标签:网页 思想 质量 twitter 在线 计算公式 推荐 family ges
PageRank
1 概述
PageRank算法在1998年4月举行的第七届国际万维网大会上由Sergey Brin和Larry Page提出。PageRank是通过计算页面链接的数量和质量来确定网站重要性的粗略估计。算法创立之初的目的是应用在Google的搜索引擎中,对网站进行排名。
随着国内外学者的深入研究,PageRank算法被广泛应用于其他方面,例如学术论文的重要性排名,学术论文的作者的重要性排排序(某位作者引用了其他作者的文献,则该作者认为其他作者是重要的),网络爬虫(利于PR值,决定某个URL,所需要排序的网页数量和深度;重要性高的网页抓取的网页数量相对多一些,反正则少一点),关键词与句子的抽取,随后又出现了基于PageRank的Twitter用户的影响力排名,基于PageRank的微博用户影响力算法的研究,和一些其他在PageRank算法基础上进行改进的研究。由此可见PageRank在影响力排名方面的研究也十分热门。
2 核心思想
PageRank是基于从许多优质的网页链接过来的网页,必定还是优质网页的思想建立的。其包括:链入链接数(即受欢迎的指标)、链入链接是否来自推荐度高的页面、链入链接源页面的链接数。
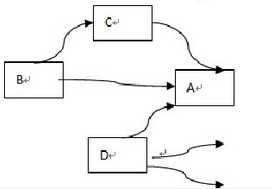
图1 页面集合
如图1所示,假设一个只有4个页面组成的集合:A,B,C,D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。
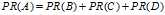
但是,如图1所示,B页面也连接到C页面,并且D页面有有连接到A页面。一个页面的投票权重总和为1。则根据图1,A页面的PR值为:
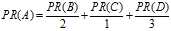
即得到页面A的PR值的计算公式
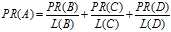
????其中L为某一个页面的链出数总和。
由此,可以得出简单的PageRank模型。
????把互联网上的各个网页之间的链接关系看成一个有向图。建设浏览者浏览的下一个网页链接来自于当前网页。建立一个简化模型:对于任意网页Pi,它的PageRank值可表示为如下:
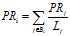
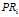 :网页i的PR值;
:网页i的PR值;
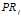 :网页j的PR值;
:网页j的PR值;
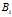 :所有链接到网页i的网页集合;
:所有链接到网页i的网页集合;
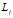 :为网页j的对外链接数(出度);
:为网页j的对外链接数(出度);
3 随机浏览模型
假定一个上网者从一个随机页面开始浏览,上网者不断点击当前网页的浏览开始下一次浏览。但是,上网者由于厌倦而开始随机的点击网页。随机上网方式更符合用户的浏览行为。避免了一个独立网页没有链出转态和整个网页图中的一组紧密链接成环的网页没有链出状态的情况,由此产生了随机浏览模型的建立过程:
????网页之间的链接关系可以用邻接矩阵表示,其公式如下:
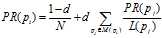
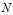 :网页中网页的总数;
:网页中网页的总数;
d:阻尼因子,通常设为0.85,d即按照超链接进行浏览的概率;
1-d:随机跳转一个新页面的概率;
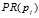 :网页
:网页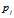 的PR值;
的PR值;
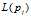 :网页
:网页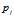 的链出网页数目;
的链出网页数目;
一个网页的PageRank是由其他页面的PageRank计算的。由于PR=A*PR满足马尔可夫链的性质,其中A是一个转移概率矩阵,那么通过迭代计算可以得到所有页面的PageRank值。经过重复计算,这些页面的PR值会趋于正常和稳定。
状态转移矩阵:
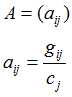
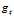 :页面的i到页面j有链接为1,否则为0;
:页面的i到页面j有链接为1,否则为0;
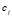 :页面j的链出总数;
:页面j的链出总数;
根据马尔可夫的遍历性
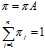
可以最终求出PR值,再归一化,便得到所有页面的PR值。例如:通过计算得到A的状态转移矩阵如下:
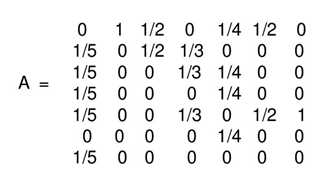
设各个页面的PR值为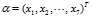 ,根据公式得:
,根据公式得:
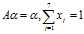 ,结果计算得到
,结果计算得到
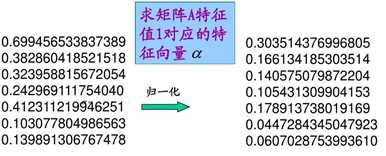
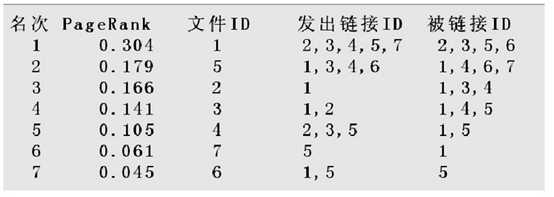
4 总结
优点:
(1)与查询无关的静态算法,所有网页的PageRank值都是离线计算好的;
(2)有效的减少了在线查询时的计算量,减少了查询响应时间;
缺点:
过分的相信链接关系
(1)一些权威网站往往都是互不链接的,因为存在竞争关系;
(2)人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题相关性降低;
(3)旧的页面等级比新的页面等级高。
参考文献:
?
[1] 孙红,左腾. 基于PageRank的微博用户影响力算法研究[J]. 计算机应用研究,2018,04:
[2] https://wenku.baidu.com/view/a58b3845b0717fd5370cdc5f.html
?
标签:网页 思想 质量 twitter 在线 计算公式 推荐 family ges
原文地址:http://www.cnblogs.com/smuxiaolei/p/7614287.html