标签:hle 进制 exist 命令 跳跃表 其他 增加 复杂 friend
今天来学习redis的基础数据类型,redis中一共有五种数据类型,分别是:string,hash,list,set,zset。下面分别进行介绍。
一、string(字符串)
字符串类型是redis最基础的数据类型,它能存储任何形式的字符串,包括二进制数据。一个字符串类型允许存储的数据最大容量是512M。字符串是其他4种数据类型的基础。
1 字符串相关命令
1)GET/SET命令
SET key value #给key赋值 GET key #获取key的值
127.0.0.1:6379> SET str ‘hello,world‘ OK 127.0.0.1:6379> GET str "hello,world"
当键不存在时返回空值。
2)INCR递增命令
字符串类型可以存储任何形式的字符串,当存储的字符串是整数形式时,可以用incr命令让它自动递增。
INCR key 127.0.0.1:6379> INCR bar (integer) 2 127.0.0.1:6379> INCR bar (integer) 3
当键不存在时,会自动创建该键并从0开始递增。
2 字符串实践
1)文章访问量统计
博客常见的一个功能就是统计文章的访问量,这里我们可以为每篇文章使用名为post:id:page.view的键来记录文章的访问量,每次有人访问的时候用incr命令为该键递增。
键的命名规则:对象类型:对象id:对象属性
如:user:1:friends 表示id为1的用户的好友列表,增加易读性和可维护性。
2)生成自增ID
怎么为每篇文章标示一个唯一ID呢?在关系型数据库中可以用auto_increment,但是在redis中可以通过另一种模式实现:对每一类对象使用名为对象类型(复数形式):count的键来存储当前对象类型的数量,没增加一个新对象就对该值进行递增。
3)存储文章数据
文章数据包括标题、内容、发布时间等字段,而我们知道一个字符串类型只能存储一个字符串,那么如何存储文章数据呢?因为字符串类型可以存储二进制数据,可以采用MessagePack进行序列化,速度更快,占用空间更小。下面是伪代码:

#获得新文章ID $postid = INCR posts:count #将博客文章诸多字段序列化成字符串 $serialpost = serialize($posttitle,$content,$author,$time) #将序列化后的文章存储到字符串中 SET post:$postid:data = $serialpost #从redis中读取id=42的文章数据 $serialpost = GET post:42:data #将文章反序列化成各个字段 $posttitle,$content,$author,$time=unserialize($serialpost) #获取文章的访问数量 $count = INCR post:42:page.view
3 字符串相关扩展命令
1)增加指定整数
INCRBY key increment 127.0.0.1:6379> GET goo "2" 127.0.0.1:6379> INCRBY goo 3 (integer) 5
2)减少指定整数
DECR key DECRBY key value 127.0.0.1:6379> GET goo "5" 127.0.0.1:6379> DECR goo (integer) 4 127.0.0.1:6379> DECRBY goo 2 (integer) 2
3)向尾部追加值
APPEND key value,如果该键不存在则将该value设为键的值,返回值是追加后的长度。
127.0.0.1:6379> GET str "hello,world" 127.0.0.1:6379> APPEND str ‘,zhao‘ (integer) 16 127.0.0.1:6379> GET str "hello,world,zhao"
4)获取字符串长度
STRLEN key
127.0.0.1:6379> STRLEN str (integer) 16
5)同时设置/获取多个键值
MGET/MSET key1 key2 ....
