标签:缩进 写入文件 针对 声明 src header def 个人 哪些
经过我自己的测试和助教的检测,他的代码符合需求和规格的说明。
这里代码设计我们是从两个方面检查的:
经过我的分析和他的解释,我可以得到他的处理控制台输入的逻辑是这样的:
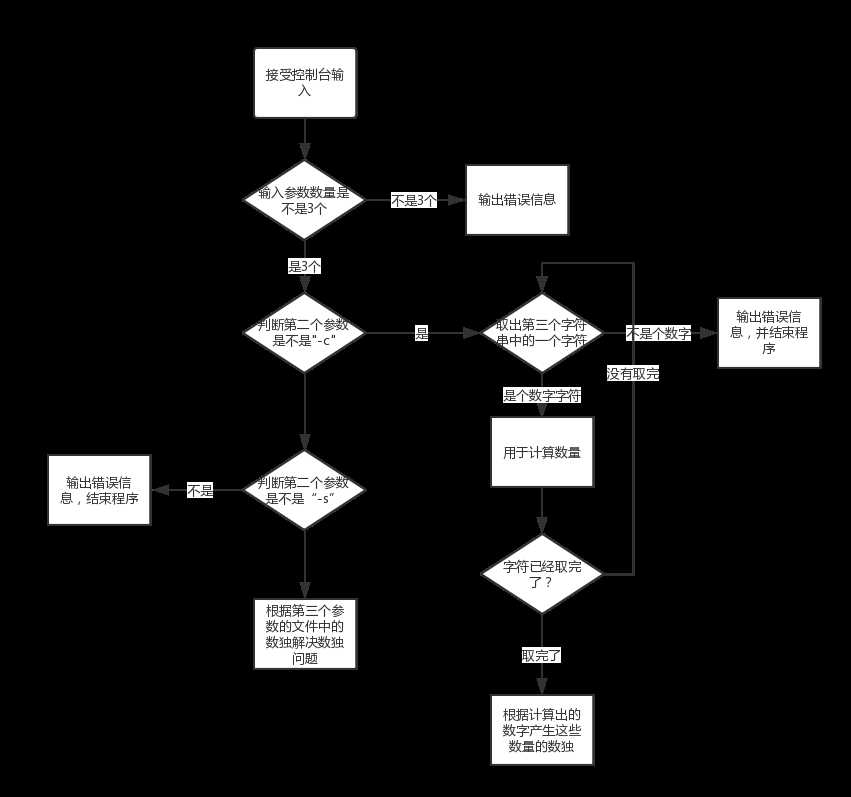
画了逻辑图就可以看出处理输入的这部分大致判断逻辑已经很完备了,还可以再更完备:
输入的数字的范围处理:对于输入的生成数独的数量,规定是N范围在1到100万之间,但是上面的逻辑并没有对输入的数字字符串做这方面的可能超出范围的检测。比如对于一段超长的数字字符串,超过了最大int的范围,这时就会产生错误。
较好的可扩展性需要代码模块之间的松耦合,模块内部的高聚合。在这次的作业中,我觉得大致可以分为这么几个大的模块:命令行参数处理模块,数独生成模块,数独解决模块,最后的结果写入模块。
经过仔细的检查,觉得我们在这方面的实现还不太完善,因为:
1.并没有把命令行参数处理模块化,而是直接把数独生成和数独解决这两个过程写在了main函数的if else逻辑中。这样命令行参数这个处理过程与数独的生成和解决耦合性过大。
2.最后文件的写入没有和数独生成/解决分开。
所以这里我们都需要改进。
总体来讲,我觉得他的代码满足简明,易读,无二义性的基本原则。我从两个方面评判他的代码可读性:
我觉得他的代码命名简洁明了:
例如:
int val, pos_row, pos_col;
整体上都是采用单词和单词之间加下划线的表示方法。
他的缩进让代码整体上看起来很舒服,例如:
A = new cross_link(rownum, colnum); rows = A->rows; cols = A->cols; head = A->head; for (int i = 0; i < rownum; i++) { int val = i % 9 + 1; int pos = i / 9; int row = pos / 9; int col = pos % 9; int block = (row / 3) * 3 + (col / 3); A->insert(i, pos); A->insert(i, 81 + row * 9 + val - 1); A->insert(i, 81 * 2 + col * 9 + val - 1); A->insert(i, 81 * 3 + block * 9 + val - 1); }
还有其他的分行,括号等用的都很好,但是有个缺点我觉的就是注释太少。
因为之前说的封装性不够,注释少,所以我觉得代码的可维护性还不够,还需要加强。
目前因为完成的功能较少,所以还没有用到特别明显的设计模式。
还是有一些硬编码的存在的,例如:
rstr[0][0] = 3;
str[i * 19 + 2 * j + 1] = ‘ ‘;
根据我和他的讨论,应该对平台没有依赖性。
根据交流和检查的结果,在他的代码中没有这样的可以直接调用库函数的功能。
