标签:请求超时 意思 忽略 文件夹 iterator 工作 自动发现 oba 一个
部分摘抄自:http://www.cnblogs.com/yuanermen/p/5717885.html
REmote DIctionary Server(Redis) 是一个key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
redis 127.0.0.1:6379> SET name "runoob"
OK
redis 127.0.0.1:6379> GET name
"runoob
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为 runoob。
注意:一个键最大能存储512MB。
Redis hash 是一个键名对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
127.0.0.1:6379> HMSET user:1 username runoob password runoob points 200
OK
127.0.0.1:6379> HGETALL user:1
1) "username"
2) "runoob"
3) "password"
4) "runoob"
5) "points"
6) "200"
以上实例中 hash 数据类型存储了包含用户脚本信息的用户对象。 实例中我们使用了 Redis HMSET, HGETALL 命令,user:1为键值。
每个 hash 可以存储 232 -1 键值对(40多亿)。
list可以重复,lpush lrange
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
redis 127.0.0.1:6379> lpush runoob redis
(integer) 1
redis 127.0.0.1:6379> lpush runoob mongodb
(integer) 2
redis 127.0.0.1:6379> lpush runoob rabitmq
(integer) 3
redis 127.0.0.1:6379> lrange runoob 0 10
1) "rabitmq"
2) "mongodb"
3) "redis"
redis 127.0.0.1:6379>
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Redis的Set是string类型的无序集合。但不能重复
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
添加一个string元素到,key对应的set集合中,成功返回1,如果元素已经在集合中返回0,key对应的set不存在返回错误。
sadd key member
redis 127.0.0.1:6379> sadd runoob redis
(integer) 1
redis 127.0.0.1:6379> sadd runoob mongodb
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 0
redis 127.0.0.1:6379> smembers runoob
1) "rabitmq"
2) "mongodb"
3) "redis
注意:以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
添加元素到集合,元素在集合中存在则更新对应score
zadd key score member
redis 127.0.0.1:6379> zadd runoob 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 mongodb
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 0
redis 127.0.0.1:6379> ZRANGEBYSCORE runoob 0 1000
1) "redis"
2) "mongodb"
3) "rabitmq"
Redis的所有数据都是保存到内存中的。
Rdb:快照形式,定期把内存中当前时刻的数据保存到磁盘。Redis默认支持的持久化方案。
aof形式:append only file。把所有对redis数据库操作的命令,增删改操作的命令。保存到文件中。数据库恢复时把所有的命令执行一遍即可。
一、概述
Redis3.0版本之后支持Cluster.
1.1、redis cluster的现状
目前redis支持的cluster特性:
1):节点自动发现
2):slave->master 选举,集群容错
3):Hot resharding:在线分片
4):进群管理:cluster xxx
5):基于配置(nodes-port.conf)的集群管理
6):ASK 转向/MOVED 转向机制.
1.2、redis cluster 架构
1)redis-cluster架构图
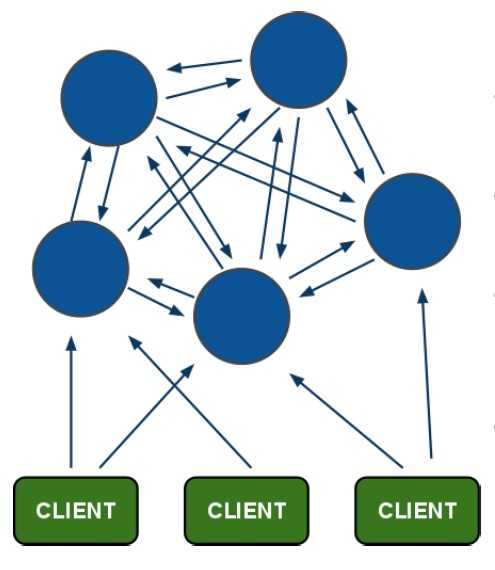
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
2) redis-cluster选举:容错
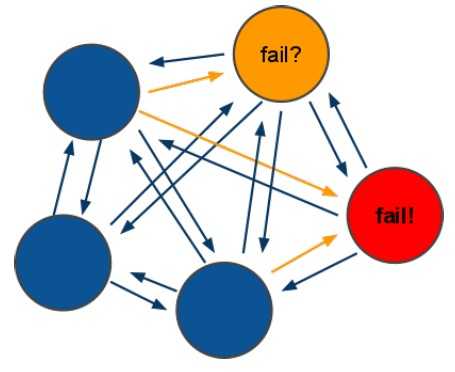
(1)领着选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态.
