标签:des style blog http color io os 使用 ar
php中的内存分配有用类似emalloc这样的函数,emalloc实际上是C语言中的malloc的一层封装,php启动后,会向OS申请一块内存,可以理解为内存池,以后的php分配内存都是在这块内存池中进行的,以至于efree,也不会向OS退回内存,而只是设置标志位,标识efree这块内存不再使用了,这样做的好处是,速度快,避免系统调用,因为频繁的从用户态和内核态之间的切换是很费CPU的。
C语言的malloc函数的后面是glibc(内存管理系统) , 前段时间在看到php内存分配时,看到了emalloc,又延伸看到malloc,只是知道malloc向OS索要一部分内存,但内在的原理不知,索性google ,baidu了malloc背后的知识,脑洞大开,不禁惊叹,自己掌握的知识太少了,虽然现在主要使用php写东西,基本不用C,但知道一些底层的东西,也是有好处的。
一般linux默认使用的内存管理系统是ptmalloc
先上一个内存分布的图
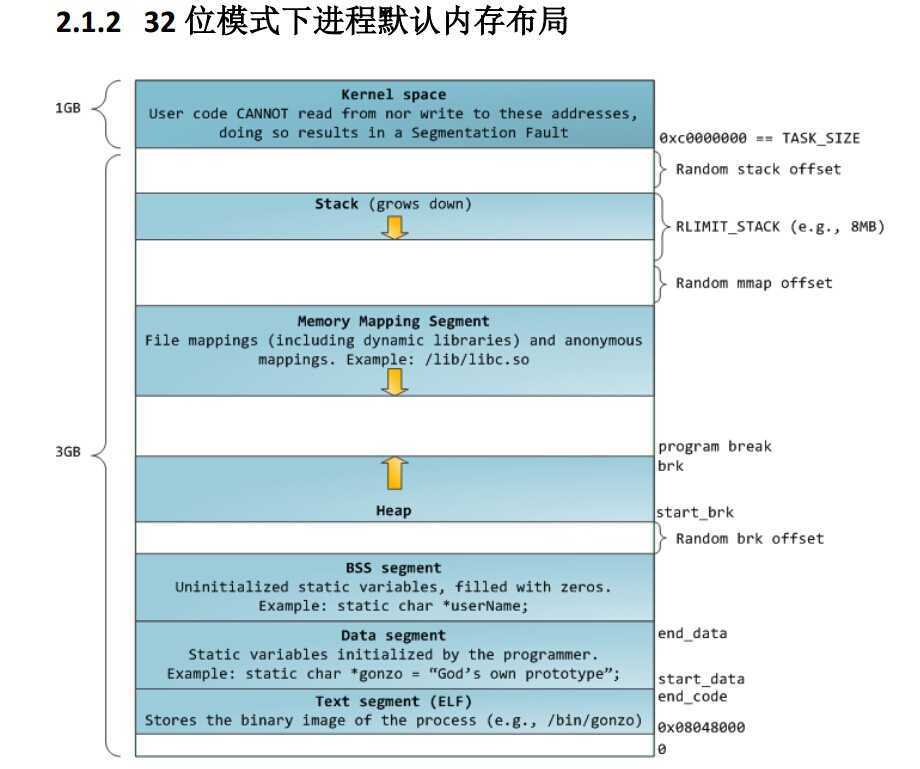
从低地址到高地址依次是:
1)代码段
2)数据段 :定义的全局变量和静态变量
3)BSS段:未定义的全局变量和静态变量
4)常量区
5)heap:堆
6)mmap:内存映射段
7)stack:栈
8)kenal space: 内核空间
ptmalloc管理的就是这个heap,
在写C程序时,肯定会有一个main函数,在执行时,main不是第一个执行的函数,而是有另一个函数优先于他先执行,这个时候,他会向OS要一大块内存,也可以理解为内存池,这个优先运行的函数也会进行一些分配内存,释放内存之类的操作,我们写C程序中关于分配内存的操作也是基于这个内存池进行的
ptmalloc把管理的内存分成若干大小的chunk,其结构体如下
struct malloc_chunk{ INTERNAL_SIZE_T pre_size; INTERNAL_SIZE_T size; struct malloc_chunk *fd; struct malloc_chunk *bk; struct malloc_chunk *fd_nextsize; struct malloc_chunk *bk_nextsize; };
pre_size:表示前一个空闲的chunk的大小,如果不空闲,则该字段无意义
size:当前chunk的大小
fd,bk:只有当当前的chunk为空闲时,才有用,fd表示forward下一个空闲chunk bk表示上一个空闲chunk ,
当当前的chunk不为空闲时,即分配出去了,fd,bk 是没用的,,因为该chunk已从相应bins中剔除了
fd_nextrsize,bk_nextsize:当当前chunk存放于large bins时,largs bins里里面的chunk是从大到小排列的,有可能存在多个相同大小的chunk,这时fd_nextsize,bk_nextsize就派上了用场,fd_nextsize表示大于当前chunk的第一个空闲chunk,
bk_nextsize表示小于当前chunk大小的第一个空闲chunk, 当当前chunk被分配出去时,这两个字段也就没用了,因为该chunk已从相应bins中剔除了
之前看栈与堆的区别时,有的文章说malloc是在一个被链表连接起来的未使用的内存进行寻找的,这么说也没错,只是将未使用的内存连接起来的不是一个链表,而是多个
ptmalloc把空闲的chunk按大小,放进4个bins(箱子中),这些箱子可以看做是 指针数组+双向循环链表
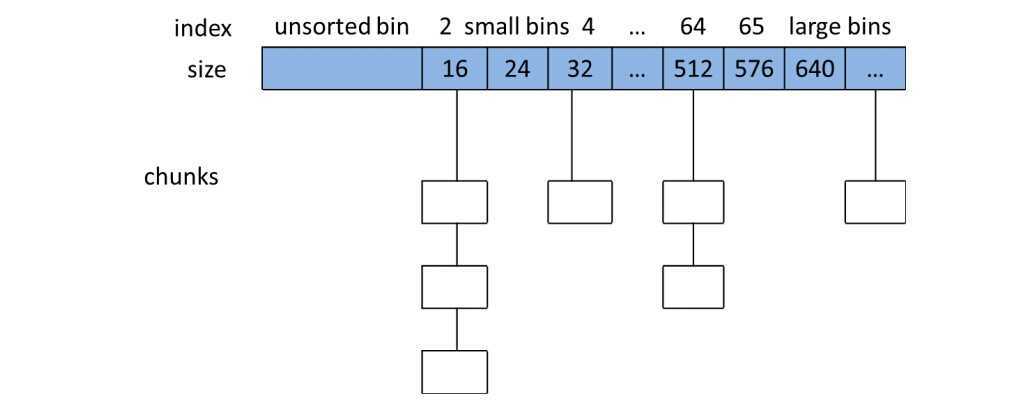
unsorted bins : 缓冲区
small bins:一共63个,每一列bins子中的chunk大小都相同,但不同列的bins中的chunk大小不同,相差8字节
large bins:称为不定长箱子,从512字节开始,从大到小排序
fast bins : 大概有10个bin,可以理解为高速缓存区,基本上在64字节以下的空闲chunk,都存放这里,但在某种情况下,会合并,并放到unsorted bin中
__init_malloc()
1)如果要分配的内存大于fastbins中最大的chunk,根据待分配内存的大小,计算出索引值,再通过该索引找到头指针,取出第一个chunk, 返回给调用者
2)从smallbins中查找,如果找到返回chunk
3)smallbins中找不到,则从unsorted bins中查找,遍历它
如果unsorted bins只有一个chunk,并且该chunk大于待分配内存大小,则进行切割,余下的chunk仍放回unsorted bins中
如果unsorted bins中的某一chunk大小 正好等于 待分配内存大小,则返回,并从unsorted bins中删除
