标签:爬取 书籍 开始 查找 随笔 nbsp log html 使用
第五部分开始,我新写的随笔是从python核心编程上总结的,详细查找可以在书中。
正则表达式是在书籍的第一章节。
之前写过一些爬虫的程序,所以对这方面还是挺熟悉的。不过既然是笔记就截取点容易忘的,当做笔记了。
在python中主要的正则表达式的库是re模块,但是对于爬虫来说,针对html的结构的爬取还有其他更方便的库,例如Xpath等,这在我写的新浪爬虫中都有。
以下贴以下正则的用法:
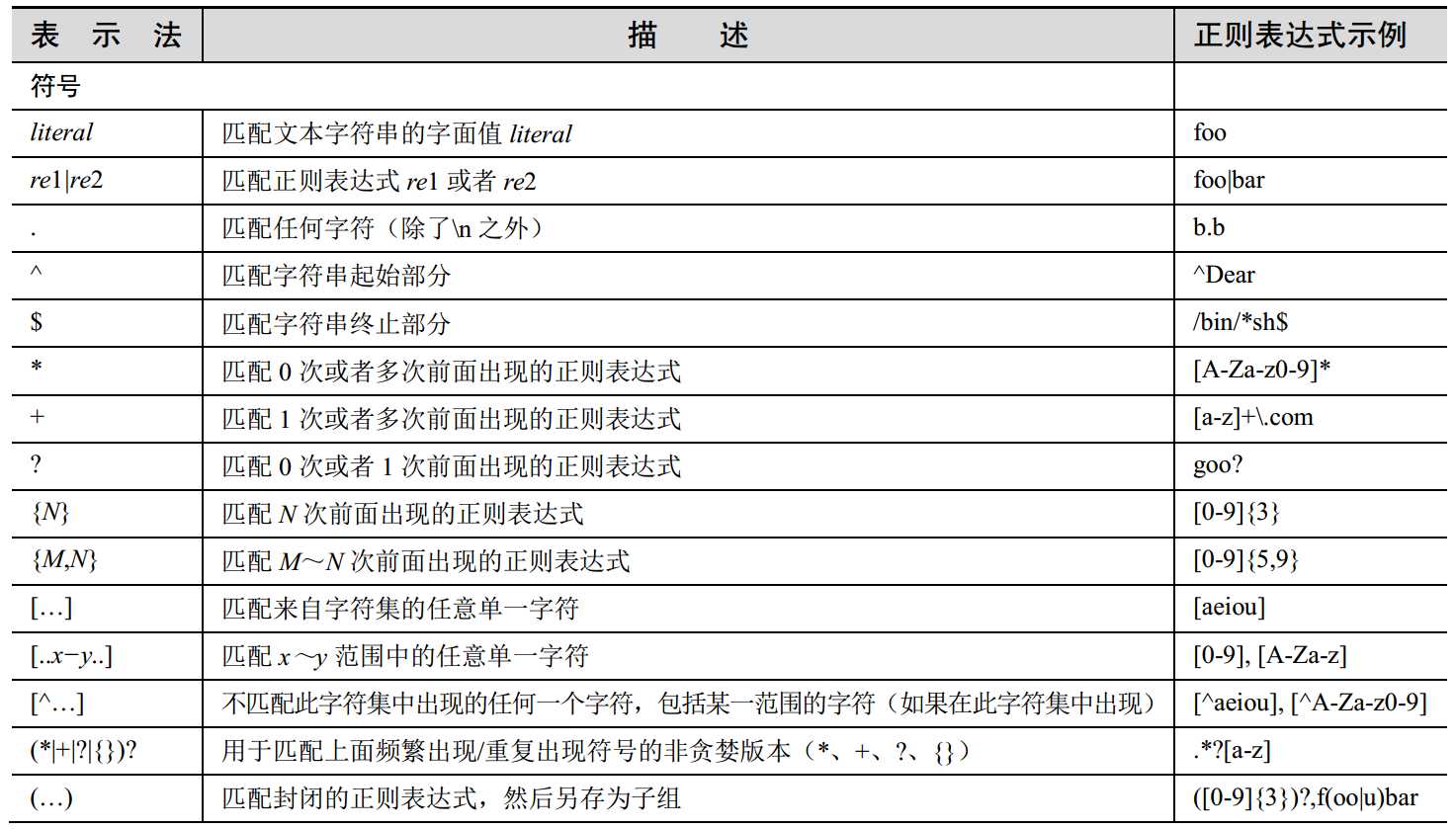
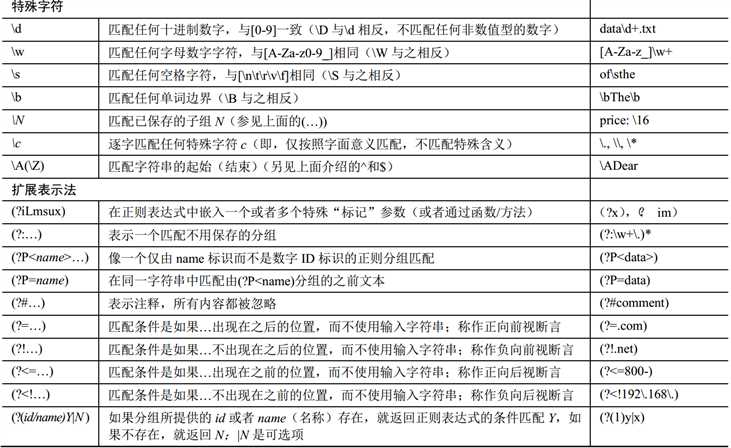
以上就是一些正则的表达式的意义。
特别需要注意的一点是,在匹配特殊字符的时候需要使用转义符号\,比如匹配点时候要用\.,否则就会和上边图中的.所冲突。
标签:爬取 书籍 开始 查找 随笔 nbsp log html 使用
原文地址:http://www.cnblogs.com/lixiaofou/p/7628108.html