标签:strong 缺陷 通过 判断 style algorithm logs end href
无监督学习
监督学习通过发现数据的其他属性和类别属性之间的关联模式并通过对这些模型来预测未知数据实例的类别属性。这些属性通常表示一些现实世界中的预测或分类问题,例如通过判断新闻是属于体育类还是属于政治类,而在其他的应用中,数据的类别属性却是缺失的。用户希望通过浏览数据来发现其中的某些内在结构。例如聚类是一种发现这种内在结构的技术。聚类把全体数据实例组织成一些相似组,这些相似组被称为聚类。处于相同聚类中的数据实例彼此相似,处于不同聚类中的实例则彼此不同。聚类技术经常被称为无监督学习。因为与监督学习不同,在聚类中数据类别的分类或分组信息是没有的。
1 k-均值算法
给定一个数据点集合和需要的聚类数目K,K-均值算法根据某个距离函数反复地把数据分入k个聚类中。
K-均值聚类的算法实现
Algorithm k-means(k,D)
选择K个点作为初始质心
Repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
Until 质心不再发生变化
?
先选取K个数据点作为聚类中心,再计算每个数据点与各个中心的剧烈,把每个数据点分配给距离它最近的聚类中心。聚类中心以及分配给它的数据点就代表一个聚类。一旦全部数据点被分配了,每个聚类中心会根据该聚类中现有的数据点被重新计算。这个过程将不断重复直到某个结束条件。
结束条件分为以下:
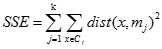
其中k表示需要的聚类数目,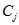 表示第j个聚类,
表示第j个聚类,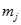 是聚类的聚类中心,
是聚类的聚类中心,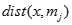 表示数据点和聚类中心之间的距离。
表示数据点和聚类中心之间的距离。
在那些均值能被定义和计算的数据集上的均值均使用k-均值算法。在欧式空间中,聚类的均值(中心)可以用下式计算:
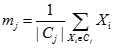
其中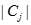 表示
表示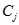 中数据点的个数,例如,3个二维点(1,1)、(2,3)和(6,2)的中心就是((1+2+6)/3,(1+3+2)/3)=(3,2)
中数据点的个数,例如,3个二维点(1,1)、(2,3)和(6,2)的中心就是((1+2+6)/3,(1+3+2)/3)=(3,2)
?
数据点和聚类均值(中心)之间的距离可以被计算如下:
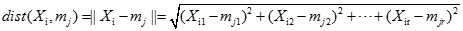
2 二分k均值算法
二分K均值算法是k均值算法的改进版,她基于一个简单的思想:为了得到k个簇,将所有点的集合分类成两个簇,从这些簇中选取一个继续分类,如此下去,直到产生k个簇。
二分K均值算法的实现
Algorithm Bit k-means(k,D)
初始化簇表,使之包含由所有的点组成的簇
Repeat
从簇中取出一个簇
{对选定的簇进行多次二分"实验"}
For i=1 to 实验次数 do
使用基本k均值,二分选定的簇
Endfor
从二分实验中选择具有最小SSE的两个簇
将这两个簇添加到簇表中
Until 簇中包含k个簇
3 优点和缺点
优点:K均值简单并且可以用于多种数据类型。
缺点:
(1)该算法要求用户随机选择初始质心,使得K均值算法受初始化影响较大。
????(2)改算法不太适合处理非球形簇、不同尺寸的簇、不同密度的簇,同时对于离群点的簇进行分类时,也有缺陷。
?
?
?
?
?
?
?
?
?
参考文献:
标签:strong 缺陷 通过 判断 style algorithm logs end href
原文地址:http://www.cnblogs.com/smuxiaolei/p/7614279.html