标签:技术趋势 dia 买卖 数据分布 完全 价值 今后 简单 核函数
数据挖掘在大数据中的应用综述
***
(上海海事大学 上海 201306)
摘 要: 面对大规模多源异构的数据,数据挖掘的方法不断的得到改善与发展,同时对于数据挖掘体系的完善也提出了新的挑战。针对当前数据挖掘在大数据方面的应用,本文从数据挖掘的各个阶段进行了方法论的总结及应用,主要包括数据准备的方法、数据探索的方法、关联规则方法、数据回归方法、数据分类方法、数据聚类方法、数据预测方法和数据诊断方法。最后还指出类数据挖掘在鲁棒性表达方面的进一步研究。
关键词: 数据挖掘;方法论;大数据;鲁棒性
Application of Data Mining in Large Data
***
(Shanghai Maritime University,Shanghai 201306)
Abstract: In the face of large-scale multi-source heterogeneous data, data mining methods continue to improve and develop, at the same time for the improvement of data mining system also put forward new challenges. In this paper, the method of data mining, the method of data exploration, the association rule method, the data regression method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, Data clustering method, data prediction method and data diagnosis method. Finally, it also points out the further research on the robustness of class data mining.
Key words: Data mining; methodology; large data; robustness
随着人类生活方式的多样化,由此产生的数据的规模和复杂性也在急速增长,对于数据的各种分析也应运而生。在数据挖掘领域,对于大数据的分析可谓是越来越成为时代的主流。科技时代下,数据成为各行各业发展的依据和关键,面对如此庞大的数据,数据挖掘承担了十分重要的角色。在大数据时代下,数据挖掘成为行业间沟通的桥梁,可以说,谁掌握了数据,谁就拥有了行业的主导权。因此,数据挖掘在大数据中显得尤为重要。
大数据的定义可谓是五花八门,但是不管哪种定义,大数据并不是一种新的产品也不是一种新的技术,大数据只是一种数字化时代下的现象。大数据由海量交易数据、海量交互数据和海量数据处理三大主要的技术趋势汇集而成。大数据的特征是数据体量巨大、数据种类繁多、流动速度快、价值密度低,大数据的"4V"特征表明其不仅仅是海量数据,对于大数据的分析将更加复杂、更追求速度、更注重实效。
数据挖掘已经在大数据中得到了广泛的应用,并且获得了成功。数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的,但又潜在有用的信息和知识的过程,数据挖掘是在没有明确假设的前提下去挖掘信息,发现知识。数据挖掘基于的数据库类型主要有关系型数据库、面向对象数据库、事物数据库、演义数据库、时态数据库、多媒体数据库、主动数据库、空间数据库、文本型、Internet信息库以及新兴的数据仓库,数据挖掘的内容主要集中在关联、回归、分类、聚类、预测和诊断六个方面。本文从总体上对数据挖掘有个全面的认识与了解,主要从算法及其应用的层次介绍数据挖掘在大数据方面的应用,包括数据准备的方法、数据探索的方法、关联规则方法、数据回归方法、数据分类方法、数据聚类方法、数据预测方法、数据诊断方法。另外还包括时间序列方法和智能优化方法,本文不做陈述。
数据的准备包括数据的收集、数据的质量分析和数据的预处理。
数据的抽样方法:
(1)简单随机抽样
(2)系统抽样
(3)整群抽样
(4)分层抽样
(1)值分析:包括唯一值分析、无效值分析、异常值分析
(2)统计分析:包括众数、分位数、中位数、偏度
(3)频次与直方图分析:包括频次图和直方图分析方法
(1)数据清洗:对于缺失值的处理,一般采用删除法和插补法;对于噪声的过滤,一般采用回归法、均值平均法、离群点分析、小波去噪
(2)数据集成:包括联邦数据库、中间件集成方法和数据仓库方法。
