标签:sorted ras 分发 基于 space over ssi 结束 适合
SHOW FUNCTIONS;
DESCRIBE FUNCTION <function_name>;
日期函数
|
返回值类型 |
名称 |
描述 |
|
string |
from_unixtime(int unixtime) |
将时间戳(unix epoch秒数)转换为日期时间字符串,例如from_unixtime(0)="1970-01-01 00:00:00" |
|
bigint |
unix_timestamp() |
获得当前时间戳 |
|
bigint |
unix_timestamp(string date) |
获得date表示的时间戳 |
|
bigint |
to_date(string timestamp) |
返回日期字符串,例如to_date("1970-01-01 00:00:00") = "1970-01-01" |
|
string |
year(string date) |
返回年,例如year("1970-01-01 00:00:00") = 1970,year("1970-01-01") = 1970 |
|
int |
month(string date) |
|
|
int |
day(string date) dayofmonth(date) |
|
|
int |
hour(string date) |
|
|
int |
minute(string date) |
|
|
int |
second(string date) |
|
|
int |
weekofyear(string date) |
|
|
int |
datediff(string enddate, string startdate) |
返回enddate和startdate的天数的差,例如datediff(‘2009-03-01‘, ‘2009-02-27‘) = 2 |
|
int |
date_add(string startdate, int days) |
加days天数到startdate: date_add(‘2008-12-31‘, 1) = ‘2009-01-01‘ |
|
int |
date_sub(string startdate, int days) |
减days天数到startdate: date_sub(‘2008-12-31‘, 1) = ‘2008-12-30‘ |
|
返回值类型 |
名称 |
描述 |
|
- |
if(boolean testCondition, T valueTrue, T valueFalseOrNull) |
当testCondition为真时返回valueTrue,testCondition为假或NULL时返回valueFalseOrNull |
|
- |
COALESCE(T v1, T v2, ...) |
返回列表中的第一个非空元素,如果列表元素都为空则返回NULL |
|
- |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END |
a = b,返回c;a = d,返回e;否则返回f |
|
- |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END |
a 为真,返回b;c为真,返回d;否则e |
The following are built-in String functions are supported in hive:
|
返回值类型 |
名称 |
描述 |
|
Int |
length(string A) |
返回字符串长度 |
|
String |
reverse(string A) |
反转字符串 |
|
String |
concat(string A, string B...) |
合并字符串,例如concat(‘foo‘, ‘bar‘)=‘foobar‘。注意这一函数可以接受任意个数的参数 |
|
String |
substr(string A, int start) substring(string A, int start) |
返回子串,例如substr(‘foobar‘, 4)=‘bar‘ |
|
String |
substr(string A, int start, int len) substring(string A, int start, int len) |
返回限定长度的子串,例如substr(‘foobar‘, 4, 1)=‘b‘ |
|
String |
upper(string A) ucase(string A) |
转换为大写 |
|
String |
lower(string A) lcase(string A) |
转换为小写 |
|
String |
trim(string A) |
|
|
String |
ltrim(string A) |
|
|
String |
rtrim(string A) |
|
|
String |
regexp_replace(string A, string B, string C) |
