标签:compile python语言 style dex 扩展 class 从零开始 def typeerror
所有的生成器都是迭代器
关于迭代器和生成器的一种定义:迭代器用于从集合中取出元素;生成器用于凭空生成元素。
Python中,所有的集合都是可以迭代的,在Python语言内部,迭代器用于支持:
如同标题本文的标题一样,这边文章主要讲解三个方面,可迭代对象,迭代器,生成器,下面逐个开始理解
先通过下面单词序列例子来理解:
1 import re 2 import reprlib 3 4 5 RE_WORD = re.compile(‘\w+‘) 6 7 8 class Sentence(object): 9 def __init__(self,text): 10 self.text = text 11 self.words = RE_WORD.findall(text) 12 13 def __getitem__(self, index): 14 return self.words[index] 15 16 def __len__(self): 17 return len(self.words) 18 19 def __repr__(self): 20 """ 21 用于打印实例化对象时,显示自定义内容, 22 reprlib.repr函数生成的字符换最多有30个字符,当超过怎会通过省略号显示 23 :return: 自定义内容格式 24 """ 25 return ‘Sentence(%s)‘ % reprlib.repr(self.text) 26 27 s = Sentence(‘"the time has come," the Walrus said,‘) 28 print(s) 29 print(type(s)) 30 for word in s: 31 print(word) 32 33 print(list(s))
上面代码的运行结果:
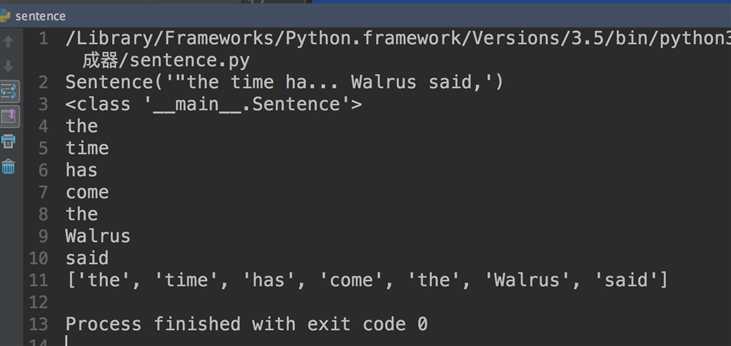
首先从结果来看,我们可以看出这个类的实例是可以迭代的,
并且我们从打印print(s)的结果可以看出,显示的也是我们定义的内容,如果我们在类中没有通过__repr__自定义,打印结果将为:
<__main__.Sentence object at 0x102a08fd0>
同时这里的实例化对象也是一个序列,所以我们可以通过s[0]这种方式来获取每个元素
我们都知道序列可以迭代,那么序列为啥可以迭代,继续深入理解
解释器需要迭代对象x时,会自动调用iter(x)
内置的iter函数作用:
任何python序列可以迭代的原因是,他们都实现了__getitem__方法,并且标准的序列也实现了__iter__方法。
关于如何判断x对象是否为可迭代对象,有两种方法:iter(x)或者isinstance(x,abc.Iterable)
那么这两种判断法有什么区别么?
其实从Python3.4之后建议是通过iter(x)方法来进行判断,因为iter方法会考虑__getitem__方法,而abc.Iterable不会考虑,所以iter(x)的判断方法更加准确
就像我最开始写的那个例子,分别通过这两种方式来测试,可以看出,其实这个类是可以迭代的,但是通过abc.Iterable的方式来判断,确实不可迭代的
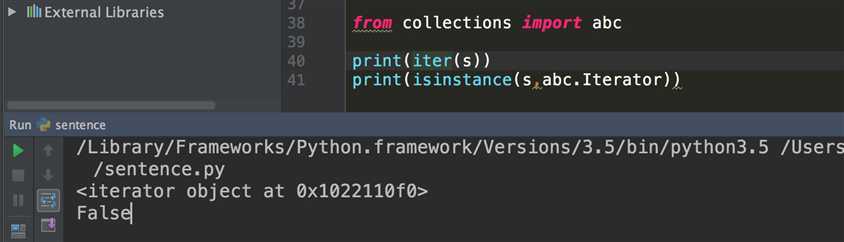
关于可迭代对象的一个小结:
首先我们要明白可迭代的对象和迭代器之间的关系:
Python从可迭代的对象中获取迭代器
一个简单的例子,当我们循环字符串的时候,字符串就是一个可迭代的对象,背后就是有迭代器,只不过我们看不到,下面为代码例子:
1 # 通过for循环方式 2 s = "ABC" 3 for i in s: 4 print(i) 5 6 7 print(‘‘.center(50, ‘-‘)) 8 9 # 通过while循环方式 10 it = iter(s) 11 12 while True: 13 try: 14 print(next(it)) 15 except StopIteration: 16 del it 17 break
这两种方式都可以获取可迭代对象里的内容,但是while循环的方式如果不通过try/except方式获取异常,最后就会提示StopIteration的错误,这是因为Python语言内部会处理for循环和其他迭代上下文(如列表推导,元组拆包等等)中的StopIteration
标准的迭代器接口有两个方法:
因为迭代器只需要__next__和__iter__两个方法,所以除了调用next()方法,以及捕获StopIteration异常之外,没有办法检查是否还有遗留元素,并且没有办法还原迭代器,如果想要再次迭代,就需要调用iter(...)传入之前构建迭代器的可迭代对象
我们把刚开始写的sentence类通过迭代器的方式来实现,要说的是这种写法不符合python的习惯做法,这里是为了更好的理解迭代器和可迭代对象之间的重要区别
