标签:精准 www 结构 选择 get attribute 网页 length 数据
在网页自动化测试中,我们要让程序自动模拟我们的点击、输入、悬浮、拖动等操作,完成我们的测试用例组。
我们的操作大多为“动宾”结构,如:点击搜索,打开百度,上传图片;当然也有“在搜索栏输入selenium”这样带状语的结构。
输入、点击、打开这样的动词,已经包含在了selenium的方法中,可以直接调用(当然你也可以自己写),
但如何让这些动作精准的作用到我们想要作用的对象上呢?
这就要用到“元素定位”!!!
说了这么多,终于进入正题了。
以百度的首页为例,定位以下三个元素

先来看一些这些元素的html代码
输入框
<input id="kw" class="s_ipt" name="wd" value="" maxlength="255" autocomplete="off">
搜图按键
<span class="soutu-btn"></span>
新闻
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
hao123
<a class="mnav" href="http://www.hao123.com" name="tj_trhao123">hao123</a>
定位的方法有很多种,小编先介绍一些基础的,常用的。在页面中找到某一元素的方法式find_element_by_XXX()。
前驱代码:
1 from selenium import webdriver 3 driver=webdriver.Firefox() 5 driver.get("http://www.baidu.com")
1.通过id定位到“百度一下”,并输入字符串“selenium”
driver.find_element_by_id(“kw”).send_keys("selenium")
备注一下,send_keys()方法是向文本框中输入字符使用的。
2.通过calss name定位到搜图按键
driver.find_element_by_class_name(“soutu-btn”).click()
class可以将样式一致的内容封装在一起,给同一种CSS样式。像搜图按键,在整个页面上也没有兄弟姐妹,因此它的class是它自己独享的,
而像是“新闻”这一排内容,一个css里面有一堆元素,又该如何定位呢?
<div id="u1"> <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a> <a class="mnav" href="http://www.hao123.com" name="tj_trhao123">hao123</a> <a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图</a> <a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a> <a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a> <a class="mnav" href="http://xueshu.baidu.com" name="tj_trxueshu">学术</a> </div>
按照刚刚的,来试一下
driver.find_element_by_class_name("mnav").click()
结果,居然是进入了“新闻”页,打开了第一个的连接,这可怎么办呢?对于这种固定的超链接,好解决,可以选择使用其他定位方式,如下。
3.通过link text定位超链接
link是专门对超链接进行操作的,它的对象是我们可以看得到的超链接文字,有精准匹配和模糊匹配两种形式:
精准匹配-打开hao 123
driver.find_element_by_link_text("hao123").click()
模糊匹配-打开hao123
driver.find_element_by_partial_link_text("123").click()
4.通过XPath
什么事XPath?
XPath是XML路径语言,是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
在网页自动化测试中,我们可以通过元素的标签、属性等来确定某一个元素的位置,从而对这个元素进行操作。
但仍有一个问题,有些浏览器不支持xpath解析,而不同的浏览器对网页源代码的解析也有可能不一致,所以很多时候需要我们针对不同的浏览器,做一定的改动。