Returns the string resulting from replacing all substrings in B that match the Java regular expression syntax(See Java regular expressions syntax) with C e.g. regexp_replace("foobar", "oo|ar", "") returns ‘fb.‘ Note that some care is necessary in using predefined character classes: using ‘\s‘ as the second argument will match the letter s; ‘\\s‘ is necessary to match whitespace, etc. |
|
String |
regexp_extract(string subject, string pattern, int intex) |
返回使用正则表达式提取的子字串。例如,regexp_extract(‘foothebar‘, ‘foo(.*?)(bar)‘, 2)=‘bar‘。注意使用特殊字符的规则:使用‘\s‘代表的是字符‘s‘;空白字符需要使用‘\\s‘,以此类推。 |
|
String |
parse_url(string urlString, string partToExtract) |
解析URL字符串,partToExtract的可选项有:HOST, PATH, QUERY, REF, PROTOCOL, FILE, AUTHORITY, USERINFO。 |
|
例如, |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1‘, ‘HOST‘)=‘facebook.com‘ |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1‘, ‘PATH‘)=‘/path/p1.php‘ |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1‘, ‘QUERY‘)=‘query=1‘,可以指定key来返回特定参数,key的格式是QUERY:<KEY_NAME>,例如QUERY:k1 |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1&field=2‘,‘QUERY‘,‘query‘)=‘1‘可以用来取出外部渲染参数key对应的value值 |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1&field=2‘,‘QUERY‘,‘field‘)=‘2‘ |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1#Ref‘, ‘REF‘)=‘Ref‘ |
||
|
parse_url(‘http://facebook.com/path/p1.php?query=1#Ref‘, ‘PROTOCOL‘)=‘http‘ |
||
|
String |
get_json_object(string json_string, string path) |
解析json字符串。若源json字符串非法则返回NULL。path参数支持JSONPath的一个子集,包括以下标记: |
|
$: Root object |
||
|
[]: Subscript operator for array |
||
|
&: Wildcard for [] |
||
|
.: Child operator |
||
|
String |
space(int n) |
返回一个包含n个空格的字符串 |
|
String |
repeat(string str, int n) |
重复str字符串n遍 |
|
String |
ascii(string str) |
返回str中第一个字符的ascii码 |
|
String |
lpad(string str, int len, string pad) |
左端补齐str到长度为len。补齐的字符串由pad指定。 |
|
String |
rpad(string str, int len, string pad) |
右端补齐str到长度为len。补齐的字符串由pad指定。 |
|
Array |
split(string str, string pat) |
返回使用pat作为正则表达式分割str字符串的列表。例如,split(‘foobar‘, ‘o‘)[2] = ‘bar‘。?不是很明白这个结果 |
|
Int |
find_in_set(string str, string strList) |
Returns the first occurance of str in strList where strList is a comma-delimited string. Returns null if either argument is null. Returns 0 if the first argument contains any commas. e.g. find_in_set(‘ab‘, ‘abc,b,ab,c,def‘) returns 3 |