b:如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
二、redis cluster安装
1、下载和解包
cd /usr/local/wget http://download.redis.io/releases/redis-3.2.1.tar.gztar -zxvf /redis-3.2.1.tar.gz2、 编译安装
cd redis-3.2.1 make && make install
3、创建redis节点
测试我们选择2台服务器,分别为:192.168.1.237,192.168.1.238.每分服务器有3个节点。
我先在192.168.1.237创建3个节点:

cd /usr/local/
mkdir redis_cluster //创建集群目录
mkdir 7000 7001 7002 //分别代表三个节点 其对应端口 7000 7001 7002
//创建7000节点为例,拷贝到7000目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7000/
//拷贝到7001目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7001/
//拷贝到7002目录
cp /usr/local/redis-3.2.1/redis.conf ./redis_cluster/7002/
分别对7001,7002、7003文件夹中的3个文件修改对应的配置
daemonize yes //redis后台运行 pidfile /var/run/redis_7000.pid //pidfile文件对应7000,7002,7003 port 7000 //端口7000,7002,7003 cluster-enabled yes //开启集群 把注释#去掉 cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002 cluster-node-timeout 5000 //请求超时 设置5秒够了 appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
在192.168.1.238创建3个节点:对应的端口改为7003,7004,7005.配置对应的改一下就可以了。
4、两台机启动各节点(两台服务器方式一样)
cd /usr/local redis-server redis_cluster/7000/redis.conf redis-server redis_cluster/7001/redis.conf redis-server redis_cluster/7002/redis.conf redis-server redis_cluster/7003/redis.conf redis-server redis_cluster/7004/redis.conf redis-server redis_cluster/7005/redis.conf
5、查看服务
ps -ef | grep redis #查看是否启动成功
netstat -tnlp | grep redis #可以看到redis监听端口
Redis集群中至少应该有三个节点。要保证集群的高可用,需要每个节点有一个备份机。
Redis集群至少需要6台服务器。
搭建伪分布式。可以使用一台虚拟机运行6个redis实例。需要修改redis的端口号7001-7006
前面已经准备好了搭建集群的redis节点,接下来我们要把这些节点都串连起来搭建集群。官方提供了一个工具:redis-trib.rb(/usr/local/redis-3.2.1/src/redis-trib.rb) 看后缀就知道这鸟东西不能直接执行,它是用ruby写的一个程序,所以我们还得安装ruby.
1、使用ruby脚本搭建集群。需要ruby的运行环境。
安装ruby
yum install ruby
yum install rubygems
gem是ruby的一个工具包.
注意:这里安装的ruby如果出现版本过低,请采用rvm进行重新安装:http://blog.csdn.net/fengye_yulu/article/details/77628094
2、安装ruby脚本运行使用的包。
gem install redis
[root@localhost ~]# cd redis-3.0.0/src
[root@localhost src]# ll *.rb
-rwxrwxr-x. 1 root root 48141 Apr 1 2015 redis-trib.rb
上面的步骤完事了,接下来运行一下redis-trib.rb
/usr/local/redis-3.2.1/src/redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
reshard host:port
--to <arg>
--yes
--slots <arg>
--from <arg>
check host:port
call host:port command arg arg .. arg
set-timeout host:port milliseconds
add-node new_host:new_port existing_host:existing_port
--master-id <arg>
--slave
del-node host:port node_id
fix host:port
import host:port
--from <arg>
help (show this help)
create host1:port1 ... hostN:portN
--replicas <arg>
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
看到这,应该明白了吧, 就是靠上面这些操作 完成redis集群搭建的.
