标签:也有 步骤 计算 image dap 调整 一个 验证 选择
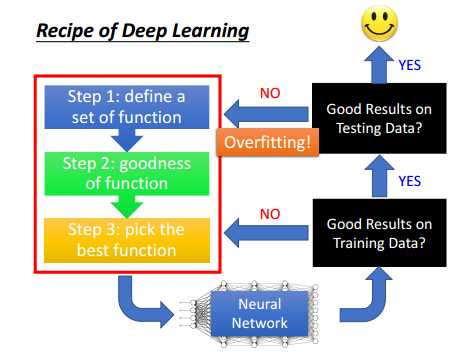
如上图,深度学习有3个基本的步骤:
1) 定义函数,即选择建立神经网络
2) 建立一个标准,判断第一步得到的函数或者网络好不好,相当于损失函数,误差越小,则该函数或网络越好
3) 选择误差最小的那个函数或网络
将我们之前选择的模型或网络用在训练集上,如果误差大,则说明模型不好,需要重新选择或者训练模型;如果该模型在训练集上误差小,那么就在测试集上计算误差,如果测试集上误差也很小,则说明这个模型很好;如果在测试集上误差比较大,则说明模型在训练集上过拟合了,需要重新训练或者选择模型。
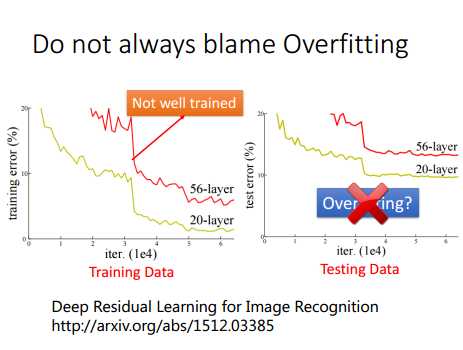
有时候,模型在测试集上误差大,并不一定时过拟合造成的。如下图,理论上说,神经网络层数越深,效果应该会更好,至少在训练集上误差会随着层数的增加误差减少(因为参数更多了,造成过拟合的话,那么训练集上误差就减少),但是实验效果却不是。56层的网络在训练集和测试集的误差都要比20层的误差大,因此56层神经网络模型并没有过拟合,而是56层的网络在训练的时候本身就没有训练好,得到了一个比较差的模型。
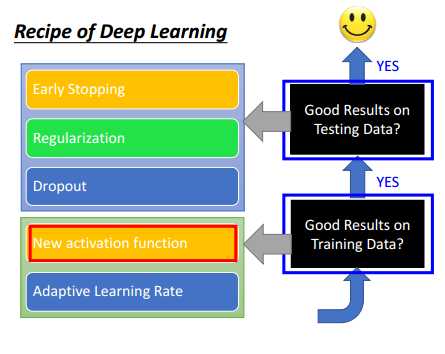
因此,该如何得到一个更好的模型呢?如下图所示,如果网络在训练集上误差就很大,那么可以选择新的激活函数或者自适应学习率方法来调整;如果网络在训练集上效果比较好,在测试集上效果比较差,则可以尝试使用提早结束训练、正则化和dropout等方法调整模型。
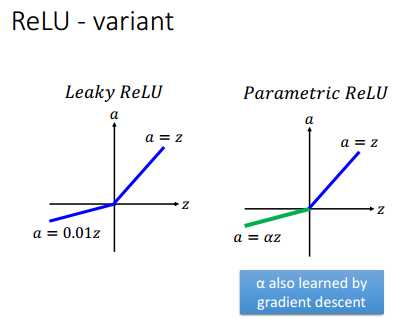
新的激活函数可以选择ReLU,数学表达式为f(x)=max(0,x),ReLU有如下几个有点:
1) 相比于sigmoid等激活函数,计算速度快,训练时收敛比较快
2) 与人体神经元效果比较相像
3) 解决了sigmoid激活函数梯度消失的情况