XPath手动编写的操作,这里不做介绍,小编直接讲一讲如何用火狐浏览器的插件Firepath来获取XPath。
首先,在火狐浏览器中装插件:
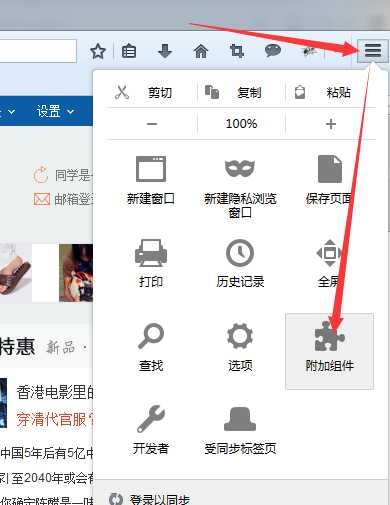
在“扩展页签”里搜索FirePath,搜索
在其他可用附加组件中,找到FirePath,安装之后浏览器会提示重启浏览器。

重启之后,按F12,进入开发者模式,就会看到,多了FirePath的页签。选中一个元素进行查看时,XPath处会自动判断出它的XPath值。
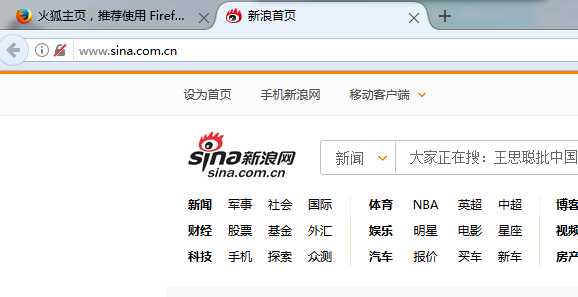
例如,我找到的是火狐首页中的“新浪”超链接,现在我们将它自动打开。
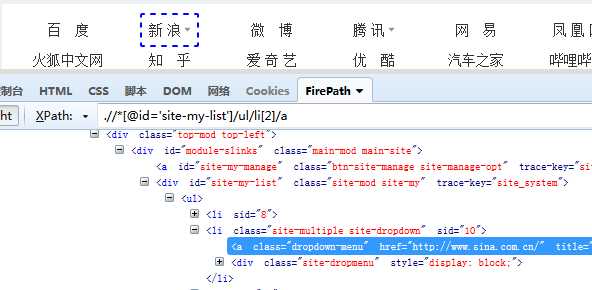
from selenium import webdriver import time driver=webdriver.Firefox() driver.get("http://e.firefoxchina.cn/") time.sleep(2) driver.find_element_by_xpath(".//*[@id=‘site-my-list‘]/ul/li[2]/a").click()
结果,当然就是成功的打开啦。
5.通过css selector
css定位被放到最后一个写,但是不代表它不重要、用得少。css selector相对于xpath来讲,手动的东西多一点,但是他的定位更加迅速,语法也更加简单。
css一般用.来代表class属性,用#来代表id属性,各种标签,就直接以标签的名字(如input)来表示。
例:在百度的搜索框内输入:selenium
回顾一下百度搜索框的代码
<input id="kw" class="s_ipt" name="wd" value="" maxlength="255" autocomplete="off"/>
通过css来定位的方法为find_element_by_css_selector("")
前驱代码
#在百度首页输入selenium driver.get("http://www.baidu.com") time.sleep(3)
通过css属性定位
#通过id属性 driver.find_element_by_css_selector("#kw").send_keys("selenium") #通过class属性 driver.find_element_by_css_selector(".s_ipt").send_keys("selenium") #通过标签 driver.find_element_by_css_selector("input").send_keys("selenium")
注:上述三种方法,在验证其中一种时,请将另外两种注释掉。
单行注释可以在注释内容前加#,如上代码
多行注释,可以使用三对引号。
‘‘‘ 三对 单引号 的注释 ‘‘‘ driver.get("http://e.firefoxchina.cn/") """ 三对双引号的注释 """
对于复杂的html,一个属性或许无法定位,但是可以使用属性的叠加,达到用css定位的目的。
| T[attribute=‘value‘] | 查找指定标签T下,含有attribute属性,且属性值为value的元素 |
| T[attribute^=‘value‘] | 查找指定标签T下,含有attribute属性,且属性值以value开头的元素 |
| T[attribute$=‘value‘] | 查找指定标签T下,含有attribute属性,且属性值以value结尾的元素 |
| T[attribute*=‘value‘] | 查找指定标签T下,含有attribute属性,且属性值包含value的元素 |
例:点击百度首页的“hao123”
<div id="u1"> <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a> <a class="mnav" href="http://www.hao123.com" name="tj_trhao123">hao123</a>
`````` </div>
我们可以使用css selector,通过name的属性的确定。
driver.find_element_by_css_selector("a[name=‘tj_trhao123‘]").click()
标签:精准 www 结构 选择 get attribute 网页 length 数据
原文地址:http://www.cnblogs.com/wulisz/p/7606986.html