UDTF即Built-in Table-Generating Functions
使用这些UDTF函数有一些限制:
1、SELECT里面不能有其它字段
如:SELECT pageid, explode(adid_list) AS myCol...
2、不能嵌套
如:SELECT explode(explode(adid_list)) AS myCol...不支持
3、不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY
如:SELECT explode(adid_list) AS myCol ... GROUP BY myCol
对于 JOIN 操作:
|
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid); |
实现过程为:
具体实现过程如图:
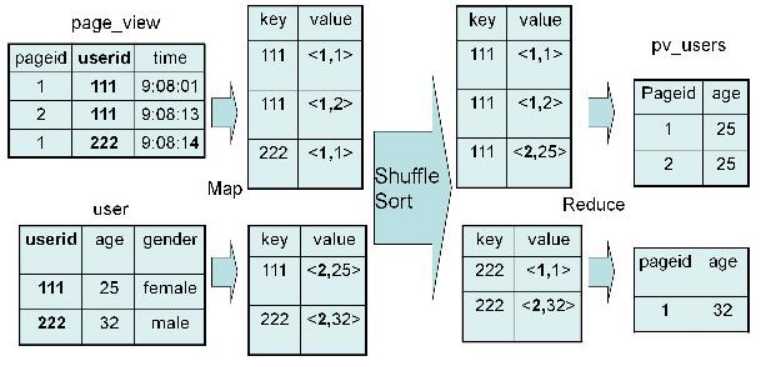
|
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age; |
具体实现过程如图:
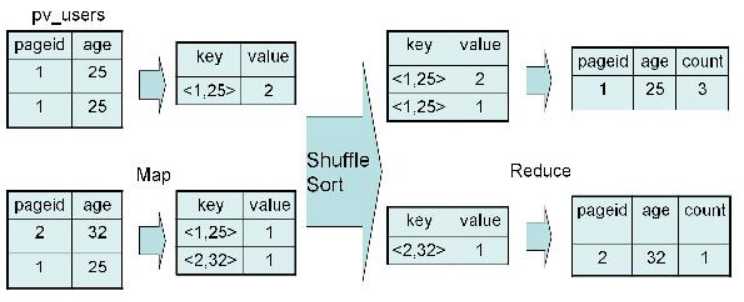
|
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age; |
实现过程如图:
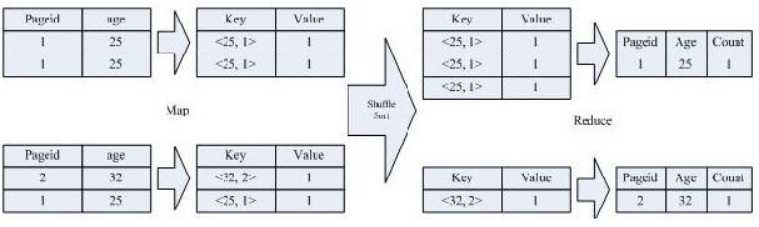
Hadoop和Hive都是用UTF-8编码的,所以, 所有中文必须是UTF-8编码, 才能正常使用
备注:中文数据load到表里面, 如果字符集不同,很有可能全是乱码需要做转码的, 但是hive本身没有函数来做这个
hive.exec.compress.output 这个参数, 默认是 false,但是很多时候貌似要单独显式设置一遍
否则会对结果做压缩的,如果你的这个文件后面还要在hadoop下直接操作, 那么就不能压缩了
当前的 Hive 不支持在一条查询语句中有多 Distinct。如果要在 Hive 查询语句中实现多Distinct,需要使用至少 n+1 条查询语句(n为distinct的数目),前 n 条查询分 别对 n 个列去重,最后一条查询语句对 n 个去重之后的列做 Join 操作,得到最终结果。
只支持等值连接
只支持INSERT/LOAD操作,无UPDATE和DELTE
不支持HAVING操作。如果需要这个功能要嵌套一个子查询用where限制
Hive不支持where子句中的子查询
SQL标准中,任何对null的操作(数值比较,字符串操作等)结果都为null。Hive对null值处理的逻辑和标准基本一致,除了Join时的特殊逻辑。
这里的特殊逻辑指的是,Hive的Join中,作为Join key的字段比较,null=null是有意义的,且返回值为true。检查以下查询:
select u.uid, count(u.uid)
from t_weblog l join t_user u on (l.uid = u.uid) group by u.uid;
查询中,t_weblog表中uid为空的记录将和t_user表中uid为空的记录做连接,即l.uid = u.uid=null成立。
如果需要与标准一致的语义,我们需要改写查询手动过滤null值的情况:
select u.uid, count(u.uid)
from t_weblog l join t_user u
on (l.uid = u.uid and l.uid is not null and u.uid is not null)
group by u.uid;
实践中,这一语义区别也是经常导致数据倾斜的原因之一。
分号是SQL语句结束标记,在HiveQL中也是,但是在HiveQL中,对分号的识别没有那么智慧,例如:
select concat(cookie_id,concat(‘;‘,’zoo’)) from c02_clickstat_fatdt1 limit 2;
FAILED: Parse Error: line 0:-1 cannot recognize input ‘<EOF>‘ in function specification
可以推断,Hive解析语句的时候,只要遇到分号就认为语句结束,而无论是否用引号包含起来。
解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成:
select concat(cookie_id,concat(‘\073‘,‘zoo‘)) from c02_clickstat_fatdt1 limit 2;
为什么是八进制ASCII码?
我尝试用十六进制的ASCII码,但Hive会将其视为字符串处理并未转义,好像仅支持八进制,原因不详。这个规则也适用于其他非SELECT语句,如CREATE TABLE中需要定义分隔符,那么对不可见字符做分隔符就需要用八进制的ASCII码来转义。
根据语法Insert必须加“OVERWRITE”关键字,也就是说每一次插入都是一次重写。那如何实现表中新增数据呢?