(3)数据规约:包括数据选择和样本选择。
(4)数据变换:包括标准化、离散化和语义转换
数据探索中常用的方法包括衍生变量、数据的统计、数据可视化、样本选择和数据降维。
衍生变量常用的方法:
(1)对多个列变量进行组合
(2)按照维度分类汇总
(3)对某个变量进一步分解
(4)对具有时间序列特征的变量提取时间特征
数据的统计一般包括基本描述性统计和分布描述性统计
(1)基本描述性统计:包括表示位置的统计量,算数平均数和中位数;表示数据散度的统计量,标准差、方差和极差;表示分布形状的统计量,偏度和峰度
(2)分布描述性统计:包括随机变量的分布函数和密度函数
数据的可视化一般包括基本可视化,数据分布形状可视化,数据关联情况可视化和数据分组可视化。
样本的选择方法主要包括随机取样法、顺序取样法和监督取样法。
主成分分析法是采用一种数学降维的方法,设法做的就是将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。
主成分分析法的步骤:
(1)对原始数据进行标量化处理
(2)计算相关系数矩阵R
(3)计算相关系数矩阵R的特征值和相应的特征向量
(4)选择重要的主成分,并写出主成分表达式
(5)计算主成分得分
(6)依据主成分得分的数据,进一步对问题进行后续的分析、建模
对于企业的综合实力进行排序,是PCA成功的应用实例。根据不同企业的净资产、固定资产利润率、总产值利润率、销售收入利润率、产品成本利润率、物耗利润率、人均利润率和物流资金利润率组成的矩阵,对企业综合实力进行排序。
关联规则常用的方法包括Apriori算法和FP-Growth算法。
Apriori算法使用频繁项集性质的先验知识,其主要步骤如下:
FP-Growth算法将提供频繁项集的数据库压缩到一颗频繁模式数,但是任然保留项集的关联信息,与Apriori算法的最大不同有两点,第一,不产生候选码,第二,只需要两次遍历数据库。其主要步骤如下:
行业关联选股法就是一种基于关联规则的选股方法,其基本思想就是从数据中选择有联动关联的行业,当某个行业出现涨势之后,而其相关联行业还没有开始涨,则从其关联行业中选择典型个股买入。
数据回归方法包括一元线性、一元非线性、多元线性、多元非线性、逐步回归和Logstic回归。由于前四种回归方式比较简单,只对后两种回归进行介绍。
逐步回归的基本思想有进有出。引入一个变量或者从回归方程总剔除一个变量为逐步回归的一步,每一步都要进行F检验。算法的基本步骤如下:
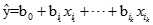
Logistic回归是一个概率模型,可以利用它预测某个时间发生的概率,通常将f(p)定义为Logit函数。
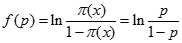
多因子模型是应用最广泛的一种选股模型,基本原理正是采用一系列的因子作为选股标准,满足这些因子的股票则被买入,不满足的则被卖出。多因子选股模型的建立过程主要分为候选因子的提取、选股因子有效性的检验、有效但冗余因子的剔除、综合评分模型的建立和模型的评价及持续改进5个步骤。这5个步骤中,回归方法可以用来辅助筛选因子、检验因子有效性、冗余因子的剔除,也可以直接用回归方程建立综合评分模型。
常见的分类方法有7种,包括K-近邻、贝叶斯分类、神经网络、Logtic、判别分析、支持向量机和决策树。
K-近邻分类方法通过计算每个训练样例到待分类样品的距离,取和待分类样品距离最近的K个训练样例,K个样品中那个类别的训练样本占多数,则待分类元祖就属于那个类别。
KNN算法的具体步骤:
贝叶斯分类是一类利用概率统计知识进行分类的算法,其分类原理是贝叶斯定理
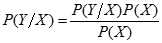
其算法的步骤如下:
人工神经网络是一种应用类似于大脑神经突触连接的结构,进行信息处理的数学模型。人工神经网络的研究是由试图模拟生物神经系统而激发的,其重要的模型为感知器,感知器模型如下:
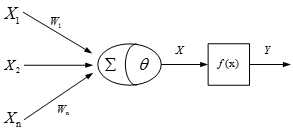
图1 感知器模型
感知器包括两个节点,几个输入点和一个输出点,在感知器中,每个输入节点都通过一个加权的链连接到输出节点。其具体算法如下:
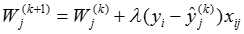
其中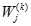 是第k次循环后第i个输入链上的权值,参数
是第k次循环后第i个输入链上的权值,参数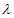 成为学习率,
