标签:img mil apt titan 排列 size 工程 特征 str
1.关于年龄Age
除了利用平均数来填充,还可以利用正态分布得到一些随机数来填充,首先得到已知年龄的平均数mean和方差std,然后生成[ mean-std, mean+std ]之间的随机数,然后利用这些随机值填充缺失的年龄。
2.关于票价Fare
预处理:训练集不缺,测试集缺失1个,用最高频率值填充
Fare_freq = test.Fare.dropna().mode()[0] # 找出非缺失值中的所有最高频值,取第一个
for dataset in train_test_data:
dataset[‘Fare‘] = dataset[‘Fare‘].fillna(Fare_freq)
特征工程:由于Fare分布非常不均,所以这里不用cut函数,而是qcut,因为它可以根据样本分位数对数据进行面元划分,可以使得到的类别中数目基本一样。
train[‘FareBins‘] = pd.qcut(train[‘Fare‘], 5) # 按照分位数切成5份
train[[‘FareBins‘, ‘Survived‘]].groupby([‘FareBins‘], as_index = False).mean().sort_values(by = ‘Survived‘, ascending = True)
fare = data_train.groupby([‘FareBins‘])
fare_l = (fare.sum()/fare.count())[‘Survived‘]
fare_l.plot(kind=‘bar‘)
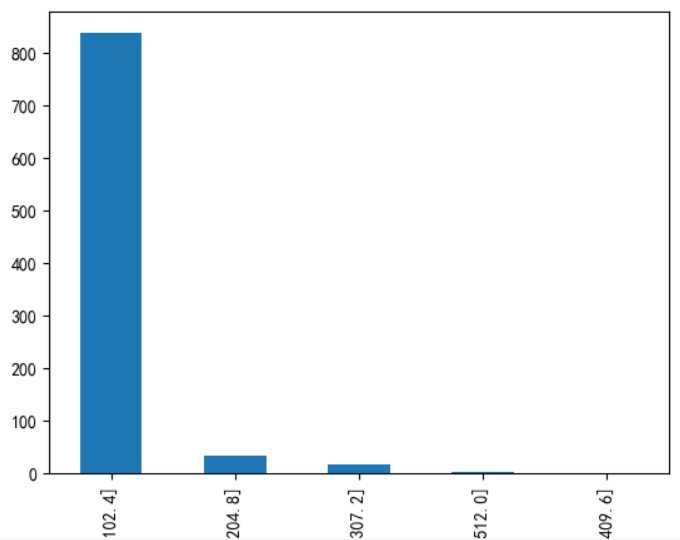
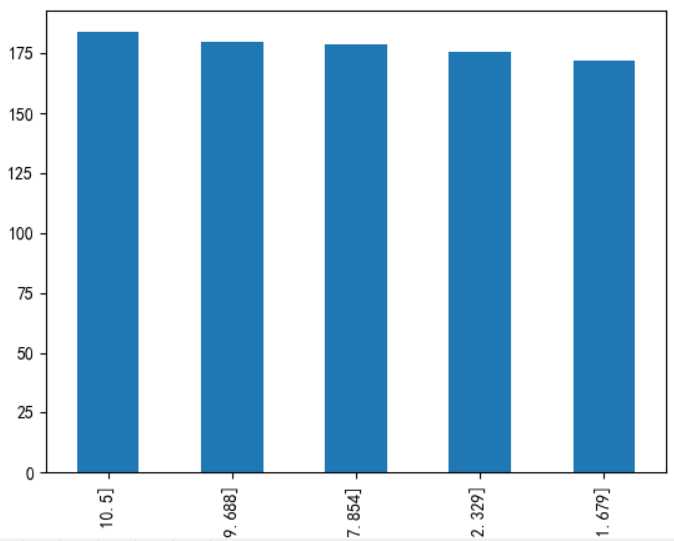
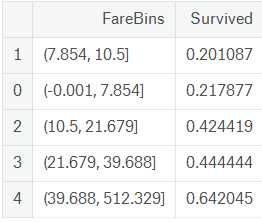
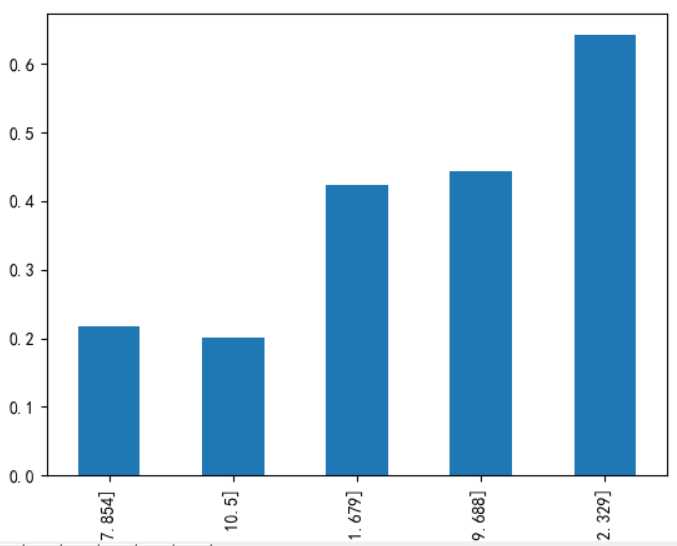
上图左为cut函数结果,中为qcut函数结果,右图为各年龄段的生存率,升序排列,可以看到生存率基本上按照票价增加而增加。然后在数据集中新增FareBins取值0~4,然后删除Fare项。
3.关于亲人SibSp和Parch
新增Family特征为SibSp和Parch的和,删掉SibSp和Parch