127.0.0.1:6379> MGET str goo bar 1) "hello,world,zhao" 2) "2" 3) "3"
二、hash(散列类型)
1、简介
hash类型的键值是字典结构,其存储了字段和字段值的映射,但是字段值只能是字符串,不支持其他类型,也就是说,hash类型不支持类型的嵌套,一个hash类型键最多包括2的32次方-1个字段(除了hash,其他类型也不支持类型嵌套)。
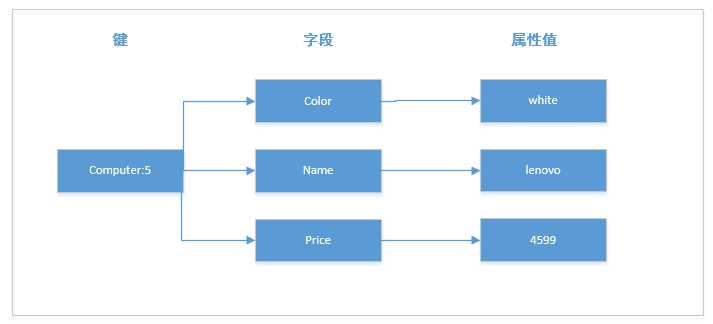
hash类型最适合存储对象了,我们一般使用对象类别:ID表示键名,使用字段表示对象的属性,而字段值存储属性值,下面具体例子:要存储电脑ID为5的对象,可以分别使用名为color,name和price的3个字段来存储该电脑的颜色、名称和价格,存储结构如下图所示:
我们回想下如果用关系型数据库来存储该数据,存储结构应该这样:

这种以二维表的形式存储关系型数据,所有的对象都要有相同的属性,试想,如果我想为ID为1的电脑添加一个保修期限,是不是所有的都需要添加这个属性,那么对于其他的就属于冗余了。而采用redis的hash类型可以自由地为不同对象添加不同的字段和属性。
2、相关命令
1)赋值与取值
HSET key field value HGET key field HMSET key field value [field value ...] HMGET key field [field...] HGETALL key
HSET用来给字段赋值,它不区分是更新还是插入操作,这意味如果着修改数据时无需考虑该字段是否存在,插入操作返回1,更新返回0;HGET获取字段的值,
127.0.0.1:6379> HSET car:1 color red (integer) 1 127.0.0.1:6379> HSET car:1 name BMW (integer) 1 127.0.0.1:6379> HSET car:1 price 1200000 (integer) 1 127.0.0.1:6379> HGET car:1 color "red" 127.0.0.1:6379> HGET car:1 name "BMW" 127.0.0.1:6379> HGET car:1 price "1200000" 127.0.0.1:6379> HGETALL car:1 1) "color" 2) "red" 3) "name" 4) "BMW" 5) "price" 6) "1200000" 127.0.0.1:6379> HSET car:1 color yellow #该字段已存在,故返回状态0 (integer) 0
2)判断字段是否存在
HEXISTS key field #判断字段是否存在,存在返回1,否则返回0,键不存在也返回0 127.0.0.1:6379> hexists car color #键car不存在返回0 (integer) 0 127.0.0.1:6379> hexists car:1 color (integer) 1 127.0.0.1:6379> hexists car:1 color1 #字段color1不存在返回0 (integer) 0
3)当字段不存在时赋值
HSETNX key field value#当字段不存在赋值,返回1;如存在不执行任何操作,返回0;属于原子操作,不会发生竞态条件 127.0.0.1:6379> hsetnx car:1 price 150000 (integer) 0 127.0.0.1:6379> hget car:1 price "1200000" 127.0.0.1:6379> hsetnx car:1 date ‘2015‘ (integer) 1 127.0.0.1:6379> hget car:1 date "2015"
4)增加数字
HINCRBY key field increment #与字符串的incrby相似 127.0.0.1:6379> hincrby car:1 price 1000000 (integer) 2200000
5)删除字段
HDEL key field 127.0.0.1:6379> hgetall car:1 1) "color" 2) "yellow" 3) "name" 4) "BMW" 5) "price" 6) "2200000" 7) "date" 8) "2015" 127.0.0.1:6379> hdel car:1 date (integer) 1 127.0.0.1:6379> hgetall car:1 1) "color" 2) "yellow" 3) "name" 4) "BMW" 5) "price" 6) "2200000"
6)只获取字段名或字段值
hkeys key hvals key 127.0.0.1:6379> hkeys car:1 #获取字段名 1) "color" 2) "name" 3) "price" 127.0.0.1:6379> hvals car:1 #获取字段值 1) "yellow" 2) "BMW" 3) "2200000"
7)获得字段的数量
hlen key 127.0.0.1:6379> hlen car:1 (integer) 3
三、List(列表类型)
1、介绍
列表可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获取列表的一个片段。
