标签:marker 地方 理解 服务端 null typeof seh 文档 art
1. 什么是ElasticSearch?
ElasticSearch is a powerful open source search and analytics engine that makes data easy to explore.
可以简单理解成索引加检索的工具,当然它功能多于此。
ElasticSearch分为服务端与客户端,服务端提供REST API,客户端使用REST API。
2.怎么安装Elastic?

文档中有详细说明
完成后,在如下图的地方找到一个html
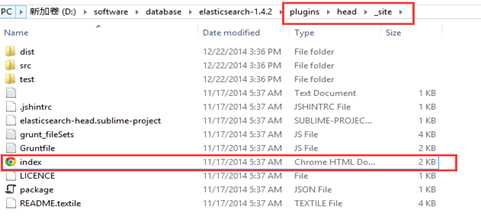
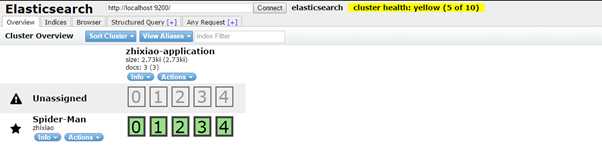
3. 如何使用NEST客户端(文档:http://nest.azurewebsites.net/nest/quick-start.html)
上面这句代码是可以不用写的,因为在调用下面的index方法的时候,如果没有指定使用哪个index,ElasticSearch会直接使用我们在setting中的defaultIndex,如果没有,则会自动创建。
但是如何你需要使用Mapping来调整索引结构,就会需要CreateIndex这个方法。具体的会在下面的Mapping中提到
正常来说,搜索的需求一般是我们传入一个keyword(和需要搜索的field name),返回符合条件的列表,那么搜索就分为全文搜索和单属性搜索。顾名思义,全文搜索就是用keyword去匹配所有的属性,单属性搜索就是只匹配指定的属性。
另外由于ES是分词搜索,所以当我们要用"One"来搜索完整的单词"JustOne"的时候,就必须在"One"外面添加**,类似于SQL里面的%keyword%,但是这样的做法会导致在用完整的单词来搜索的时候搜索不到结果,所以我们需要使用下面的方式(如果有更好的方法请不吝赐教):
指定属性的搜索有两种:
Term是一个被索引的精确值,也就是说Foo, foo, FOO是不相等的,因此
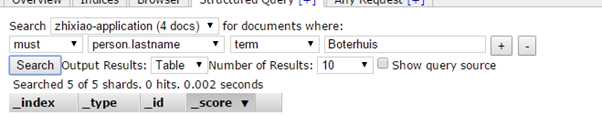
在使用term query的时候要注意,term query在搜索的Field已经被索引的时候,是不支持大写的。下面为elasticSearch - header测试
