bat 创建 输出 标签 cross 浮点
TensorFlow官方文档MNIST初学笔记[二]
MNIST是一个简单的计算机视觉数据集, 它还包括每个图像的标签, 每个图像是28像素乘以28像素, 我们可以把这个数组变成一个28×28 = 784个数字的向量。MNIST只是一个784维向量空间中的一个点。mnist.train.images具有形状的张量(n维阵列)[55000, 784]
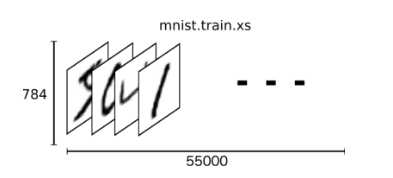
第一维度是图像列表中的索引,第二维度是每个图像中每个像素的索引。对于特定图像中的特定像素,张量中的每个条目是0和1之间的像素强度。
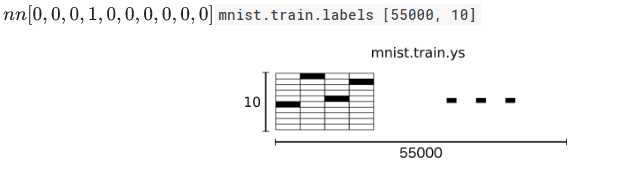
MNIST中的每个图像都有一个相应的标签,0到9之间的数字表示图像中绘制的数字。
softmax给出了一个0到1之间的值列表,加起来为1,当我们训练更复杂模型,最后一步将是softmax的一层。softmax其实就是,e^每个输出结果,然后归一化
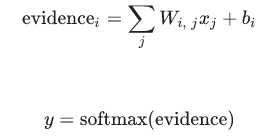
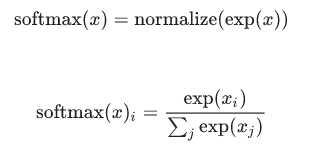
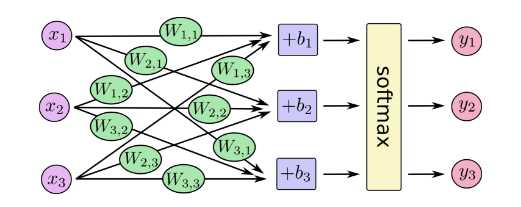
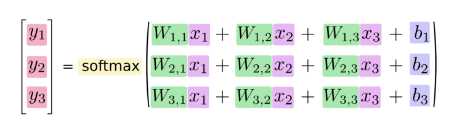
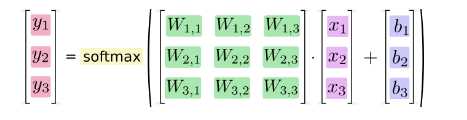
更紧凑,我们可以写:
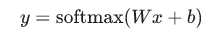
现在我们来看看TensorFlow可以使用的东西。
为了在Python中进行有效的数值计算,我们通常使用像NumPy这样的数据库 ,可以使用诸如Python之外的矩阵乘法等昂贵的操作,使用其他语言实现的高效代码。不幸的是,每次操作都需要重新切换到Python的开销很大。如果要在GPU上运行计算或以分布式方式运行计算,那么这种开销尤其糟糕,传输数据的成本很高。TensorFlow也在Python之外进行了大量的工作,但它需要进一步的工作来避免这种开销。TensorFlow不是独立于Python运行单一昂贵的操作,而是可以描述完全在Python之外运行的交互操作的图形。(这样的方法可以在几台机器学习库中看到。)
要使用TensorFlow,首先我们需要导入它。
import tensorflow as tf
通过操纵符号变量来描述这些交互操作
x = tf.placeholder(tf.float32, [None, 784])
当我们要求TensorFlow运行计算时,我们将输入一个值。我们希望能够输入任何数量的MNIST图像,每个图像被平铺成784维的向量。我们将其表示为具有形状的浮点数的2-D张量[None, 784]。(这里None表示尺寸可以是任意长度。)
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
W具有[784,10]的形状
我们现在可以实现我们的模型。它只需要一行来定义它!
y = tf.nn.softmax(tf.matmul(x, W) + b)
定义损失函数“交叉熵”
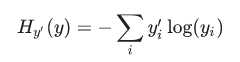
为了实现交叉熵,我们需要先添加一个新的占位符来输入正确答案:
y_ = tf.placeholder(tf.float32, [None, 10])
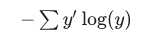
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
tf.log计算每个元素的对数y,接下来,我们将每个元素乘以y_相应的元素tf.log(y)。
tf.reduce_mean计算批次中所有示例的平均值
其中tf.reduce_mean使用方法:
# ‘x‘ is [[1., 1.] # [2., 2.]] tf.reduce_mean(x) ==> 1.5 tf.reduce_mean(x, 0) ==> [1.5, 1.5] tf.reduce_mean(x, 1) ==> [1., 2.]
在源代码中,我们不使用这个公式,因为它在数值上是不稳定的
请考虑使用
tf.nn.softmax_cross_entropy_with_logits
由于TensorFlow知道你计算的整个图形,它可以自动使用 BP算法有效地确定把损失降到最低。然后可以应用您选择的优化算法来修改变量并减少损失。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
在这种情况下,我们要求TensorFlow cross_entropy使用 学习率为0.5 的 梯度下降算法进行最小化。梯度下降是一个简单的过程,其中TensorFlow简单地将每个变量在减少成本的方向上稍微移动一点。
我们现在可以在以下模式中启动InteractiveSession:
sess = tf.InteractiveSession()
首先必须创建一个操作来初始化我们创建的变量:
tf.global_variables_initializer().run()
我们来训练 - 我们将运行1000次训练步骤!
for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
循环的每一步,我们从训练集中得到一百个随机数据点的“批次”。我们运行train_step,feed中的批次数据来代替placeholders。
tf.argmax(y,1)我们的模型认为是每个输入最有可能的标签,而tf.argmax(y_,1)正确的标签。我们可以tf.equal用来检查我们的预测是否符合真相。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这给了我们一个布尔的列表。为了确定哪个部分是正确的,我们转换为浮点数,然后取平均值。例如, [True, False, True, True]会变成[1,0,1,1]哪一个0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
最后,我们要求我们对测试数据的准确性。
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
标签:gre 占位符 float bat 创建 输出 标签 cross 浮点
原文地址:http://www.cnblogs.com/yinghuali/p/7584322.html