确认所有的节点都启动,接下来使用参数create 创建 (在192.168.1.237中来创建)
/usr/local/redis-3.2.1/src/redis-trib.rb create --replicas 1 192.168.1.237:7000 192.168.1.237:7001 192.168.1.237:7003 192.168.1.238:7003 192.168.1.238:7004 192.168.1.238:7005
解释下, --replicas 1 表示 自动为每一个master节点分配一个slave节点 上面有6个节点,程序会按照一定规则生成 3个master(主)3个slave(从)
前面已经提醒过的 防火墙一定要开放监听的端口,否则会创建失败。
运行中,提示Can I set the above configuration? (type ‘yes‘ to accept): yes //输入yes
接下来 提示 Waiting for the cluster to join.......... 安装的时候在这里就一直等等等,没反应,傻傻等半天,看这句提示上面一句,Sending Cluster Meet Message to join the Cluster.
这下明白了,我刚开始在一台Server上去配,也是不需要等的,这里还需要跑到Server2上做一些这样的操作。
在192.168.1.238, redis-cli -c -p 700* 分别进入redis各节点的客户端命令窗口, 依次输入 cluster meet 192.168.1.238 7000……
回到Server1,已经创建完毕了。
查看一下 /usr/local/redis/src/redis-trib.rb check 192.168.1.237:7000
到这里集群已经初步搭建好了。
四、测试
1)get 和 set数据
redis-cli -c -p 7000
进入命令窗口,直接 set hello howareyou
直接根据hash匹配切换到相应的slot的节点上。
还是要说明一下,redis集群有16383个slot组成,通过分片分布到多个节点上,读写都发生在master节点。
2)假设测试
果断先把192.168.1.238服务Down掉,(192.168.1.238有1个Master, 2个Slave) , 跑回192.168.1.238, 查看一下 发生了什么事,192.168.1.237的3个节点全部都是Master,其他几个Server2的不见了
测试一下,依然没有问题,集群依然能继续工作。
原因: redis集群 通过选举方式进行容错,保证一台Server挂了还能跑,这个选举是全部集群超过半数以上的Master发现其他Master挂了后,会将其他对应的Slave节点升级成Master.
疑问: 要是挂的是192.168.1.237怎么办? 哥试了,cluster is down!! 没办法,超过半数挂了那救不了了,整个集群就无法工作了。 要是有三台Server,每台两Master,切记对应的主从节点
不要放在一台Server,别问我为什么自己用脑子想想看,互相交叉配置主从,挂哪台也没事,你要说同时两台crash了,呵呵哒......
3)关于一致性
我还没有这么大胆拿redis来做数据库持久化哥网站数据,只是拿来做cache,官网说的很清楚,Redis Cluster is not able to guarantee strong consistency.
开始在 Java 中使用 Redis 前, 我们需要确保已经安装了 redis 服务及 Java redis 驱动,且你的机器上能正常使用 Java。 Java的安装配置可以参考我们的 Java开发环境配置 接下来让我们安装 Java redis 驱动:
import redis.clients.jedis.Jedis; public class RedisJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); } }
编译以上 Java 程序,确保驱动包的路径是正确的。
连接成功
服务正在运行: PONG
import redis.clients.jedis.Jedis;
public class RedisStringJava {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("localhost");
System.out.println("连接成功");
//设置 redis 字符串数据
jedis.set("runoobkey", "www.runoob.com");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: "+ jedis.get("runoobkey"));
}
}
编译以上程序。
连接成功 redis 存储的字符串为: www.runoob.com
import java.util.List; import redis.clients.jedis.Jedis; public class RedisListJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); //存储数据到列表中 jedis.lpush("site-list", "Runoob"); jedis.lpush("site-list", "Google"); jedis.lpush("site-list", "Taobao"); // 获取存储的数据并输出 List<String> list = jedis.lrange("site-list", 0 ,2); for(int i=0; i<list.size(); i++) { System.out.println("列表项为: "+list.get(i)); } } }
编译以上程序。
连接成功
列表项为: Taobao
列表项为: Google
列表项为: Runoob
import java.util.Iterator; import java.util.Set; import redis.clients.jedis.Jedis; public class RedisKeyJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); // 获取数据并输出 Set<String> keys = jedis.keys("*"); Iterator<String> it=keys.iterator() ; while(it.hasNext()){ String key = it.next(); System.out.println(key); } } }
编译以上程序。
连接成功
runoobkey
site-list
标签:请求超时 意思 忽略 文件夹 iterator 工作 自动发现 oba 一个
原文地址:http://www.cnblogs.com/limingxian537423/p/7612458.html