所有数据:

大写搜索:
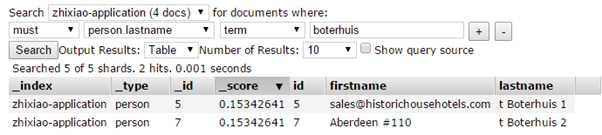
小写搜索:
NEST的使用:
或者(效果一样):
PS:term query的Field是必须的,如果Field为空,会产生下面的错误 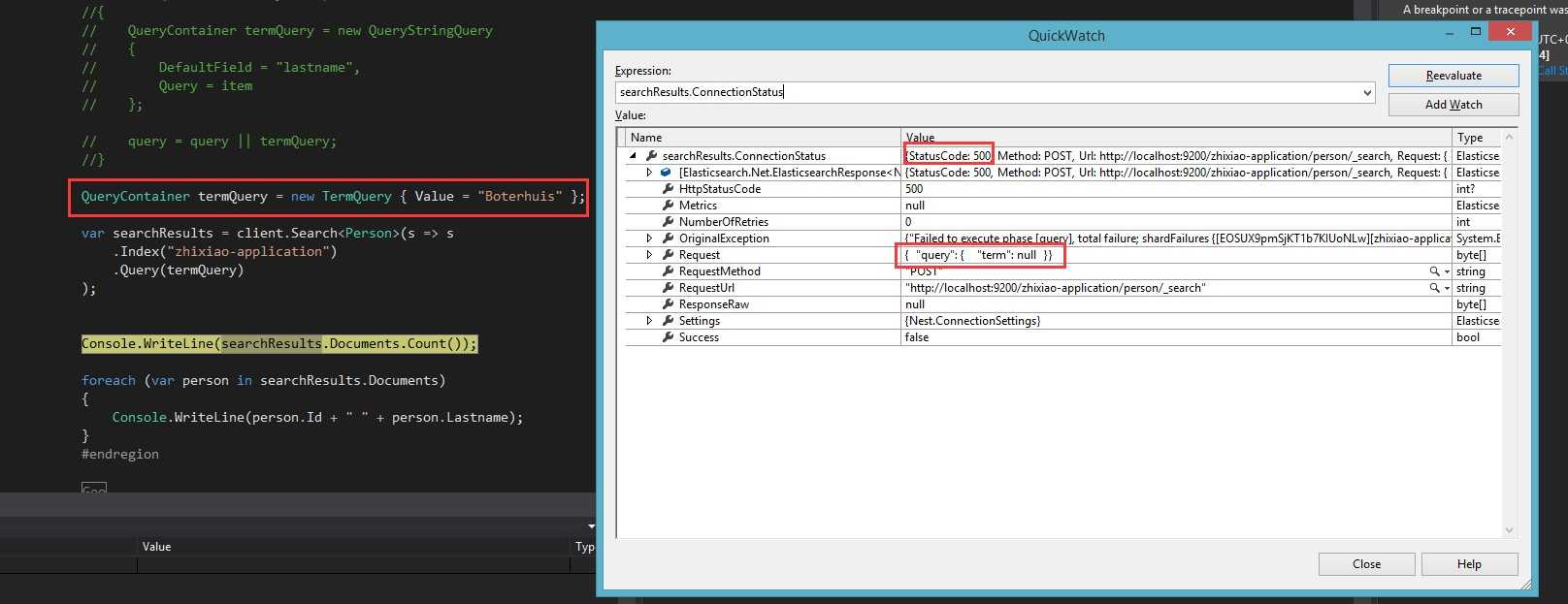
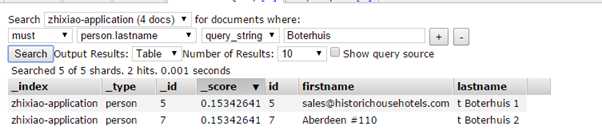
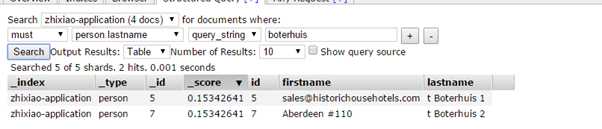
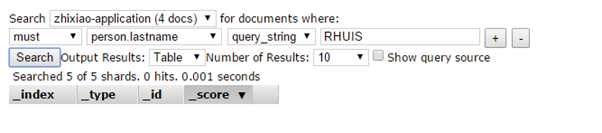
QueryString query一般用于全文搜索,但是也可以用于单个属性的搜索(设置DefaultField属性),queryString query可以不区分大小写。QueryString还有一个好处就是我们可以搜索一个term中的一部分,例如lastname为"t Boterhuis 1",那么我们可以用"terhuis"搜索到这个数据(虽然需要在外面包上**),在term query里面就做不到,因为ES把每一个属性的值都分析成一个个单独的term,提高了搜索的效率。
下面为elasticSearch - header测试:
完整term搜索(大写):
完整term搜索(小写):
部分搜索(大写,不带**):
部分搜索(大写,带**):
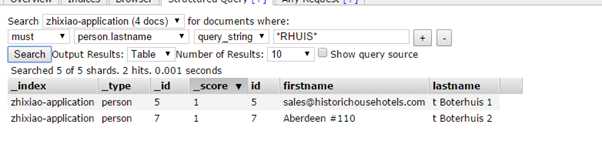
部分搜索(小写,带**):
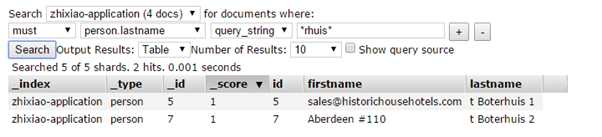
多词语搜索:当我们想搜索类似于:"t Boterhuis 2"这样的多个单词构成的keyword(用空格分开),term query是无法查询的,term query顾名思义就是单词查询。不能支持多单词查询

QueryString query:
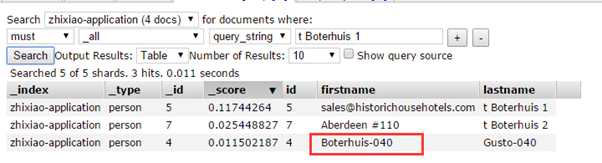
大家可以看到,第三条也被搜索进来了,这是因为ES把"t Boterhuis 2"解析成了三个词汇"t"" Boterhuis""2"。然后分开搜索,把结果集合并,所以ID为4的记录也被搜索出来了。那么我们如何让合起来搜索呢?
