标签:call cond ace nbsp 分享 section signal station rto
https://www.cs.cmu.edu/afs/cs/project/jair/pub/volume4/kaelbling96a-html/node24.html
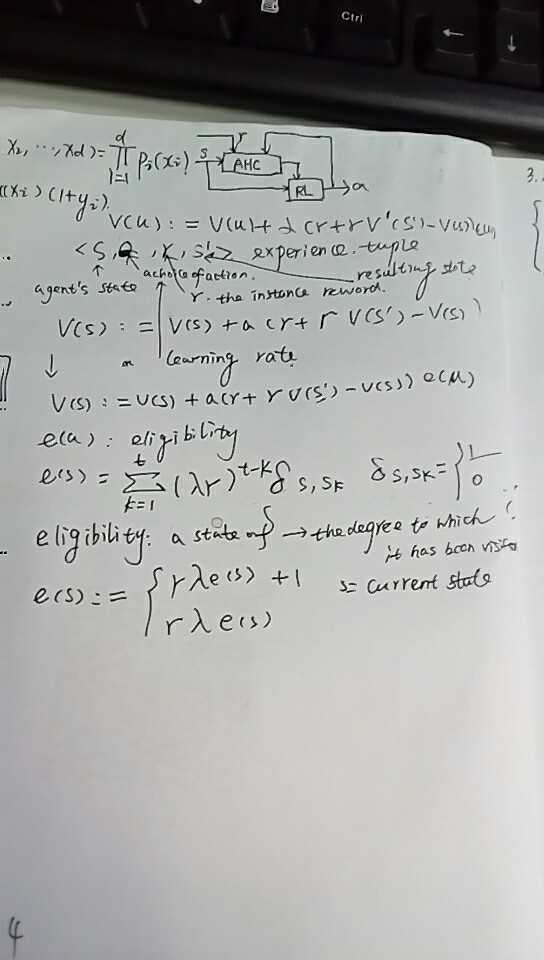
【旧知-新知 强化学习:对新知、旧知的综合】
The adaptive heuristic critic algorithm is an adaptive version of policy iteration [9] in which the value-function computation is no longer implemented by solving a set of linear equations, but is instead computed by an algorithm called TD(0). A block diagram for this approach is given in Figure 4. It consists of two components: a critic (labeled AHC), and a reinforcement-learning component (labeled RL). The reinforcement-learning component can be an instance of any of the k-armed bandit algorithms, modified to deal with multiple states and non-stationary rewards. But instead of acting to maximize instantaneous reward, it will be acting to maximize the heuristic value, v, that is computed by the critic. The critic uses the real external reinforcement signal to learn to map states to their expected discounted values given that the policy being executed is the one currently instantiated in the RL component.

Figure 4: Architecture for the adaptive heuristic critic.
We can see the analogy with modified policy iteration if we imagine these components working in alternation. The policy ![]() implemented by RL is fixed and the critic learns the value function
implemented by RL is fixed and the critic learns the value function ![]() for that policy. Now we fix the critic and let the RL component learn a new policy
for that policy. Now we fix the critic and let the RL component learn a new policy ![]() that maximizes the new value function, and so on. In most implementations, however, both components operate simultaneously. Only the alternating implementation can be guaranteed to converge to the optimal policy, under appropriate conditions. Williams and Baird explored the convergence properties of a class of AHC-related algorithms they call ``incremental variants of policy iteration‘‘ [133].
that maximizes the new value function, and so on. In most implementations, however, both components operate simultaneously. Only the alternating implementation can be guaranteed to converge to the optimal policy, under appropriate conditions. Williams and Baird explored the convergence properties of a class of AHC-related algorithms they call ``incremental variants of policy iteration‘‘ [133].
【体验表达:初始状态、学习率-行为过滤、即刻奖励、结果状态】
It remains to explain how the critic can learn the value of a policy. We define ![]() to be an experience tuple summarizing a single transition in the environment. Here s is the agent‘s state before the transition, a is its choice of action, r the instantaneous reward it receives, and s‘ its resulting state. The value of a policy is learned using Sutton‘s TD(0) algorithm [115] which uses the update rule
to be an experience tuple summarizing a single transition in the environment. Here s is the agent‘s state before the transition, a is its choice of action, r the instantaneous reward it receives, and s‘ its resulting state. The value of a policy is learned using Sutton‘s TD(0) algorithm [115] which uses the update rule

Whenever a state s is visited, its estimated value is updated to be closer to ![]() , since r is the instantaneous reward received and V(s‘) is the estimated value of the actually occurring next state. This is analogous to the sample-backup rule from value iteration--the only difference is that the sample is drawn from the real world rather than by simulating a known model. The key idea is that
, since r is the instantaneous reward received and V(s‘) is the estimated value of the actually occurring next state. This is analogous to the sample-backup rule from value iteration--the only difference is that the sample is drawn from the real world rather than by simulating a known model. The key idea is that ![]() is a sample of the value of V(s), and it is more likely to be correct because it incorporates the real r. If the learning rate
is a sample of the value of V(s), and it is more likely to be correct because it incorporates the real r. If the learning rate ![]() is adjusted properly (it must be slowly decreased) and the policy is held fixed, TD(0) is guaranteed to converge to the optimal value function.
is adjusted properly (it must be slowly decreased) and the policy is held fixed, TD(0) is guaranteed to converge to the optimal value function.
The TD(0) rule as presented above is really an instance of a more general class of algorithms called ![]() , with
, with ![]() . TD(0) looks only one step ahead when adjusting value estimates; although it will eventually arrive at the correct answer, it can take quite a while to do so. The general
. TD(0) looks only one step ahead when adjusting value estimates; although it will eventually arrive at the correct answer, it can take quite a while to do so. The general ![]() rule is similar to the TD(0) rule given above,
rule is similar to the TD(0) rule given above,

but it is applied to every state according to its eligibility e(u), rather than just to the immediately previous state, s. One version of the eligibility trace is defined to be

The eligibility of a state s is the degree to which it has been visited in the recent past; when a reinforcement is received, it is used to update all the states that have been recently visited, according to their eligibility. When ![]() this is equivalent to TD(0). When
this is equivalent to TD(0). When ![]() , it is roughly equivalent to updating all the states according to the number of times they were visited by the end of a run. Note that we can update the eligibility online as follows:
, it is roughly equivalent to updating all the states according to the number of times they were visited by the end of a run. Note that we can update the eligibility online as follows:
【eligibility 量化过去被访问率】

It is computationally more expensive to execute the general ![]() , though it often converges considerably faster for large
, though it often converges considerably faster for large ![]() [30, 32]. There has been some recent work on making the updates more efficient [24] and on changing the definition to make
[30, 32]. There has been some recent work on making the updates more efficient [24] and on changing the definition to make ![]() more consistent with the certainty-equivalent method [108], which is discussed in Section 5.1.
more consistent with the certainty-equivalent method [108], which is discussed in Section 5.1.
![]()
![]()
![]()
Next: Q-learning Up: Learning an Optimal Policy: Previous: Learning an Optimal Policy:
Leslie Pack Kaelbling
adaptive heuristic critic 自适应启发评价 强化学习
标签:call cond ace nbsp 分享 section signal station rto
原文地址:http://www.cnblogs.com/yuanjiangw/p/7615704.html