标签:style blog http os io 使用 ar strong for
前言:Google大数据处理的3篇核心论文
《The Google File System》:http://research.google.com/archive/gfs.html
《MapReduce: Simplified Data Processing on Large Clusters 》:http://research.google.com/archive/mapreduce.html
《Bigtable: A Distributed Storage System for Structured Data》:http://research.google.com/archive/bigtable.html
GFS(Google文件系统)作为一个分布式文件系统,为Google提供基础的海量数据存储服务。虽然GFS并没有开源,但Google在其 04年发表的论文《The Google File System》里面做了详细的介绍,很多设计思路都很有学习的价值。
分布式文件系统
分布式文件系统:当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区(partition)并存储到若干台单独的计算机上。管理网络中夸多台计算机存储的文件系统。这种系统构架于网络之上,肯定会引入网络编程的复杂性,因此它比普通的磁盘文件系统更为复杂。
我们首先来简单的说明一下这个分布式,我们都知道现在要存储的数据量越来越大,但是一台电脑的存储能力是有限的,尽管我们可以通过提高某台电脑的存储能力来解决这个问题,但是这是无法根本解决这个问题,所以我们通过很多很多台廉价的电脑来分布式存储这些数据。简单说就是把要存的文件分割成一份一份存到许多台电脑上。
Google File System:是由google开发并设计的一个面向大规模数据处理的一个分布式文件系统。
为了满足Google迅速增长的数据处理需求,Google设计并实现了Google文件系统。它是有几百甚至几千台普通的廉价设备组装的存储机器。以下是一些设计思路。
1)我们知道有这么多机器,那么这些设备中的某些机器出现故障是很常见的事情,所以在GFS要集成持续的监控、错误侦测、灾难冗 余以及自动恢复的机制。
2)我们要存的数据大小是很大,所以要是按照以往的存储文件块大小,那么就要管理数亿个KB大小的小文件,这是很不合理的,所以在这个系统里面他们定义一个文件块的大小是64M。
3)绝大部分的大数据都是采用在文件尾部追加数据的,而不是覆盖数据的。对大文件的随机写入基本上是不存在的。
4)应用程序和文件系统API协同设计,简化对GFS的要求。
GFS架构设计:
GFS采用主/从模式,一个GFS包括一个master服务器r和多个chunk服务器。当然这里的一个master是指逻辑上的一个,物理上可以有多个(就是可能有两台,一台用于以防万一,一台用于正常的数据管理)。并且我们可以把客户端以及chunk服务器放在同一台机器上。
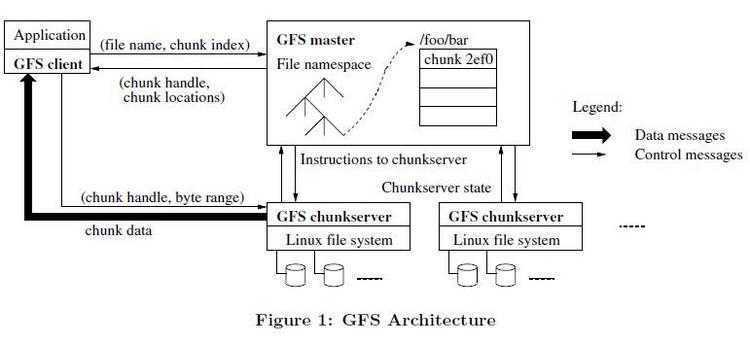
GFS Master(即NameNode):单独节点,管理GFS所有元数据(如名字空间、访问控制权限等)
GFS ChunkServer(即DataNode):数据存储节点,文件被分割为固定大小的(block)Chunk,每个Chunk被唯一标识,默认情况下,(block)Chunk存储为3个副本。
GFS Client:实现GFS的API接口函数(不是POSIX标准,因为API只需在用户空间调用)
我们先来说明一下数据是如何存储的。我们上面说过大数据会被切分,并且单位是64M。所以在GFS中,存储的文件会被切分成固定大小的block,每当一个block被创建的时候都会由master为它分配一个全球固定的标识。chunk服务器把block以linux文件存储的形式存储在本地系统。为了可靠性,每块block可能会复制成多份存放在不同的机器节点上。并且master服务器存储着文件和block之间的位置映射已经其他一些元数据信息。
1、master(就是在hadoop里面的namenode):
master管理者所有文件的元数据,比如说名字空间,block的映射位置等等。Master节点使用心跳信息周期地和每个Chunk服务器通讯,发送指令到各个Chunk服务器并接收Chunk服务器的状态信息。我们知道master是单一节点的(逻辑上)。这个是可以大大简化系统的设计。单一的master可以通过全局信息精确的定位每个block在哪个chunk服务器上以及进行复制决策。由于只有一台master,所以我们要减少对master的读写操作,避免master成为系统的瓶颈。而且master的元数据都是存储在内存当中的,这样速度处理快,但是也导致了存储的数据是有限制的。