QueryString query有一个DefaultOperator的属性,我们可以将其设置为And,这样搜索的时候,ES会将几个term的search结果做and运算。
但是有一个比较大的问题是如果我的keyword是"Aberdeen Boterhuis",
这样也可以搜索出结果来:

我们搜索出了ID为7的数据,因为这条数据firstname里面有Aberdeen ,last name里面有Boterhuis。
目前还没有找到比较好的方法来解决这个问题,如果各位有好的方法请不吝赐教。
搜索需要我们重新构建索引,这样才能发现错误并且解决他们。
首先我们把原先的索引先删除了
然后重新创建索引
Person的类:
好了,让我们来测试下排序~
1).ID排序
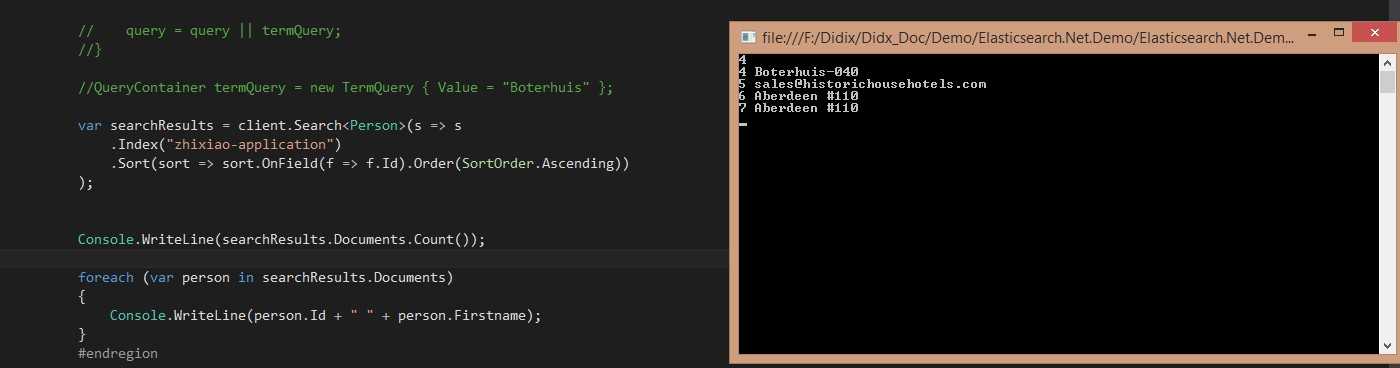
正常!
.Index("zhixiao-application")
.Sort(sort => sort.OnField(f => f.Id).Order(SortOrder.Ascending))
);
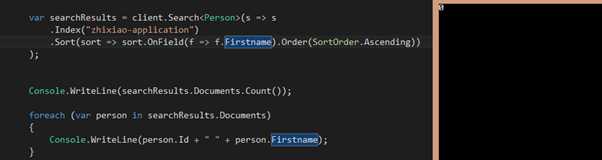
咦,奇怪,数据哪里去了呢?刚才ID的排序正常,为啥这里就不正常了呢?