redis的列表的内部是用双向链表实现的,故向列表两端添加元素的时间复杂度是O(1),获取越靠近两端的数据速度越快。这意味着即使有一个几千万的列表,获取它的头10条或者尾部10数据也是极快的。不过使用链表的代价是通过索引访问列表元素是很慢的,试想:有3000个人在排队买iphone 6s,这时苹果想找到编号为1699的人,工作人员是不是需要从头或者尾部一个一个数过去啊。但无论队伍有多长,新来的顾客直接加入到队尾就可以了,与队长多少没有任何关系。
这种的特性很好的应用在以下场景:如社交网站的新鲜事,我们只关心最新的内容,使用列表存储,即使它有几千万条,获取前100条也是很快的。同时列表也适合记录日志,可以保证加入新日志的速度不受列表的长度影响。
一个列表类型键最多有2的32次方-1个元素。
2、命令操作
1)向列表两端添加元素
lpush key value [value ...]#向列表左边添加元素,返回列表个数 rpush key value [value...]#向列表右边添加元素,返回列表个数 127.0.0.1:6379> lpush numbers 0 (integer) 1 127.0.0.1:6379> lpush numbers -1 -2 -3 (integer) 4 127.0.0.1:6379> rpush numbers 1 2 3 (integer) 7
2)获取列表片段
lrange key start stop #获取列表一个片段,列表索引是从0开始,包含两边 127.0.0.1:6379> lrange numbers 0 6 1) "-3" 2) "-2" 3) "-1" 4) "0" 5) "1" 6) "2" 7) "3" #lrange支持负索引,0表示最左元素,-1表示从最右面第一个元素 127.0.0.1:6379> lrange numbers -2 -1 #从最右面开始,取两个 1) "2" 2) "3" 127.0.0.1:6379> lrange numbers 0 -1 #取所有元素 1) "-3" 2) "-2" 3) "-1" 4) "0" 5) "1" 6) "2" 7) "3"
3)从列表两端弹出元素
lpop key #从最左面移除元素,返回被移除的元素值 rpop key #从最右面移除元素,返回被移除的元素值 127.0.0.1:6379> lpop numbers "-3" 127.0.0.1:6379> rpop numbers "3"
4)获取列表中元素的个数
llen key 127.0.0.1:6379> llen numbers (integer) 5
5)删除列表中指定的值
lrem key count value
删除列表中前count个值为value的元素,返回值是删除的个数,根据count的不同,执行有所差异:
当count=0时,删除列表中所有值是value的元素
当count>0时,删除从最左边开始,前count个值为value的元素
当count<0时,删除从最右边开始,前|count|个值为value的元素
6)获取/设置指定索引的元素值
lindex key index lset key index value 127.0.0.1:6379> lindex numbers 0 "-2" 127.0.0.1:6379> lset numbers 0 1 OK 127.0.0.1:6379> lindex numbers 0 "1"
7)只保留列表指定片段的元素(也就是删除指定片段之外所有元素)
ltrim key start stop 127.0.0.1:6379> lrange numbers 0 -1 1) "1" 2) "-1" 3) "0" 4) "1" 5) "2" 127.0.0.1:6379> ltrim numbers 1 3 OK 127.0.0.1:6379> lrange numbers 0 -1 1) "-1" 2) "0" 3) "1"
这个很有用,与lpush结合可以只显示最新的100个日志数量,如:
lpush logs $logs ltrim logs 0 99
8)向列表中插入一个元素值
linsert key before/after pvior value#从左到右查找值为pvior,然后根据第二个参数决定在前面还是后面插入,返回元素个数 127.0.0.1:6379> lrange numbers 0 -1 1) "-1" 2) "0" 3) "1" 127.0.0.1:6379> linsert numbers before 0 2 (integer) 4 127.0.0.1:6379> lrange numbers 0 -1 1) "-1" 2) "2" 3) "0" 4) "1"
9)将元素从一个列表转到另一个列表
rpoplpush source destinion #先执行source列表的rpop,然后向新列表中lpush,返回元素值,整个过程原子操作
四、set(集合类型)
1、介绍
集合是一组不重复没有顺序限制的元素,每个集合最多存储2的32次方减1个元素。
集合的常用操作是向集合中加入或删除元素、判断某个元素是否存在。同时不同集合之间还可以进行并集、交集等操作。
2、命令操作
1)增加/删除元素:sadd key member [member...] /srem key member [member...]