成为学习率,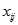 是训练样例
是训练样例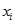 的第j个属性值
的第j个属性值
Logstic算法已经在前面进行了介绍,这里可以陈述一下Logstic的特点
判别分析是根据观察或者预测到的若干变量值判断研究对象如何分类的方法。判别分析对判别变量有三个基本建设:
判别分析的基本模型就是判别函数:
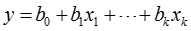
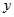 是判别函数值,又简称为判别值;
是判别函数值,又简称为判别值;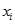 是各判别变量;
是各判别变量;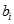 为相应的判别系数
为相应的判别系数
支持向量机构建了一个分割两类的超平面,该算法师徒使两类之间的分割达到最大化,以一个很大的边缘分隔两个类,可以使期望泛化误差最小化。
支持向量机最初是在研究线性可分问题的过程中提出的,所以常用的线性支持向量机模型为:
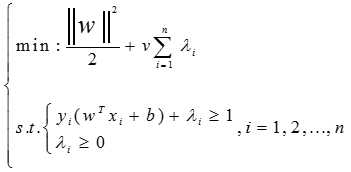
支持向量机的理论有三个要点,最大化间距,核函数,对偶理论。
决策树是最为广泛的归纳推理算法之一,处理类别型或连续型变量的分类预测问题,可以用图形和if-then的规则表示模型,可读性较高。决策树是一种监督式的学习方法,产生一种类似流程图的树结构。决策树的构建步骤主要有三个:
决策树的算法基本上是一种贪心算法,由上而下的逐次搜索方式,渐渐产生决策树模型结构。ID3是著名的决策树算法,以信息论为基础,企图最小化变量间比较的次数,其基本策略是选择具有最高信息增量的变量为分割变量,ID3算法必须将所有变量转化为类别变量
ID3算法的步骤:
分类在量化投资中是一种十分实用的技术。在股票投资中,将股票分为三类:涨、持平和跌。在进行选股时,可以根据数据训练一个分类器,再利用该分类器,实现对近期或者未来一段时间的股票进行预测。
常见的聚类方法包括k-means、层次聚类、神经网络、模糊C-均值聚类、高斯混合聚类
划分的基本思想是给定一个有N个元组或者记录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类。算法步骤:
层次聚类算法是通过将数据组织为若干组并形成一个相应的树来进行聚类的。两种常用的层次聚类算法是凝聚的层级聚类和分裂的层次聚类。
神经网络在聚类方面表现的特征与分类相似,对数据适应性强,对噪声数据敏感。神经网络的输入具有连续性,但聚类结果往往是分类数据类型。
模糊C均值聚类是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。具体步骤如下:
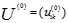 ,通常的做法是取[0,1]上的均值分布随机数来确定初始隶属度矩阵
,通常的做法是取[0,1]上的均值分布随机数来确定初始隶属度矩阵 。令l=1表示第1步迭代。
。令l=1表示第1步迭代。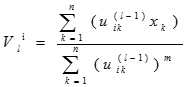
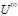 ,计算目标函数值
,计算目标函数值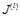
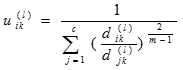
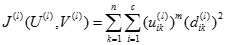
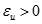 ,当
,当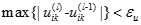 时,停止迭代,否则l=l+1,然后转到步骤2)。
时,停止迭代,否则l=l+1,然后转到步骤2)。高斯混合聚类方法和K-means相似,区别在于高斯混合聚类引入了概率。高斯混合聚类学习的过程就是训练出几个概率分布,所谓混合高斯模型就是对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和。每个高斯模型就代表一个类,对样本的数据分别在几个高斯模型上进行投影,就分别得到了各个类上的概率。我们选取概率最大的作为判别结果。
聚类方法在量化投资中的主要作用是对投资对象进行聚类,然后根据聚类的结果评估每个类别的盈利能力,选择盈利强的类别的对象进行投资。