1 import re 2 import reprlib 3 from collections import abc 4 5 6 RE_WORD = re.compile(‘\w+‘) 7 8 9 class Sentence: 10 11 def __init__(self,text): 12 self.text = text 13 self.words = RE_WORD.findall(text) 14 15 def __repr__(self): 16 return "Sentence(%s)" % reprlib.repr(self.text) 17 18 def __iter__(self): 19 return SentenceIterator(self.words) 20 21 22 class SentenceIterator: 23 24 def __init__(self,words): 25 self.words = words 26 self.index = 0 27 28 def __next__(self): 29 try: 30 word = self.words[self.index] 31 except IndexError: 32 raise StopIteration() 33 self.index += 1 34 return word 35 36 def __iter__(self): 37 return self
这样我们就可以很清楚的明白,我们定义了一个SenteneIterator是一个迭代器,也实现了迭代器应该有的两种方法:__next__和__iter__方法,这样我们通过 issubclass(SentenceIterator,abc.Iterator)检查
这里我们还能看到可迭代对象和迭代器的区别:
可迭代对象有__iter__方法,每次都实例化一个新的迭代器
迭代器要实现__next__和__iter__两个方法,__next__用于获取下一个元素,__iter__方法用于迭代器本身,因此迭代器可以迭代,但是可迭代对象不是迭代器
有人肯定在想在Sentence类中实现__next__方法,让Sentence类既是可迭代对象也是自身的迭代器,但是这种想法是不对的,这是也是常见的反模式。所以可迭代对象一定不能是自身的迭代器
先通过用生成器方式替换上个例子中SentenceIterator类,例子如下:
1 import re 2 import reprlib 3 4 5 RE_WORD = re.compile(‘\w+‘) 6 7 8 class Sentence: 9 10 def __init__(self,text): 11 self.text = text 12 self.words = RE_WORD.findall(text) 13 14 def __repr__(self): 15 return ‘Sentence(%s)‘ % reprlib.repr(self.text) 16 17 def __iter__(self): 18 for word in self.words: 19 yield word
在上面这个代码中,我们通过yield关键字,这里的__iter__函数其实就是生成器函数,迭代器其实是生成器对象,每次调用__iter__方法,都会自动创建。
Python函数定义体中有yield关键字,该函数就是生成器函数。
生成器函数会创建一个生成器对象,包装生成器函数的定义体,把生成器传给next(...)函数时,生成器函数会向前,执行函数定义体中的下一个yield语句,返回产出的值,并在函数定义体的当前位置暂停,最终,函数的定义体返回时,外层的生成器对象会抛出SotpIteration异常,这一点和迭代器协议一致。
下面是一个生成器的例子:
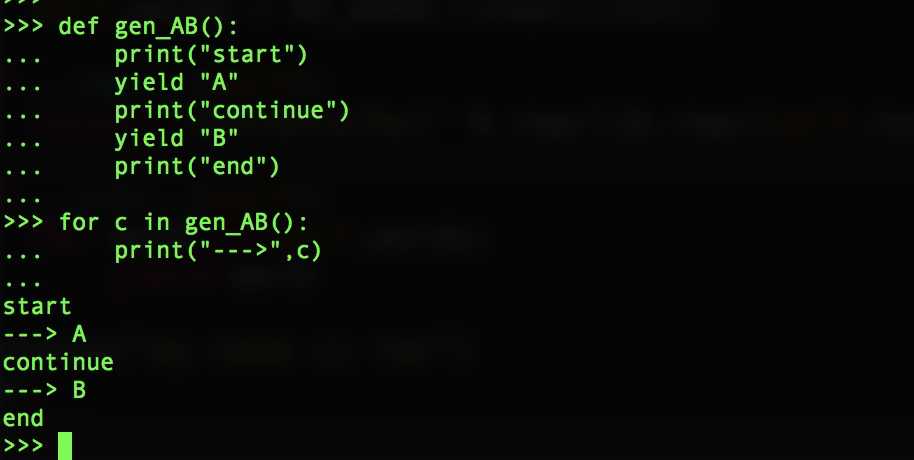
这里其实我们要明白进行for循环的过程其实就是在隐式的调用next()函数
当我们写了好几种Sentence类的时候,感觉我们通过生成器方式实现的挺简单了,其实还有更简单的方法的,代码例子如下,这里的finditer函数构建了一个迭代器:
1 import re 2 import reprlib 3 4 5 RE_WORD = re.compile(‘\w+‘) 6 7 8 9 class Sentence: 10 11 def __init__(self,text): 12 self.text = text 13 14 def __repr__(self): 15 return ‘Sentence(%s)‘ % reprlib.repr(self.text) 16 17 def __iter__(self): 18 for match in RE_WORD.finditer(self.text): 19 yield match.group()
生成器表达式可以理解为列表推导的惰性版本,不会直接构成列表,而是返回一个生成器,按需惰性生成元素。
关于实现Sentence,还可以通过生成器表达式。
1 import re 2 import reprlib 3 4 5 RE_WORD = re.compile(‘\w+‘) 6 7 8 class Sentence: 9 10 def __init__(self,text): 11 self.text = text 12 13 def __repr__(self): 14 return ‘Sentence(%s)‘ % reprlib.repr(self.text) 15 16 def __iter__(self): 17 return (match.group() for match in RE_WORD.finditer(self.text))
标签:compile python语言 style dex 扩展 class 从零开始 def typeerror
原文地址:http://www.cnblogs.com/zhaof/p/7628049.html