确实还有一些无用代码是可以清除的。
目前还没有调用外部的函数,所以还没有这方面的检查。而且目前还没有太多的错误处理,只有在main函数中的命令行参数处的错误处理。
参数传递目前检查结果来看没有错误,字符串的长度是单字节。
经过检查,代码中没有断言。
检查了他的代码中的资源申请,有这么几处
经过细致的检查,他的代码中的数据结构只有这个;
typedef struct cross_node { cross_node *left; cross_node *right; cross_node *up; cross_node *down; bool ishead; int count; int row; int col; } *Cross;
其中包括四个方向上的指针,这个是有用的;
还有是否为头指针的判断ishead,这个也是有用的;
count成员是对于头结点来说的,头结点需要记录这一行或者这一列有多少个有效节点,这个也是有用的;
row,col表示节点所在的行,列。
综上,数据结构都是有用的,可能count只对于头结点有用,对非头结点无用,有点冗余。但是如果不同意写起来的话,可能需要定义两种数据结构了,所以还是统一写起来会实现的更好吧。
DLX算法本质上也是递归回溯的算法,所以最坏的情况可能是对于一些数独初局,回溯搜索太多。因为搜索是按照一定的顺序比如1-9来搜索的,所以固定的搜索顺序可能导致找到解之前已经回溯了大量的分支了。
经过检查,他的代码中没有反复创建类这个过程,无论是数独的解决和生成都是只创建一个类。
目前还不涉及系统和网络的调用。
他的代码确实没有足够的注释,但是命名清晰,可读性还可以。
他实现的单元测试有:
在代码更新后,可能会增加一些模块功能,可以为他们创建新的单元测试。
目前还不涉及特定领域的开发。
因为我使用了c++来编码,所以我参考了google的C++编码规范。因为刚接触C++所以其中有很多规范还没太看懂,不过也是有很多心得的:
在我能理解的范围内,google规定的代码规范和自己的代码风格有以下不同:
const variables.”,不提倡用宏定义我还是第一次听说,规范中的理由是这样的:①宏定义会让你所看到的代码和编译器看到的代码不一致。我觉得就是因为宏在预处理时会被替换,就可能会在替换后导致错误吧。②宏定义是全局的,这和C++一直倡导的命名空间有冲突,一般对于常量的宏定义用const来代替,函数用inline来代替。我在C中定义常量时喜欢用宏,看了这个规范我是很惊讶的,也许是没接触很大的工程吧,还没有遇到规范上说的宏定义的缺陷。不过既然规范这样说了,那么以后就尽量用常量和内联函数来代替宏定义吧。有很多我都没有想到,除了上面说的那几个规范,还有这些规范我之前是不了解的:
上面都是我能看懂的规范中对我有帮助的。
标签:缩进 写入文件 针对 声明 src header def 个人 哪些
原文地址:http://www.cnblogs.com/xxrxxr/p/7617948.html