127.0.0.1:6379> sadd s1 1 2 3 (integer) 3 127.0.0.1:6379> srem s1 3 (integer) 1 127.0.0.1:6379> smembers s1 #列出集合中所有元素 1) "1" 2) "2"
2)判断元素是否在集合中
#判断元素是否在集合中,如果在返回1,否则返回0 sismember key member 127.0.0.1:6379> sismember s1 1 (integer) 1 127.0.0.1:6379> sismember s1 0 (integer) 0
3)集合间运算
sdiff key1 key2 [key...] #差集 sinter key1 key2 [key...] #交集 sunion key1 key2 [key...] #并集
4)取得集合元素的个数:scard key
5)进行集合运算并将结果存储
sdiffstore key1 key2 [key...] #差集 sinterstore key1 key2 [key...] #交集 sunionstore key1 key2 [key...] #并集
一般用在需要进行多步运算时,可以先把部分结果存储起来再进行下一步运算。
6)随机取得集合元素
srandomember key [count] #count表示多个元素,根据count值不同取得值也不一样 #当count为正数,取得count个不同的元素 #当count为负数,取得|count|个元素,有可能重复
7)弹出一个元素:spop key 随机选择一个元素弹出
五、zset(有序集合类型)
1、介绍
有序集合是在集合基础上为每个元素添加一个关联分数,从而通过获得元素分数的高低进行排序,集合元素是不同的,但是关联的分数却可以相同。
有序集合在某些方面跟列表有些相似:
相同点:
不同点:
2、命令操作
1)增加元素
zadd key score member[score member]#如果元素已存在,则用新的分数更新它的分数,返回添加的元素个数 127.0.0.1:6379> zadd sort 50 tom 60 darren 70 helen (integer) 3
分数不仅支持正数,还支持小数。
2)获得元素的分数
zscore key member 127.0.0.1:6379> zscore sort tom "50"
3)获得/删除排名在某个范围内的元素
zrange key start stop [withscores]
zrerange key start stop [withscores]
zrange表示先按分数从小到大排序后,取得索引从start到stop之间所有的元素,包括两端。加上withscores表示把分数也取得。
4)获得指定分数范围内的元素
zrangebyscore key min max [withscores] [limit offset count] 表示先按分数从小到大排序后,取得分数从min到max之间所有的元素,包括两端。如果不希望加上两端的话,只需要在前面加上(,withscores表示把分数也取得。min和max还支持无穷大。后面的 [limit offset count]跟sql中功能一样。
5)增加某个元素的分数
zincrby key increment member #返回值是增加后的分数
6)获得有序集合元素个数:zcard key
7)获得指定分数范围内的元素个数:zcount key min max
8)删除有序集合中的元素:zrem key member [member...]
9)按照排名范围删除元素:zremrangebyrank key start stop
10)按照分数范围删除元素:zremrangebyscore key min max
11)获得元素的排名:zrank key member(从小到大) zrevrank key member(从大到小)
redis中五大数据类型到这里就都说完了,有些命令还是多敲敲才能记住。
标签:hle 进制 exist 命令 跳跃表 其他 增加 复杂 friend
原文地址:http://www.cnblogs.com/wangsicongde/p/7588534.html