dataset["FamilySize"] = dataset[‘SibSp‘] + dataset[‘Parch‘]
train[[‘FamilySize‘, ‘Survived‘]].groupby([‘FamilySize‘], as_index = False).mean().sort_values(by = ‘Survived‘, ascending = False)
4.关于姓名
取出姓名中的’属性‘,例如有:Mr、Miss、Dr、Major等
df =data_train.Name.apply(lambda x: x.split(‘,‘)[1].split(‘.‘)[0].strip())
df.value_counts().plot(kind=‘bar‘)
train_test_data = [train, test] # 将训练集和测试集合并处理
for dset in train_test_data: # 对于人数较少的属性将其统一命名为‘Lamped’
dset["Title"] = dset["Title"].replace(["Melkebeke", "Countess", "Capt", "the Countess", "Col", "Don",
"Dr", "Major", "Rev", "Sir", "Jonkheer", "Dona"] , "Lamped")
dset["Title"] = dset["Title"].replace(["Lady", "Mlle", "Ms", "Mme"] , "Miss") # 将女性称号合并
train[[‘Title‘, ‘Survived‘]].groupby([‘Title‘], as_index = False).mean().sort_values(by = ‘Survived‘, ascending = False)
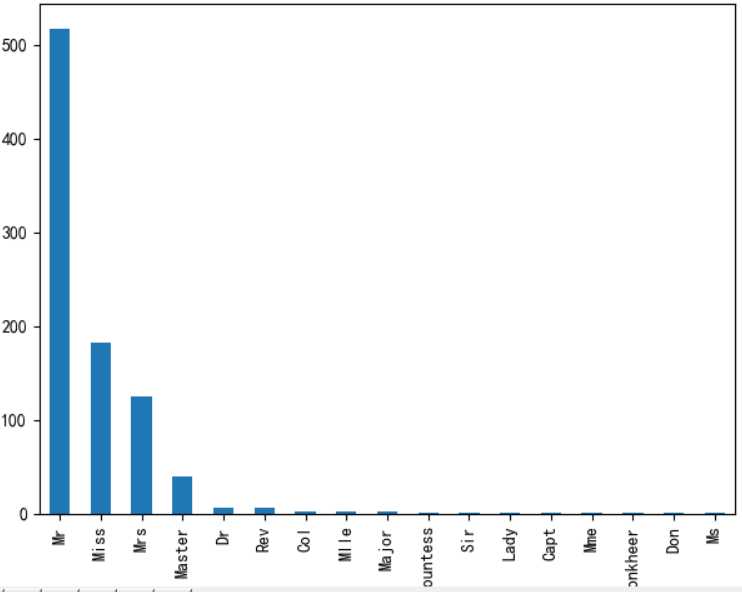
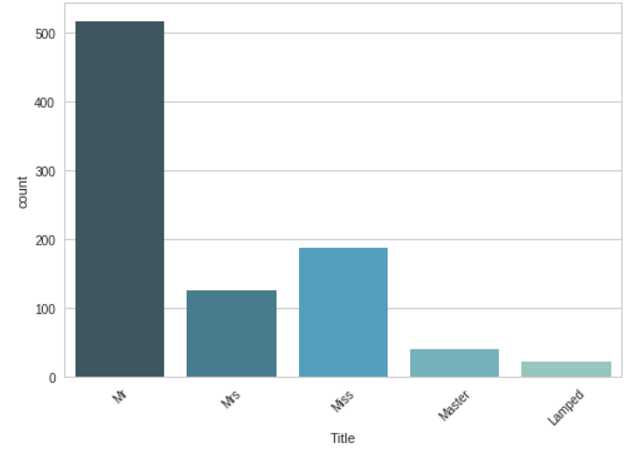
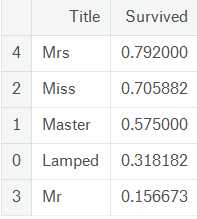
然后将这类特征作为新特征取值0~4加入,删掉原有特征Name。
标签:img mil apt titan 排列 size 工程 特征 str
原文地址:http://www.cnblogs.com/king-lps/p/7617739.html