假设Hive中有表xiaojun1,
hive> DESCRIBE xiaojun1;
OK
id int
value int
hive> SELECT * FROM xiaojun1;
OK
3 4
1 2
2 3
现增加一条记录:
hive> INSERT OVERWRITE TABLE xiaojun1
SELECT id, value FROM (
SELECT id, value FROM xiaojun1
UNION ALL
SELECT 4 AS id, 5 AS value FROM xiaojun1 limit 1
) u;
结果是:
hive>SELECT * FROM p1;
OK
3 4
4 5
2 3
1 2
其中的关键在于, 关键字UNION ALL的应用, 即将原有数据集和新增数据集进行结合, 然后重写表.
INSERT OVERWRITE TABLE在插入数据时,是按照后面的SELECT语句中的字段顺序插入的. 也就说, 当id 和value 的位置互换, 那么value将被写入id, 同id被写入value.
INSERT OVERWRITE TABLE在插入数据时, 后面的字段的初始值应注意与表定义中的一致性. 例如, 当为一个STRING类型字段初始为NULL时:
NULL AS field_name // 这可能会被提示定义类型为STRING, 但这里是void
CAST(NULL AS STRING) AS field_name // 这样是正确的
又如, 为一个BIGINT类型的字段初始为0时:
CAST(0 AS BIGINT) AS field_name
Hive的排序关键字是SORT BY,它有意区别于传统数据库的ORDER BY也是为了强调两者的区别–SORT BY只能在单机范围内排序。
set mapred.reduce.tasks=2;
原值
select cookie_id,page_id,id from c02_clickstat_fatdt1
where cookie_id IN(‘1.193.131.218.1288611279693.0‘,‘1.193.148.164.1288609861509.2‘)
1.193.148.164.1288609861509.2 113181412886099008861288609901078194082403 684000005
1.193.148.164.1288609861509.2 127001128860563972141288609859828580660473 684000015
1.193.148.164.1288609861509.2 113181412886099165721288609915890452725326 684000018
1.193.131.218.1288611279693.0 01c183da6e4bc50712881288611540109914561053 684000114
1.193.131.218.1288611279693.0 01c183da6e4bc22412881288611414343558274174 684000118
1.193.131.218.1288611279693.0 01c183da6e4bc50712881288611511781996667988 684000121
1.193.131.218.1288611279693.0 01c183da6e4bc22412881288611523640691739999 684000126
1.193.131.218.1288611279693.0 01c183da6e4bc50712881288611540109914561053 684000128
hive> select cookie_id,page_id,id from c02_clickstat_fatdt1 where
cookie_id IN(‘1.193.131.218.1288611279693.0‘,‘1.193.148.164.1288609861509.2‘)
SORT BY COOKIE_ID,PAGE_ID;
SORT排序后的值
1.193.131.218.1288611279693.0 684000118 01c183da6e4bc22412881288611414343558274174 684000118
1.193.131.218.1288611279693.0 684000114 01c183da6e4bc50712881288611540109914561053 684000114
1.193.131.218.1288611279693.0 684000128 01c183da6e4bc50712881288611540109914561053 684000128
1.193.148.164.1288609861509.2 684000005 113181412886099008861288609901078194082403 684000005
1.193.148.164.1288609861509.2 684000018 113181412886099165721288609915890452725326 684000018
1.193.131.218.1288611279693.0 684000126 01c183da6e4bc22412881288611523640691739999 684000126
1.193.131.218.1288611279693.0 684000121 01c183da6e4bc50712881288611511781996667988 684000121
1.193.148.164.1288609861509.2 684000015 127001128860563972141288609859828580660473 684000015
select cookie_id,page_id,id from c02_clickstat_fatdt1
where cookie_id IN(‘1.193.131.218.1288611279693.0‘,‘1.193.148.164.1288609861509.2‘)
