标签:简单 ems for jieba sort logs 统计 utf-8 get
中文分词
import jieba f=open(‘kiu.txt‘,‘r‘,encoding=‘utf-8‘).read() words=list(jieba.cut(f)) dic={} for i in words: if len(i)==1: continue else: dic[i]=dic.get(i,0)+1 w =list(dic.items()) w.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(w[i])
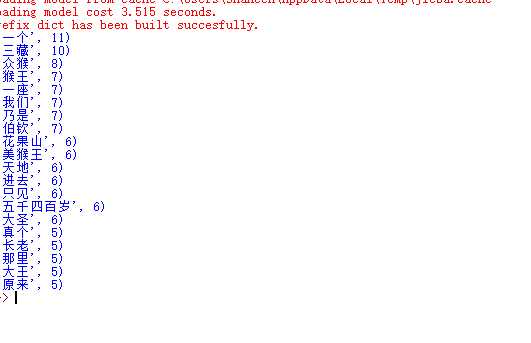
解读:
讲的是三藏与大圣美猴王的故事
标签:简单 ems for jieba sort logs 统计 utf-8 get
原文地址:http://www.cnblogs.com/honghui/p/7612907.html