ReLU也有几种变形体,均是对ReLU的改进,有Leaky ReLU、Parametric ReLU和Exponential Linear Unit(ELU)等。
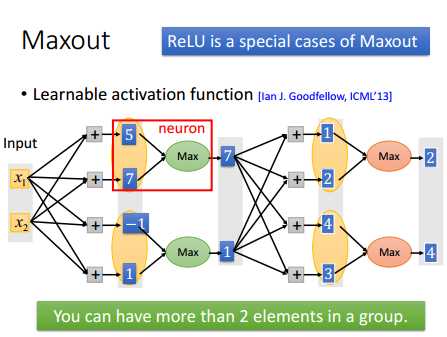
Maxout简单原理如下图,Maxout是一个可以学习的激活函数,Maxout主要工作方式就是选择每一组中最大的那个数作为输出值。如下图中,以两个元素为一组,5和7,-1和1,选择每组中最大的那个值,如5与7比较,选择7。
其实ReLU是Maxout的一种特例。
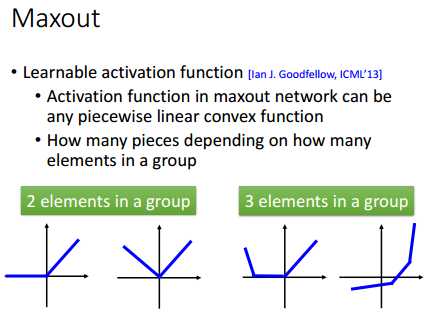
Maxout网络的激活函数可以是任意的分段线性凸函数,分段的数目取决于每组有多少个元素。
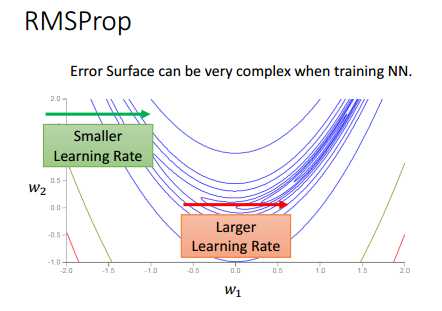
如下图,绿色箭头和红色箭头都是同一个方向(表示w1分量的梯度方向),很容易可以看出,绿色箭头的地方斜率比较大,因此,learning rate最好设小一点;而红色箭头的地方斜率比较小,因此,learning rate最好设大一点。
RMSProp算法迭代公式如下:

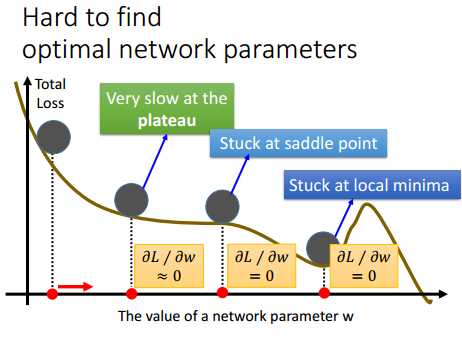
loss随着参数w的变化情况如下图所示,我们要找出w,使得loss最小。从下图中可以看出,loss曲线中,有好几个地方斜率几乎都等于0,如果采用梯度下降法,那么在斜率为0的地方,训练可能就会停止,只得到一个局部最优解。因此,这种情况下,是比较难找到网络的最优解参数。
在物理世界里,一个小球从斜坡上滚下来,虽然小球到了坡度接近0(即曲线斜率接近0)的地方,由于惯性的存在,小球还是会继续向前滚。
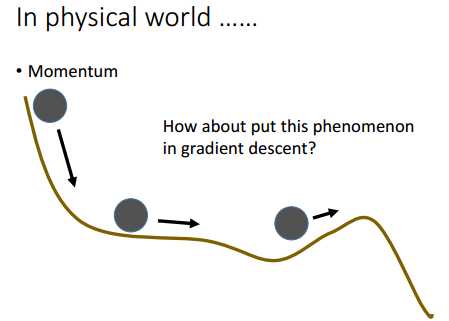
因此,根据上面的现象,神经网络在训练的时候引进Momentum(动量)的概念。如下图所示,训练的时候,每次参数的迭代,是当前位置的斜率与当前位置拥有的Momentum的叠加,因此,训练的时候,会比较容易的走出那些斜率为0的局部最优点,当然,要是局部最优点比较“深”,该方法可能也走不出局部最优点。
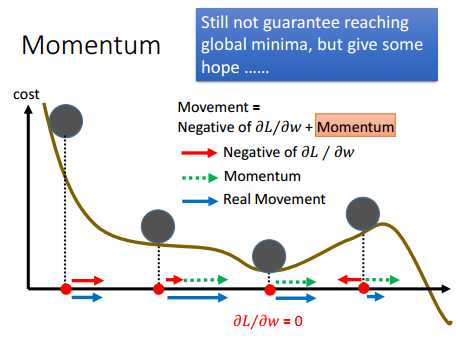
Momentum的迭代方式如下:

上面讲的RMSProp与Momentum结合,便是Adam算法。算法详情如下:

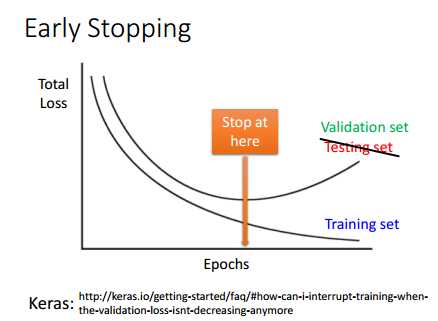
如下图所示,训练的时候,随着迭代的次数的增加,训练集上的误差loss不断的减少,但是在验证集上,随着迭代次数的增加,误差loss是先下降后上升的,显然,迭代次数很大的时候模型过拟合了。因此,我们在训练集和验证集上误差都比较小的时候,就应该停止训练了,选择这时候的模型参数。
正则化的加入,使得我们不仅要使误差loss达到最小,而且,同时我们也需要使神经网络参数的值接近于0。正则化其实就是在原来损失函数L的基础上,加上权重W的范数和,一般不考虑偏置b。

L2正则如下图:

L1正则如下图:

Dropout工作方式比较简单,就是训练的时候,让每个神经元节点以一定的概率不工作。
比如,在每次训练的时候(一个mini-batch为一次训练),打X部分节点不工作,其他节点正常工作。
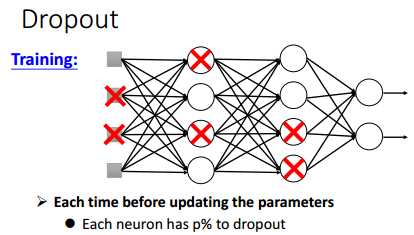
因此,实际工作的网络如下:
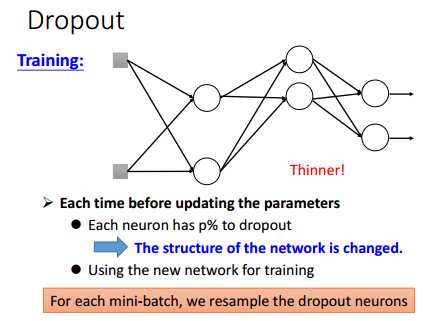
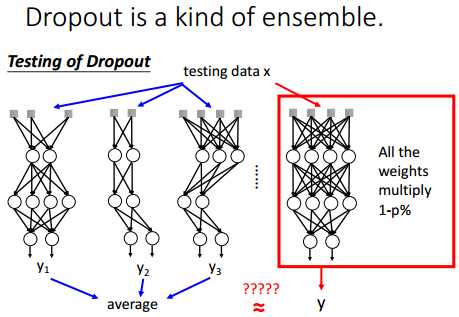
在测试的时候,每个神经元节点都正常工作,但是,所有的权重w要乘以1-p%(训练时,每个神经元不工作的概率为p%)。
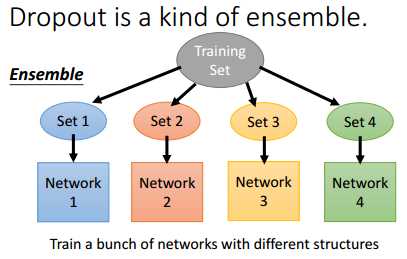
其实,dropout是一种ensemble。可以将dropout看成是很多网络的组合,最后取每个网络输出值的平均值。
参考:
【机器学习】李宏毅机器学习2017(台湾大学)(国语)第10课—深度学习技巧
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html
标签:也有 步骤 计算 image dap 调整 一个 验证 选择
原文地址:http://www.cnblogs.com/hejunlin1992/p/7620308.html