标签:sof comm 三级 ref hot https blog fat image
今天上午看到一篇文章:一个简单粗暴的爬虫 - 必应今日美图。我也用自己的方式更加简单的实现了这个功能。下面我就贴一下自己的代码和思路。
我就不分析原博的思路了,原博写的很清楚。我用的是htmlunit,从原博的第三步开始,观察三级地址的规律,从http://bing.plmeizi.com/show/1-490开始爬取的。页面比较少,图片也不多,没用多线程。
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException; 2 import com.gargoylesoftware.htmlunit.WebClient; 3 import com.gargoylesoftware.htmlunit.html.HtmlAnchor; 4 import com.gargoylesoftware.htmlunit.html.HtmlPage; 5 import org.apache.commons.io.FileUtils; 6 7 import java.io.File; 8 import java.io.IOException; 9 import java.io.InputStream; 10 import java.net.MalformedURLException; 11 12 /** 13 * <pre> 14 * class intro 15 * </pre> 16 * <p> 17 * Created by fujun on 2017/9/29. 18 */ 19 public class BingPhoto { 20 public static void main(String[] args) { 21 WebClient webClient = new WebClient(); 22 webClient.getOptions().setCssEnabled(false); 23 webClient.getOptions().setJavaScriptEnabled(false); 24 for (int i = 1; i < 491; i++) { 25 String url = "http://bing.plmeizi.com/show/" + i; 26 try { 27 HtmlPage page = webClient.getPage(url); 28 HtmlAnchor a = (HtmlAnchor) page.getElementById("picurl"); 29 String picUrl = a.getHrefAttribute(); 30 if (picUrl.contains("jpg")) { 31 InputStream inputStream = webClient.getPage(picUrl).getWebResponse().getContentAsStream(); 32 FileUtils.copyToFile(inputStream, new File("E://bingpic//" + i + ".jpg")); 33 System.out.println("SUCCEED:" + url); 34 } else { 35 System.out.println("FAILED:" + url); 36 } 37 38 } catch (FailingHttpStatusCodeException e) { 39 // TODO Auto-generated catch block 40 e.printStackTrace(); 41 } catch (MalformedURLException e) { 42 // TODO Auto-generated catch block 43 e.printStackTrace(); 44 } catch (IOException e) { 45 // TODO Auto-generated catch block 46 e.printStackTrace(); 47 } finally { 48 webClient.close(); // 关闭客户端,释放内存 49 } 50 } 51 } 52 }
注意点:
有些页面是404的,例如:http://bing.plmeizi.com/show/44
还有些页面能打开但是加载不了图片,例如:http://bing.plmeizi.com/show/1
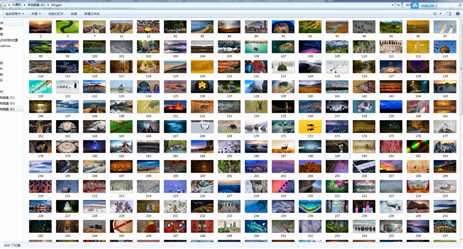
这490个页面,最后抓取到409张图片。原博只抓取到347张图片,好几个类,还用到多线程。我代码只有短短50行,更加简单粗暴!!!
标签:sof comm 三级 ref hot https blog fat image
原文地址:http://www.cnblogs.com/FJun/p/7615026.html