我们先断点看下:
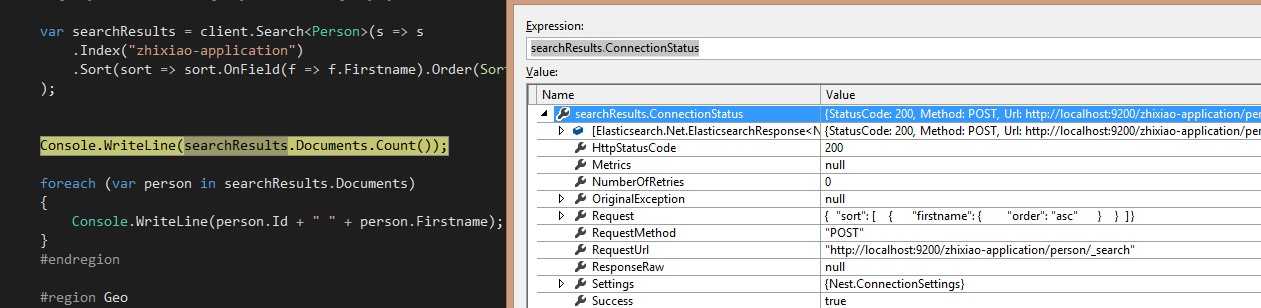
可以看到,ConnnectionStatus的status code是200,说明连接成功,但是我们又没有查询出数据来,接下来就需要我们的header工具了
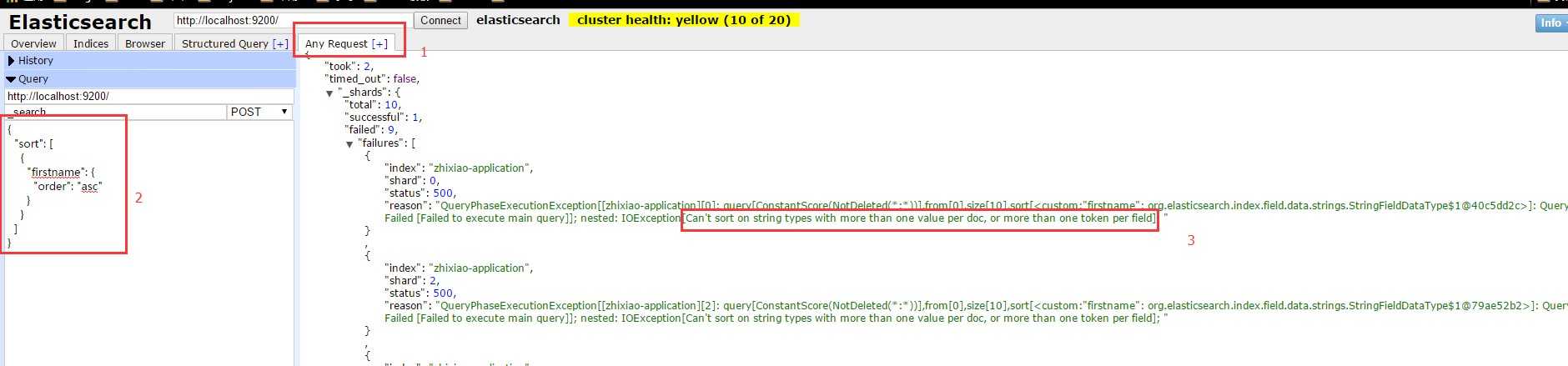
在最后一个tab中,header工具允许我们将ConnectionStatus.Request中的json用于查询,以此来验证对错。我们可以看到,查询的时候报了一个错误
Can‘t sort on string types with more than one value per doc, or more than one token per field
因为我们的数据是
 这样的,在解析的时候,firstname会被analyse成多个term,所以在排序的时候,就会出错。
这样的,在解析的时候,firstname会被analyse成多个term,所以在排序的时候,就会出错。
那么我们要怎么办呢?
在这里我找到了一些答案,我们需要将一个我们需要排序的字段mapping成两个不同的字段,一个经过分析(e.g. firstname),一个没有经过分析(e.g. firtname.sort ).
在NEST中,有一个简便的方法,就是在你需要排序的属性上面加一个Attribute
所以我们先将原先的索引删除,然后重新添加索引。
client.Map<Person>(m => m.MapFromAttributes());
这句代码很重要(在调用它之前需要先CreateIndex),它根据ElasticProperty对对象进行了mapping,使得firstname变成了一个multi fields,这点我们可以从 Request的Json中红色部分看出

{
"person": {
"properties": {
"id": {
"type": "string"
},
"firstname": {
"type": "multi_field",
"fields": {
"firstname": {
"type": "string"
},
"sort": {
"index": "not_analyzed",
"type": "string"
}
}
},
"lastname": {
"type": "string"
},
"chains": {
"type": "string"
}
}
}
}
另外在header中可以发现,属性中多了一个person.firstname.sort
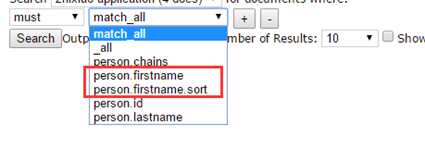
所以我们现在可以使用这个属性来进行排序了
代码如下:
var searchResults = client.Search<Person>(s => s
.Index("zhixiao-application")
.Sort(sort => sort.OnField(f => f.Firstname.Suffix("sort")).Ascending())
);
PS:注意上面红色部分的代码
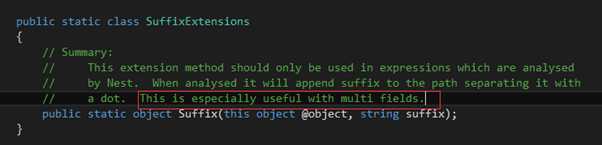
排序结果如下:
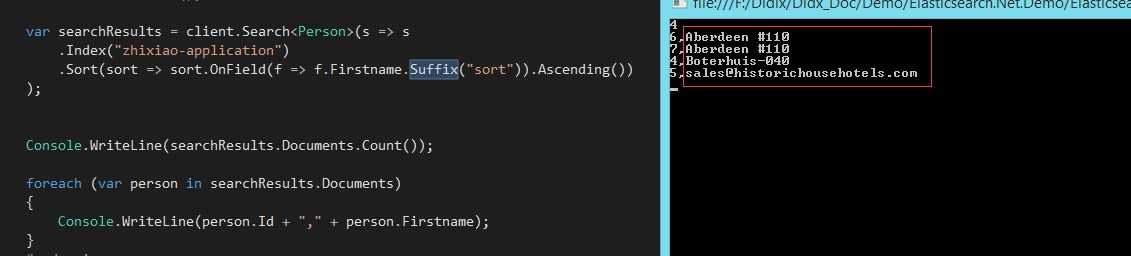
成功!
