标签:页面 跳转 内容 格式 一个 gecko 代码 多个 like
推荐:(http://cuiqingcai.com/1052.html),本文是我在看了静觅的视屏教程后的笔记.
1、一个HTML页面里可以有多个URL地址;
2、一个URL只能指向一个HTML页面。
3.HTTP是传输协议
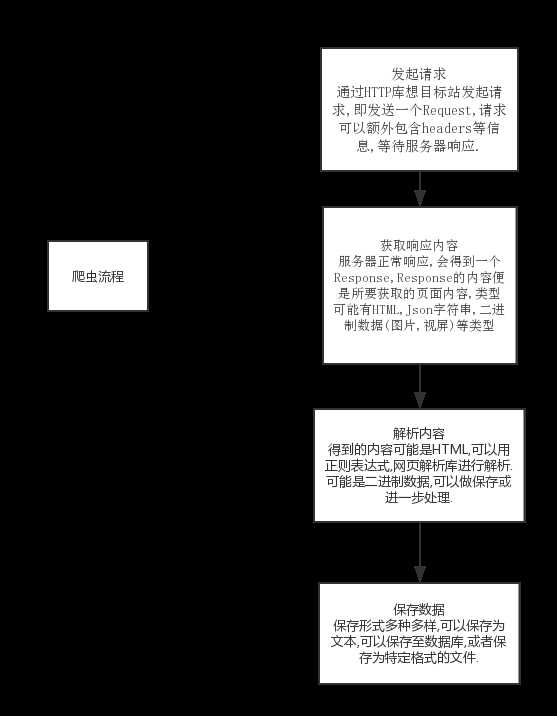
Request与Response的流程

(1)游览器发送消息给该网址所在的服务器,这个过程叫做HTTP Request.
(2)服务器收到游览器发送的消息后,根据游览器发送消息的内容,做出相应的处理,然后把这个消息传送费游览器.这个过程叫做HTTP Response.
(3)游览器收到服务器的Response信息后,会对信息进行相应的处理,然后展示.
Request包含的内容

Response的内容

Request 和 response的过程
import requests headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36‘} response = requests.get(‘http://jandan.net/ooxx‘,headers = headers) print(response.text) #打印源代码 print(response.headers) #打印请求头 print(response.status_code) #打印请求状态码
怎么抓取数据?

response = requests.get(‘http://wx3.sinaimg.cn/mw600/006d1Z6yly1fkaolncvg4j30zk0npn1u.jpg‘) #获取HTML print(response.content) #以二进制格式打印出来 with open(‘1.jpg‘,‘wb‘) as f: #open第一个参数为名称第二个参数为命令 ‘wb‘以二进制格式写入 f.write(response.content) f.close()
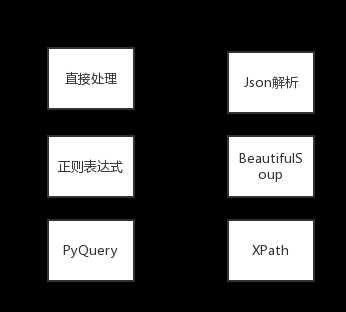
解析方式
怎么解决JavaScript渲染的问题?
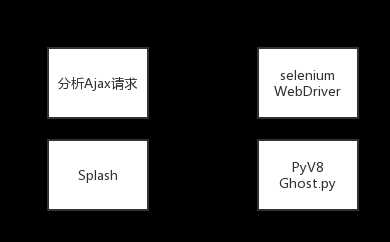
from selnium import webdriver #使用selnium库 shell模式下 pip install selnium 再下载chromedriver并放在加入pyth的环境的文件夹 driver = webdriver.Chrome() driver.get(‘URL‘) #使用chrome跳转到你想要的网页 print(driver.page_source)
保存数据

标签:页面 跳转 内容 格式 一个 gecko 代码 多个 like
原文地址:http://www.cnblogs.com/Vliant/p/7638142.html