要注意的是,客户端对数据的读写不是在master上,而是通过master获取block在chunk的位置信息,直接和chunk服务器进行数据交互读写的。我们说master是逻辑上只有一个节点,物理可能有两个。就行hadoop里面的hdfs一样,有一个namenode和secondarynamenode。另外一个正常情况下不去用,当master服务器宕机了,它就体现价值了。有点映像的感觉,当然它还有其他好多功能。
2、Chunk(就是hadoop里面datanode):这个才是用于存储数据的机器,文件大小为64MB,这个尺寸远远大于一般文件系统的Block size。每个block的副本都以普通Linux文件的形式保存在Chunk服务器上。Master服务器并不保存持久化保存哪个Chunk服务器存有指定block的副本的信息。Master服务器只是在启动的时候轮询Chunk服务器以获取这些信息。Master服务器能够保证它持有的信息始终是最新的,因为它控制了所有的block位置的分配,而且通过周期性的心跳信息监控 Chunk服务器的状态。
block块较大尺寸优点:(是一个关键的设计参数,默认为64MB。每个block都以普通Linux文件存储在ChunkServer上)
(1)减少Clinet与Master的通信
(2)减少Master的元数据的存储
(3)Client可以对文件块进行多次操作,减少I/O压力
3、元数据
主要包括:命名空间、文件和Block的映射关系(文件包括哪些Block)、每个Block副本的存放文章信息。
存储:元数据存储在Matser服务器的内存中,这样可以快速查找,性能好,但是由于Master内存有限制。
* 命名空间及文件和Chunk的映射关系,均以记录变更日志的方式落地为系统日志文件,并复制到远程Master备机上。
*Block副本的位置信息为Master周期性向各个ChunkServer轮询获得 => 没有落地,避免了ChunkServer变更时的Master和ChunkServer的数据同步问题
* 操作日志记录了关键元数据变更历史,对Master的容灾非常重要,故只有在元数据变更持久化到日志后,才会对Client可见。为了避免操作日志过长,GFS定期会对当前操作日志做一次Checkpoint,以压缩 B+树形式存储为一个CheckPoint文件。
* 故Master的恢复只需最新的CheckPoint文件和后续的操作日志。
4、存储访问流程:首先,客户端把文件名和程序指定的字节偏移,根据固定的block大小,转换成文件的block索 引。然后,它把文件名和block索引发送给Master节点。Master节点将相应的block标识和副本的位置信息发还给客户端。客户端用文件名和 block索引作为key缓存这些信息。之后客户端发送请求到其中的一个副本处,一般会选择最近的。请求信息包含了block的标识和字节范围。在对这个block的后续读取操作中, 客户端不必再和Master节点通讯了,除非缓存的元数据信息过期或者文件被重新打开。实际上,客户端通常会在一次请求中查询多个block信息。
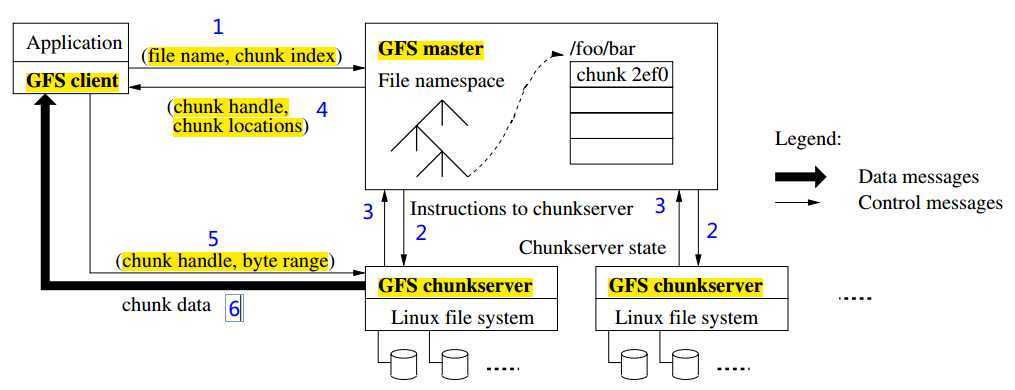
下面简单解释下在单点Master下一次简单的读取过程:
(1)客户端向Master发送请求,请求信息为(文件名,块索引)
(2)Master使用心跳信息监控块服务器的状态,并向其发送指令。
(3)块服务器需要周期性的返回自己的状态给Master,以确保能够接收Master的请求。
(4)Master将(块句柄,块位置)这一信息返回给客户端
(5)客户端使用文件名和块索引作为Key进行缓存信息。然后,客户端发送请求到其中的一个副本中(通常为最近的),该请求包括(块句柄,字节范围)。对这个块的后续操作,客户端无需再和Master进行通信,除非缓存信息过期或者文件被重新打开。
(6)块服务器将所需的块数据发送给客户端。
hadoop是的hdfs是基于GFS设计实现的。因此它们的原理是一样。现在hadoop到处都是,所以对于GFS就总结这些,具体的介绍留着在hadoop的HDFS中说明。
参考:http://www.open-open.com/lib/view/open1328763454608.html
http://www.open-open.com/lib/view/open1386577681689.html
标签:style blog http os io 使用 ar strong for
原文地址:http://www.cnblogs.com/mmcmmc/p/3963462.html