标签:技术分享 机器学习 多个 png 最小 size img imu ...
Iris数据集(鸢尾花数据集):包含不同种类Iris花朵的数据,可以通过花的形态来识别花的种类。数据集包含花的四个属性(特征):花萼长度,花萼宽度,花瓣长度,花瓣宽度。
sklearn中的iris数据集有5个key: [‘target_names’, ‘data’, ‘target’, ‘DESCR’, ‘feature_names’]
(1)其中target_names 是分类名称 :[‘setosa’ ‘versicolor’ ‘virginica’],即分别为山鸢尾花,变色鸢尾花和维吉尼亚鸢尾花。
(2)data存储着四种特征的数据,如下所示:
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
………………………
[ 6.2 3.4 5.4 2.3]
[ 5.9 3. 5.1 1.8]]
(3)target对应着每一行数据的类别,分别为“0”,“1”,“2”,一个150个
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
(4)feature_names表示特征名称
(‘feature_names:’, [‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’])
(5)DESCR:对这个数据集的描述
1.1 可视化
目标:在4种特征的数据中抽取两种特征数据,在二维平面中绘出。
代码:
# -*- coding: utf-8 -*-
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
import scipy as sp
data=load_iris() #加载数据集
#根据key赋予特征,目标等
features=data[‘data‘]
feature_names=data[‘feature_names‘]
target=data[‘target‘]
target_name=data[‘target_names‘]
labels=data[‘target_names‘][data[‘target‘]]
pairs = [(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)] #4种抽取两两对
for i,(p0,p1) in enumerate(pairs):
plt.subplot(2,3,i+1) #subplot是将多个图画到一个平面上的工具
for t,marker,c in zip(range(3),">ox","rgb"):
plt.scatter(features[target == t,p0],
features[target == t,p1],
marker=marker,
c=c)
plt.xlabel(feature_names[p0])
plt.ylabel(feature_names[p1])
plt.xticks([])
plt.yticks([])
plt.show()
运行结果:
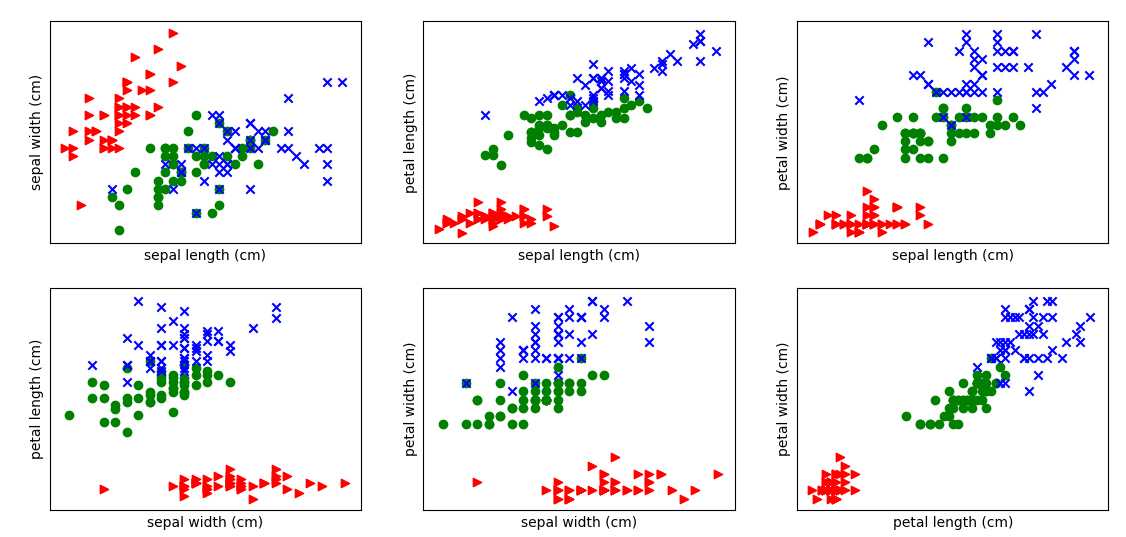
函数说明:
A.zip():zip函数接受任意多个序列作为参数,返回一个tuple列表。
x = [1, 2, 3]
y = [4, 5, 6]
z = [7, 8, 9]
xyz = zip(x, y, z) #xyz=[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
B. enumerate():enumerate函数用于遍历序列中的元素以及它们的下标。
C.for t,marker,c in zip(range(3),">ox","rgb")的使用:
用红色三角形标记山鸢尾花,绿色圆圈表示变色鸢尾花,蓝色叉表示维吉尼亚鸢尾花。
(1)将山鸢尾花(Iris Setosa)与其它两类分开