ORDER BY PAGE_ID,COOKIE_ID;
1.193.131.218.1288611279693.0 684000118 01c183da6e4bc22412881288611414343558274174 684000118
1.193.131.218.1288611279693.0 684000126 01c183da6e4bc22412881288611523640691739999 684000126
1.193.131.218.1288611279693.0 684000121 01c183da6e4bc50712881288611511781996667988 684000121
1.193.131.218.1288611279693.0 684000114 01c183da6e4bc50712881288611540109914561053 684000114
1.193.131.218.1288611279693.0 684000128 01c183da6e4bc50712881288611540109914561053 684000128
1.193.148.164.1288609861509.2 684000005 113181412886099008861288609901078194082403 684000005
1.193.148.164.1288609861509.2 684000018 113181412886099165721288609915890452725326 684000018
1.193.148.164.1288609861509.2 684000015 127001128860563972141288609859828580660473 684000015
可以看到SORT和ORDER排序出来的值不一样。一开始我指定了2个reduce进行数据分发(各自进行排序)。结果不一样的主要原因是上述查询没有reduce key,hive会生成随机数作为reduce key。这样的话输入记录也随机地被分发到不同reducer机器上去了。为了保证reducer之间没有重复的cookie_id记录,可以使用DISTRIBUTE BY关键字指定分发key为cookie_id。
select cookie_id,country,id,page_id,id from c02_clickstat_fatdt1 where cookie_id IN(‘1.193.131.218.1288611279693.0‘,‘1.193.148.164.1288609861509.2‘) distribute by cookie_id SORT BY COOKIE_ID,page_id;
1.193.131.218.1288611279693.0 684000118 01c183da6e4bc22412881288611414343558274174 684000118
1.193.131.218.1288611279693.0 684000126 01c183da6e4bc22412881288611523640691739999 684000126
1.193.131.218.1288611279693.0 684000121 01c183da6e4bc50712881288611511781996667988 684000121
1.193.131.218.1288611279693.0 684000114 01c183da6e4bc50712881288611540109914561053 684000114
1.193.131.218.1288611279693.0 684000128 01c183da6e4bc50712881288611540109914561053 684000128
1.193.148.164.1288609861509.2 684000005 113181412886099008861288609901078194082403 684000005
1.193.148.164.1288609861509.2 684000018 113181412886099165721288609915890452725326 684000018
1.193.148.164.1288609861509.2 684000015 127001128860563972141288609859828580660473 684000015
CREATE TABLE if not exists t_order(
id int, -- 订单编号
sale_id int, -- 销售ID
customer_id int, -- 客户ID
product _id int, -- 产品ID
amount int -- 数量
) PARTITIONED BY (ds STRING);
在表中查询所有销售记录,并按照销售ID和数量排序:
set mapred.reduce.tasks=2;
Select sale_id, amount from t_order
Sort by sale_id, amount;
这一查询可能得到非期望的排序。指定的2个reducer分发到的数据可能是(各自排序):
Reducer1:
Sale_id | amount
0 | 100
1 | 30
1 | 50
2 | 20
Reducer2:
Sale_id | amount
0 | 110
0 | 120
3 | 50
4 | 20
使用DISTRIBUTE BY关键字指定分发key为sale_id。改造后的HQL如下:
set mapred.reduce.tasks=2;
Select sale_id, amount from t_order
Distribute by sale_id
Sort by sale_id, amount;
这样能够保证查询的销售记录集合中,销售ID对应的数量是正确排序的,但是销售ID不能正确排序,原因是hive使用hadoop默认的HashPartitioner分发数据。
这就涉及到一个全排序的问题。解决的办法无外乎两种:
1.) 不分发数据,使用单个reducer:
set mapred.reduce.tasks=1;
这一方法的缺陷在于reduce端成为了性能瓶颈,而且在数据量大的情况下一般都无法得到结果。但是实践中这仍然是最常用的方法,原因是通常排序的查询是为了得到排名靠前的若干结果,因此可以用limit子句大大减少数据量。使用limit n后,传输到reduce端(单机)的数据记录数就减少到n* (map个数)。
2.) 修改Partitioner,这种方法可以做到全排序。这里可以使用Hadoop自带的TotalOrderPartitioner(来自于Yahoo!的TeraSort项目),这是一个为了支持跨reducer分发有序数据开发的Partitioner,它需要一个SequenceFile格式的文件指定分发的数据区间。如果我们已经生成了这一文件(存储在/tmp/range_key_list,分成100个reducer),可以将上述查询改写为
set mapred.reduce.tasks=100;
set hive.mapred.partitioner=org.apache.hadoop.mapred.lib.TotalOrderPartitioner;
set total.order.partitioner.path=/tmp/ range_key_list;
Select sale_id, amount from t_order
Cluster by sale_id
Sort by amount;
有很多种方法生成这一区间文件(例如hadoop自带的o.a.h.mapreduce.lib.partition.InputSampler工具)。这里介绍用Hive生成的方法,例如有一个按id有序的t_sale表:
CREATE TABLE if not exists t_sale (
id int,
name string,
loc string
);
则生成按sale_id分发的区间文件的方法是:
create external table range_keys(sale_id int)
row format serde
‘org.apache.hadoop.hive.serde2.binarysortable.BinarySortableSerDe‘
stored as
inputformat
‘org.apache.hadoop.mapred.TextInputFormat‘
outputformat
‘org.apache.hadoop.hive.ql.io.HiveNullValueSequenceFileOutputFormat‘
location ‘/tmp/range_key_list‘;
insert overwrite table range_keys
select distinct sale_id
from source t_sale sampletable(BUCKET 100 OUT OF 100 ON rand()) s
sort by sale_id;
生成的文件(/tmp/range_key_list目录下)可以让TotalOrderPartitioner按sale_id有序地分发reduce处理的数据。区间文件需要考虑的主要问题是数据分发的均衡性,这有赖于对数据深入的理解。
当Hive设定为严格模式(hive.mapred.mode=strict)时,不允许在HQL语句中出现笛卡尔积,这实际说明了Hive对笛卡尔积支持较弱。因为找不到Join key,Hive只能使用1个reducer来完成笛卡尔积。
当然也可以用上面说的limit的办法来减少某个表参与join的数据量,但对于需要笛卡尔积语义的需求来说,经常是一个大表和一个小表的Join操作,结果仍然很大(以至于无法用单机处理),这时MapJoin才是最好的解决办法。
MapJoin,顾名思义,会在Map端完成Join操作。这需要将Join操作的一个或多个表完全读入内存。
MapJoin的用法是在查询/子查询的SELECT关键字后面添加/*+ MAPJOIN(tablelist) */提示优化器转化为MapJoin(目前Hive的优化器不能自动优化MapJoin)。其中tablelist可以是一个表,或以逗号连接的表的列表。tablelist中的表将会读入内存,应该将小表写在这里。
PS:有用户说MapJoin在子查询中可能出现未知BUG。在大表和小表做笛卡尔积时,规避笛卡尔积的方法是,给Join添加一个Join key,原理很简单:将小表扩充一列join key,并将小表的条目复制数倍,join key各不相同;将大表扩充一列join key为随机数。
Hive不支持where子句中的子查询,SQL常用的exist in子句需要改写。这一改写相对简单。考虑以下SQL查询语句:
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以改写为
SELECT a.key, a.value
FROM a LEFT OUTER JOIN b ON (a.key = b.key)
WHERE b.key <> NULL;
一个更高效的实现是利用left semi join改写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key);
left semi join是0.5.0以上版本的特性。
Hadoop MapReduce程序中,reducer个数的设定极大影响执行效率,这使得Hive怎样决定reducer个数成为一个关键问题。遗憾的是Hive的估计机制很弱,不指定reducer个数的情况下,Hive会猜测确定一个reducer个数,基于以下两个设定:
1. hive.exec.reducers.bytes.per.reducer(默认为1000^3)
2. hive.exec.reducers.max(默认为999)
计算reducer数的公式很简单:
N=min(参数2,总输入数据量/参数1)
通常情况下,有必要手动指定reducer个数。考虑到map阶段的输出数据量通常会比输入有大幅减少,因此即使不设定reducer个数,重设参数2还是必要的。依据Hadoop的经验,可以将参数2设定为0.95*(集群中TaskTracker个数)。