3.距离排序
Elastic Search 自带了距离的排序和距离的筛选。所以我们只需要将索引建好,就可以使用。
好了,下面我们就一步步来进行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class Location{ public string Name { get; set; } [ElasticProperty(Type = FieldType.GeoPoint)] public Coordinate Coordinate { get; set; }}public class Coordinate{ public double Lat { get; set; } public double Lon { get; set; }} |
PS:[ElasticProperty(Type = FieldType.GeoPoint)]这个attribute是为了下面mapping的时候,ES会将其识别为GeoPoint
|
1
2
3
4
5
6
7
8
|
client.CreateIndex("geopoint-tests", s => s .AddMapping<Location>(f => f .MapFromAttributes() .Properties(p => p .GeoPoint(g => g.Name(n => n.Coordinate).IndexLatLon()) ) )); |
下面是创建索引并且mapping的request json:
{
"settings": {
"index": { }
},
"mappings": {
"location": {
"properties": {
"name": {
"type": "string"
},
"coordinate": {
"type": "geo_point",
"lat_lon": true
}
}
}
}
}
client.IndexMany(new[]
{
createLocation("1", 52.310551, 5.07039),
createLocation("2", 52.310551, 10.761176),
createLocation("3", 52.310551, 8.07039),
createLocation("4", 52.310551, 6.07039),
});
private static Location createLocation(string name, double latitude, double longitude)
{
return new Location
{
Name = name,
Coordinate = new Coordinate { Lat = latitude, Lon = longitude }
};
}
(4)排序的使用:
结果:
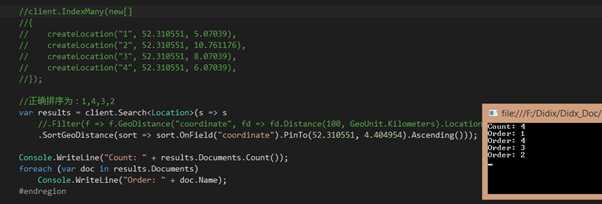
成功!
代码如下:
结果如下:

由于比较简单,我就不解释啥了,直接上代码
Person newperson = new Person()
{
Id = "7",
Firstname = "Aberdeen #110",
Lastname = "Update",
Chains = new string[] { "a", "b", "c" },
};
UpdateRequest<Person> updateRequest = new UpdateRequest<Person>(7)
{
Doc = newperson
};
IUpdateResponse updateResponse = updateClient.Update<Person, Person>(updateRequest);
if (updateResponse.ConnectionStatus.HttpStatusCode != 200)
{
updateClient.Index(newperson);
}
client.ClearCache();
var searchResults = updateClient.Search<Person>(s => s
.Index("zhixiao-application")
.Query(q => q.Term(t => t.OnField(f => f.Id).Value(7)))
);
Console.WriteLine(searchResults.Documents.Count());
foreach (var person in searchResults.Documents)
{
Console.WriteLine(person.Id + "," + person.Lastname);
}
PS:需要注意的是,如果你需要清除一个属性的值,传入null会导致ES认为你不需要更新这个属性,所以清除一个属性的值我们需要传入一个""。
updateClient.Delete<Person>(d => d.Id(7));
//delete one by object
updateClient.Delete<Person>(new Person() { });
//delete the Indices
updateClient.DeleteIndex(new DeleteIndexRequest(new IndexNameMarker() { Name = "zhixiao-application", Type = typeof(Person) }));
标签:marker 地方 理解 服务端 null typeof seh 文档 art
原文地址:http://www.cnblogs.com/a-du/p/7603138.html