标签:信息 编写 模板 telnet scrapy end enqueue ret col
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了。
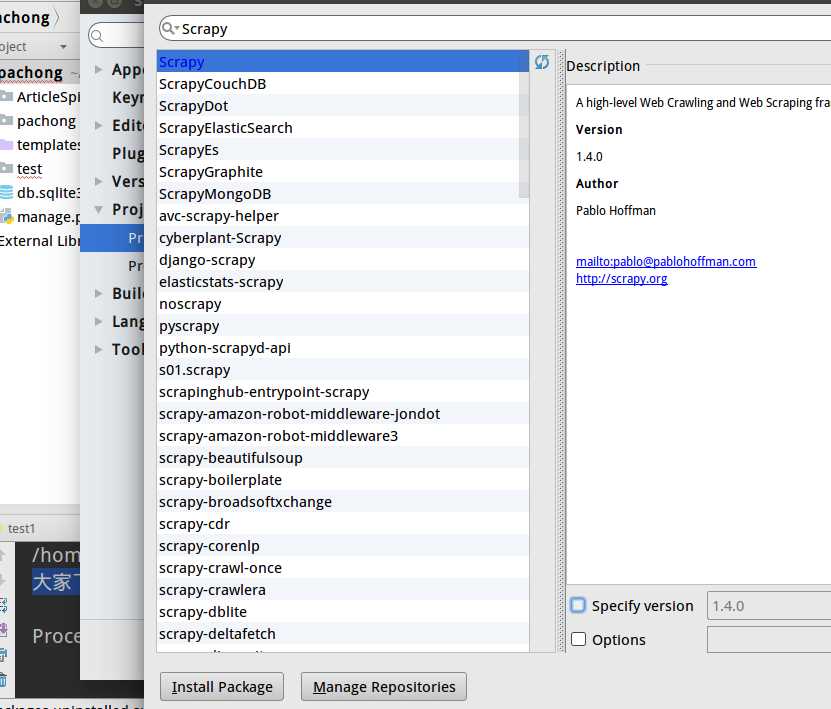
然后进入虚拟环境创建一个scrapy工程:
(third_project) bigni@bigni:~/python_file/python_project/pachong$ scr scrapy screendump script scriptreplay (third_project) bigni@bigni:~/python_file/python_project/pachong$ scrapy startproject ArticleSpider New Scrapy project ‘ArticleSpider‘, using template directory ‘/home/bigni/.virtualenvs/third_project/lib/python3.5/site-packages/scrapy/templates/project‘, created in: /home/bigni/python_file/python_project/pachong/ArticleSpider You can start your first spider with: cd ArticleSpider scrapy genspider example example.com (third_project) bigni@bigni:~/python_file/python_project/pachong$
我用pycharm进入创建好的scrapy项目,这个目录结构比较简单,而且有些地方很像Django
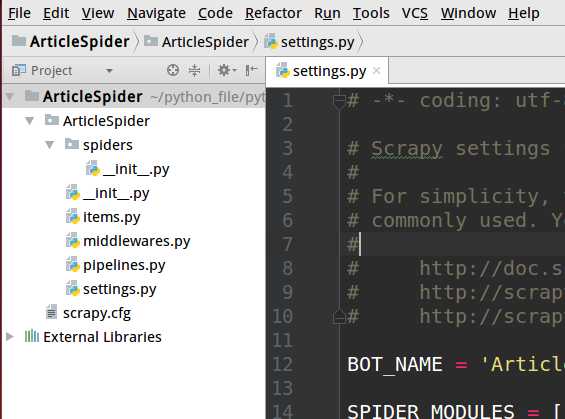
Spiders文件夹:我们可以在Spiders文件夹下编写我们的爬虫文件,里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。__init__.py:项目的初始化文件。
items.py:通过文件的注释我们了解到这个文件的作用是定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py:Spider中间件,在这个文件里我们可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。
pipelines.py:在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py:提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。
好比在Django中创建一个APP,在次创建一个爬虫
命令:
#注意:必须在该工程目录下
#创建一个名字为blogbole,爬取root地址为blog.jobbole.com 的爬虫;爬伯乐在线
scrapy genspider jobbole blog.jobbole.com
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy genspider jobbole blog.jobbole.com Created spider ‘jobbole‘ using template ‘basic‘ in module: ArticleSpider.spiders.jobbole
然后可以在spiders里看到新生成的文件jobbole.py
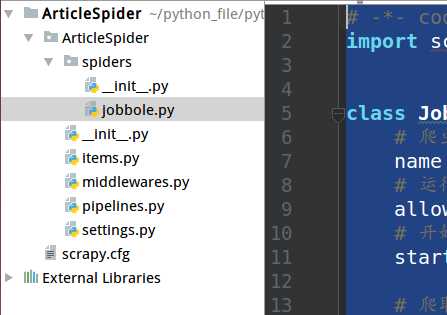
jobbole.py的内容如下:
# -*- coding: utf-8 -*- import scrapy class JobboleSpider(scrapy.Spider): # 爬虫名字 name = ‘jobbole‘ # 运行爬取的域名 allowed_domains = [‘blog.jobbole.com‘] # 开始爬取的URL start_urls = [‘http://blog.jobbole.com/‘] # 爬取函数 def parse(self, response): pass
在终端上执行 :scrapy crawl jobbole 测试下,其中jobbole是spidername
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy crawl jobbole 2017-08-27 22:24:21 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: ArticleSpider) 2017-08-27 22:24:21 [scrapy.utils.log] INFO: Overridden settings: {‘BOT_NAME‘: ‘ArticleSpider‘, ‘NEWSPIDER_MODULE‘: ‘ArticleSpider.spiders‘, ‘ROBOTSTXT_OBEY‘: True, ‘SPIDER_MODULES‘: [‘ArticleSpider.spiders‘]} 2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled extensions: [‘scrapy.extensions.logstats.LogStats‘, ‘scrapy.extensions.corestats.CoreStats‘, ‘scrapy.extensions.memusage.MemoryUsage‘, ‘scrapy.extensions.telnet.TelnetConsole‘] 2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled downloader middlewares: [‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware‘, ‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware‘, ‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware‘, ‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware‘, ‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘, ‘scrapy.downloadermiddlewares.retry.RetryMiddleware‘, ‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware‘, ‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware‘, ‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware‘, ‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware‘, ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘, ‘scrapy.downloadermiddlewares.stats.DownloaderStats‘] 2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled spider middlewares: [‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware‘, ‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware‘, ‘scrapy.spidermiddlewares.referer.RefererMiddleware‘, ‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware‘, ‘scrapy.spidermiddlewares.depth.DepthMiddleware‘] 2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled item pipelines: [] 2017-08-27 22:24:21 [scrapy.core.engine] INFO: Spider opened 2017-08-27 22:24:21 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2017-08-27 22:24:21 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 2017-08-27 22:24:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/robots.txt> (referer: None) 2017-08-27 22:24:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/> (referer: None) 2017-08-27 22:24:26 [scrapy.core.engine] INFO: Closing spider (finished) 2017-08-27 22:24:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {‘downloader/request_bytes‘: 438, ‘downloader/request_count‘: 2, ‘downloader/request_method_count/GET‘: 2, ‘downloader/response_bytes‘: 22537, ‘downloader/response_count‘: 2, ‘downloader/response_status_count/200‘: 2, ‘finish_reason‘: ‘finished‘, ‘finish_time‘: datetime.datetime(2017, 8, 27, 14, 24, 26, 588459), ‘log_count/DEBUG‘: 3, ‘log_count/INFO‘: 7, ‘memusage/max‘: 50860032, ‘memusage/startup‘: 50860032, ‘response_received_count‘: 2, ‘scheduler/dequeued‘: 1, ‘scheduler/dequeued/memory‘: 1, ‘scheduler/enqueued‘: 1, ‘scheduler/enqueued/memory‘: 1, ‘start_time‘: datetime.datetime(2017, 8, 27, 14, 24, 21, 136475)} 2017-08-27 22:24:26 [scrapy.core.engine] INFO: Spider closed (finished) (third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$
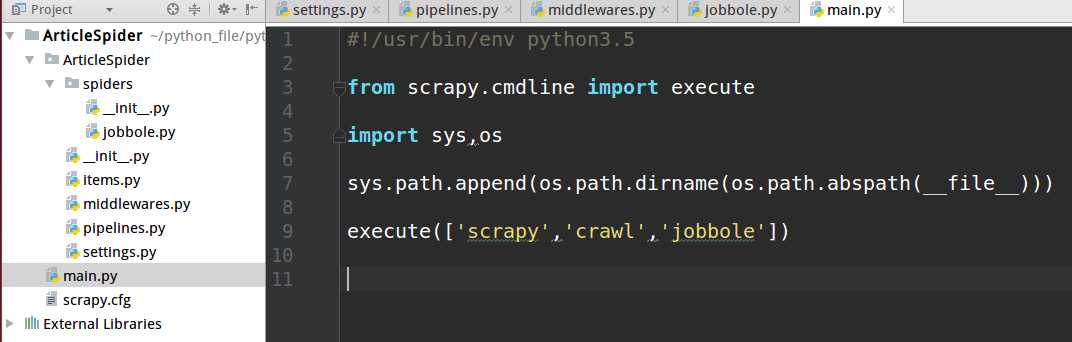
在pycharm 调试scrapy 执行流程,在项目里创建一个python文件,把项目路径写进sys.path,调用execute方法,传个数组,效果和上面在终端运行效果一样
PS:setting配置文件里建议把robotstxt协议停掉,否则scrapy会过滤某些url
# Obey robots.txt rules ROBOTSTXT_OBEY = False
标签:信息 编写 模板 telnet scrapy end enqueue ret col
原文地址:http://www.cnblogs.com/laonicc/p/7441532.html