Multi-group by
Multi-group by是Hive的一个非常好的特性,它使得Hive中利用中间结果变得非常方便。例如,
FROM (SELECT a.status, b.school, b.gender
FROM status_updates a JOIN profiles b
ON (a.userid = b.userid and
a.ds=‘2009-03-20‘ )
) subq1
INSERT OVERWRITE TABLE gender_summary
PARTITION(ds=‘2009-03-20‘)
SELECT subq1.gender, COUNT(1) GROUP BY subq1.gender
INSERT OVERWRITE TABLE school_summary
PARTITION(ds=‘2009-03-20‘)
SELECT subq1.school, COUNT(1) GROUP BY subq1.school
上述查询语句使用了Multi-group by特性连续group by了2次数据,使用不同的group by key。这一特性可以减少一次MapReduce操作。
Multi-distinct
Multi-distinct是淘宝开发的另一个multi-xxx特性,使用Multi-distinct可以在同一查询/子查询中使用多个distinct,这同样减少了多次MapReduce操作
Bucket是指将数据以指定列的值为key进行hash,hash到指定数目的桶中。这样就可以支持高效采样了。
如下例就是以userid这一列为bucket的依据,共设置32个buckets
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT ‘IP Address of the User‘)
COMMENT ‘This is the page view table‘
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘1‘
COLLECTION ITEMS TERMINATED BY ‘2‘
MAP KEYS TERMINATED BY ‘3‘
STORED AS SEQUENCEFILE;
Sampling可以在全体数据上进行采样,这样效率自然就低,它还是要去访问所有数据。而如果一个表已经对某一列制作了bucket,就可以采样所有桶中指定序号的某个桶,这就减少了访问量。
如下例所示就是采样了page_view中32个桶中的第三个桶。
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 32);
Partition就是分区。分区通过在创建表时启用partition by实现,用来partition的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时可以采用where语句,形似where tablename.partition_key > a来实现。
创建含分区的表
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT ‘IP Address of the User‘)
PARTITIONED BY(date STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘1‘
STORED AS TEXTFILE;
载入内容,并指定分区标志
LOAD DATA LOCAL INPATH `/tmp/pv_2008-06-08_us.txt` INTO TABLE page_view PARTITION(date=‘2008-06-08‘, country=‘US‘);
查询指定标志的分区内容
SELECT page_views.*
FROM page_views
WHERE page_views.date >= ‘2008-03-01‘ AND page_views.date <= ‘2008-03-31‘ AND page_views.referrer_url like ‘%xyz.com‘;
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询:
|
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x ON (u.userid = x.userid); |
如果 Join 的条件不相同,比如:
|
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x on (u.age = x.age); |
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的:
|
INSERT OVERWRITE TABLE tmptable SELECT * FROM page_view p JOIN user u ON (pv.userid = u.userid); INSERT OVERWRITE TABLE pv_users SELECT x.pageid, x.age FROM tmptable x JOIN newuser y ON (x.age = y.age); |
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
|
INSERT OVERWRITE TABLE pv_users SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid); |
可以在 Map 阶段完成 Join,如图所示:
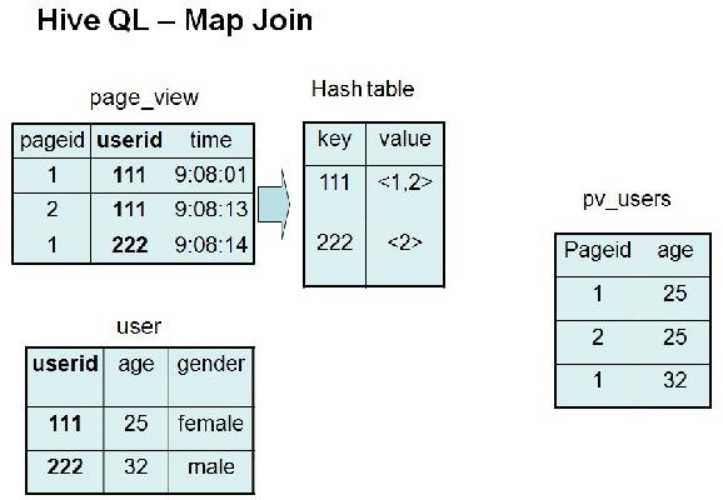
相关的参数为:
场景:如日志中,常会有信息丢失的问题,比如全网日志中的user_id,如果取其中的user_id和bmw_users关联,会碰到数据倾斜的问题。