通过上面的图形可以明显看出Setosa与其他两类花的区别,通过下面代码可以找出切分点。
思路:只用花瓣的长度去判断,找出Setosa的最大长度和其他种类花花瓣的最小长度。
plength=features[:,2] #第三个特征代表花瓣长度,只用它去判断 is_setosa=(target==0) #将setosa的数据提取出来 setosa_plength=plength[is_setosa] other_plength=plength[~is_setosa] max_setosa=setosa_plength.max() #找出 setosa 花瓣的最大长度 min_non_setosa=other_plength.min() #非setosa花瓣的最小长度 print(‘Maximun of setosa: {0}.‘.format(max_setosa)) #输出值是1.9 print(‘Minimum of others: {0}.‘.format(min_non_setosa)) #输出值是3.0
可以得到1.9和3.0,利用它构建一个简单的分类模型:如果花瓣长度小于2,那么它是山鸢尾花。
for n in range(150): if features[n,2]<2:print ‘It is Setosa‘ else:print ‘others‘
(2)将变色鸢尾花(Versicolor)和维吉尼亚鸢尾花(Virginica)分开
思路:
1.在非Setosa的鸢尾花抽取Virginica;
2.对可能的特征和阈值进行遍历,找出最高的正确率。
features=features[~is_setosa] #[[ 7. 3.2 4.7 1.4]...] 将不是setosa的输出 labels = labels[~is_setosa] #[[‘versicolor‘...‘virginica‘...] 将其他两种标签输出 virginica = (labels == ‘virginica‘) #[False...True...] best_acc=-1.0 for fi in xrange(features.shape[1]): #features.shape[1]=4 thresh=features[:,fi].copy() thresh.sort() for t in thresh: pred=(features[:,fi])>t acc=(pred==virginica).mean() if acc>best_acc: best_acc=acc #准确率 best_fi=fi #选择的特征 best_t=t #选择的阈值 print best_acc,best_fi,best_t
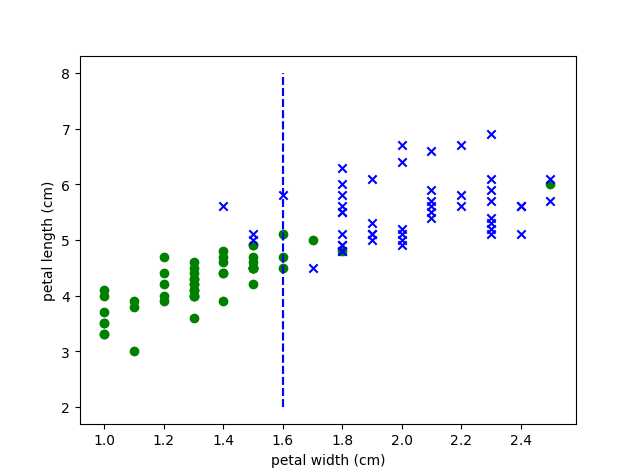
输出:best_acc=0.94;best_fi=3;best_t=1.6。
可知知道最高的准确率为94%,最好的特征为第4个,即花瓣宽度,阈值为1.6。
对这一结果用图形表示:
target2=target[49:149] features=features[0:100] a=[1,2] fx=[best_t]*100 fy=sp.linspace(2,8,100) for t,marker,c in zip(a,"ox","gb"): plt.scatter(features[target2 == t,3], features[target2 == t,2], marker=marker, c=c) plt.plot(fx,fy,"b--") plt.xlabel(feature_names[3]) plt.ylabel(feature_names[2]) plt.xticks() plt.yticks() plt.show()
可以得到下面的图形:
标签:技术分享 机器学习 多个 png 最小 size img imu ...
原文地址:http://www.cnblogs.com/youngsea/p/7581492.html