常见的预测方法

这里对灰色预测法和马尔科夫法进行介绍
灰色预测是以灰色模型为基础,在诸多模型中,以灰色系统中单序列一阶线性微分方程模型GM(1,1)最常用。
GM(1,1)模型:
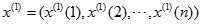
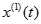 建立
建立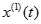 的一阶线性微分方程,即:
的一阶线性微分方程,即: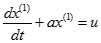
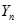
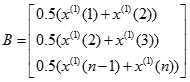
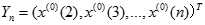
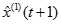
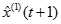 及
及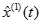 进行离散并且将二者作差以便还原
进行离散并且将二者作差以便还原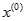 原序列,得到近似数据序列
原序列,得到近似数据序列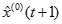
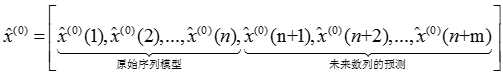
马尔科夫预测具有马尔科夫性,预测时刻的状态治愈当前状态有关,与前期状态无关。马尔科夫预测的步骤如下:
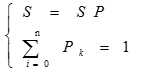
在股票的走势分析中,经常用马尔科夫性来进行股票走势的预测。
常用的数据的诊断方法包括基于统计的离群点诊断、基于距离的离群点诊断、基于密度的离群点诊断和基于聚类的离群点诊断。
基于统计的离群点诊断的基本思想:符合正态总体分布的对象出现在分布尾部的机会很少。其算法如下:
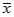 和样本标准差S。根据给定的显著水平
和样本标准差S。根据给定的显著水平 和样本容量n,查表求出
和样本容量n,查表求出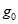
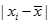 ,找出
,找出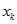 ,使得
,使得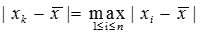
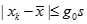 ,则认为无异常数据,否则,将之剔除。
,则认为无异常数据,否则,将之剔除。某个对象远离大部分其他对象,则该对象是离群的。基于距离方法的两种不同策略:第一种策略采用给定邻域半径,依据点的邻域中包含的对象多少来判定离群点;第二种策略是利用K-最近邻距离的大小来判定离群。离群因子的定义:
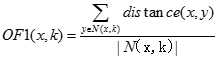
探测局部密度,通过不同的密度估计策略来检测离群点。一种常用的定义密度的方法是,定义密度为k个最近邻的平均距离的倒数
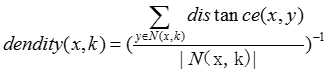
具体的基于密度的离群点的步骤如下:
聚类分析是用来发现数据集中强相关的对象组,而离群点诊断是发现不与其他对象组强相关的对象。基于聚类的离群点诊断步骤如下:
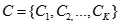
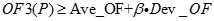 的对象为离群点。
的对象为离群点。离群点诊断的主要目的是发现异常,这种异常在股票投资中十分有用,所以离群点诊断在股票买卖时可以发挥重要的作用。
结束语
数据挖掘作为近年来十分流行的一门学科,在各个行业,尤其是金融、互联网方面发挥了巨大的作用。经过多年的时间证明,数据挖掘能够提高团队的生产率,产品的质量和产品的满意度。但是,由于数据挖掘还存在许多问题,今后还有很多工作值得进一步深入研究。例如,面向大规模多源异构数据的鲁棒特性的表达。
参考文献
标签:技术趋势 dia 买卖 数据分布 完全 价值 今后 简单 核函数
原文地址:http://www.cnblogs.com/smuxiaolei/p/7614217.html