解决方法1: user_id为空的不参与关联
Select * From log a
Join bmw_users b
On a.user_id is not null
And a.user_id = b.user_id
Union all
Select * from log a
where a.user_id is null;
解决方法2 :赋与空值分新的key值
Select *
from log a
left outer join bmw_users b
on case when a.user_id is null then concat(‘dp_hive’,rand() ) else a.user_id end = b.user_id;
结论:方法2比方法效率更好,不但io少了,而且作业数也少了。方法1 log读取两次,jobs是2。方法2 job数是1 。这个优化适合无效id(比如-99,’’,null等)产生的倾斜问题。把空值的key变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。附上hadoop通用关联的实现方法(关联通过二次排序实现的,关联的列为parition key,关联的列c1和表的tag组成排序的group key,根据parition key分配reduce。同一reduce内根据group key排序)
场景:一张表s8的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。s8的日志中有字符串商品id,也有数字的商品id,类型是string的,但商品中的数字id是bigint的。猜测问题的原因是把s8的商品id转成数字id做hash来分配reduce,所以字符串id的s8日志,都到一个reduce上了,解决的方法验证了这个猜测。
解决方法:把数字类型转换成字符串类型
Select * from s8_log a
Left outer join r_auction_auctions b
On a.auction_id = cast(b.auction_id as string);
MapReduce编程模型下开发代码需要考虑数据偏斜的问题,Hive代码也是一样。数据偏斜的原因包括以下两点:
1. Map输出key数量极少,导致reduce端退化为单机作业。
2. Map输出key分布不均,少量key对应大量value,导致reduce端单机瓶颈。
Hive中我们使用MapJoin解决数据偏斜的问题,即将其中的某个表(全量)分发到所有Map端进行Join,从而避免了reduce。这要求分发的表可以被全量载入内存。
极限情况下,Join两边的表都是大表,就无法使用MapJoin。
这种问题最为棘手,目前已知的解决思路有两种:
1. 如果是上述情况1,考虑先对Join中的一个表去重,以此结果过滤无用信息。这样一般会将其中一个大表转化为小表,再使用MapJoin 。
一个实例是广告投放效果分析,例如将广告投放者信息表i中的信息填充到广告曝光日志表w中,使用投放者id关联。因为实际广告投放者数量很少(但是投放者信息表i很大),因此可以考虑先在w表中去重查询所有实际广告投放者id列表,以此Join过滤表i,这一结果必然是一个小表,就可以使用MapJoin。
2. 如果是上述情况2,考虑切分Join中的一个表为多片,以便将切片全部载入内存,然后采用多次MapJoin得到结果。
一个实例是商品浏览日志分析,例如将商品信息表i中的信息填充到商品浏览日志表w中,使用商品id关联。但是某些热卖商品浏览量很大,造成数据偏斜。例如,以下语句实现了一个inner join逻辑,将商品信息表拆分成2个表:
select * from
(
select w.id, w.time, w.amount, i1.name, i1.loc, i1.cat
from w left outer join i sampletable(1 out of 2 on id) i1
)
union all
(
select w.id, w.time, w.amount, i2.name, i2.loc, i2.cat
from w left outer join i sampletable(1 out of 2 on id) i2
)
);
以下语句实现了left outer join逻辑:
select t1.id, t1.time, t1.amount,
coalease(t1.name, t2.name),
coalease(t1.loc, t2.loc),
coalease(t1.cat, t2.cat)
from (
select w.id, w.time, w.amount, i1.name, i1.loc, i1.cat
from w left outer join i sampletable(1 out of 2 on id) i1
) t1 left outer join i sampletable(2 out of 2 on id) t2;
上述语句使用Hive的sample table特性对表做切分。
文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响:
hive.merge.mapfiles = true 是否和并 Map 输出文件,默认为 True
hive.merge.mapredfiles = false 是否合并 Reduce 输出文件,默认为 False
hive.merge.size.per.task = 256*1000*1000 合并文件的大小
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
基于 Hash
参数包括:
hive.groupby.skewindata = false
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
标签:sorted ras 分发 基于 space over ssi 结束 适合
原文地址:http://www.cnblogs.com/duan2/p/7622275.html