标签:而不是 span 新闻 数学 cti 输出 alt 模型 不可用
这个问题需要从熵谈起, 根据香浓理论,熵是描述信息量的一种度量,如果某一事件发生的概率越小,也就是不确定性越大,那么熵就越大,或者说是信息量越大。 比如说,我们现实生活中,经常会有这样的场景,比如明星某薛,平时在我们这些吃瓜群众面前是一个人品极高,形象特别好,没有任何负面新闻,迷妹也是一波一波的。but, 突然有一天,被甩出各种有力证据,被证明是一个背!信!弃!义!的渣男!此刻,你有没有一种蒙圈的感觉,一时没缓过神来,因为信息量太大了 !有没有? 故事到此,我们以理论的角度来分析下,根据香浓理论,信息量 H = -log(p(X)), (至于为什么是-log函数来度量信息量,背后的数学原理,大家可以自己去深入了解下。)从H的函数表达中可以知道,信息量与事件发生的概率P(X)反相关。由于某薛之前在公众心目中的良好形象,大家认为他发生背信弃义之事(记为X)必定是小概率事件P(X),但事件X一旦发生,必定会满城风雨,因为香浓认为,这个信息量太大了,所以大家的反应会很强烈,都引发了UI界的妹纸们去用技术的手段证明证据的真伪,你说信息量大不大! 言归正传,在我们深度学习任务中,交叉熵经常被作为一种Loss Function(J),我们就以分类任务为例,给定假设函数h为Softmax, 由于假设函数softmax的定义完全满足概率的定义:非负性,规范性,可列可加性,所以softmax的输出完全可以理解为概率输出(通常说的置信度),即对某一输入X,预测输出为Y的事件可能性(概率)。
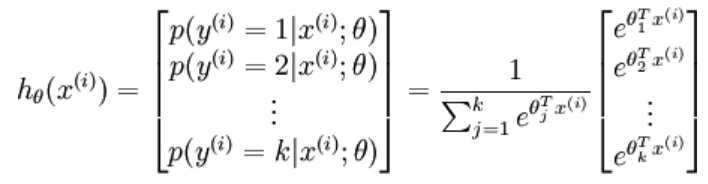
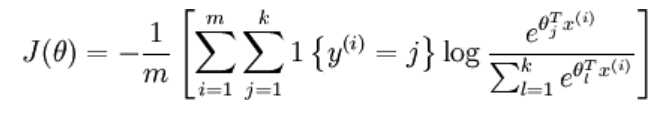 其中1{?} 是示性函数
其中1{?} 是示性函数
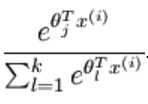 尽可能大。 示性函数这里必不可少,分类正确时,对loss才有贡献,不正确时,对loss贡献为0,我们最小化loss时,就是对正确分类的概率进行最大化。最后模型会学习到,以最大的概率输出正确的分类标签。
尽可能大。 示性函数这里必不可少,分类正确时,对loss才有贡献,不正确时,对loss贡献为0,我们最小化loss时,就是对正确分类的概率进行最大化。最后模型会学习到,以最大的概率输出正确的分类标签。标签:而不是 span 新闻 数学 cti 输出 alt 模型 不可用
原文地址:http://www.cnblogs.com/MatrixPlayer/p/7625493.html