如果unsorted bins中的某一chunk大小 属于small bins的范围,则放入small bins的头部
如果unsorted bins中的某一chunk大小 属于big bins的范围,则根据情况判断:
根据unsorted binsk 中这个chunk 的大小,计算出所在big bins的索引值,根据此值,找到链表头 (放入bitMap中,表示该chunk可使用)
如unsorted bins中这个chunk 的大小 小于这个链表中最小的chunk,那么直接放到后面
如unsorted bins中这个chunk 的大小 不小于这个链表中最小的chunk, 那么就要循环这个链表,直到找到一个合适位置
4)从big bins中查找,找到链表头后,反向遍历此链表,直到找到第一个大小 大于待分配的chunk,然后进行切割,如果有余下的,则放入unsorted bin中去
5)将上面的索引值加1,进行位图法搜索,位图法简单来说是,利用整形int中的每一个位,可以表示一个数字,这样可节省空间,
6)如果还没有找到,对top chunk进行分割,
7)如果存在fastbin, 则进行合并,再进行查找
8)利用mmap
位图法:
C语言中 int a; 在8 size大小的机器中, a占32位,即
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
为了减少空间,将数字按位放到上面的表格中去,例如数字8,二进制为1000
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
为了计算数字8在表格中的位置,可将8对31求余 ,也可以这样:8&31=8
对于,整形数组 int a[4] , 数字 12, 位于第0行,第12列
第0行 12/32 12>>5
第12列 a[0]|=1<<(12&(1<<5-1))
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
对于ptmalloc来说,前两行全是small bins ,后两行全是big bins,所以在进行bit map查找时,因为索引值已加1,所以找到的第一个单元格如果是空闲的,则大小必定满足条件

/* Malloc implementation for multiple threads without lock contention. Copyright (C) 1996-2006, 2007, 2008, 2009 Free Software Foundation, Inc. This file is part of the GNU C Library. Contributed by Wolfram Gloger <wg@malloc.de> and Doug Lea <dl@cs.oswego.edu>, 2001. The GNU C Library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. The GNU C Library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details. You should have received a copy of the GNU Lesser General Public License along with the GNU C Library; see the file COPYING.LIB. If not, write to the Free Software Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA. */ /* This is a version (aka ptmalloc2) of malloc/free/realloc written by Doug Lea and adapted to multiple threads/arenas by Wolfram Gloger. There have been substantial changesmade after the integration into glibc in all parts of the code. Do not look for much commonality with the ptmalloc2 version. * Version ptmalloc2-20011215 based on: VERSION 2.7.0 Sun Mar 11 14:14:06 2001 Doug Lea (dl at gee) * Quickstart In order to compile this implementation, a Makefile is provided with the ptmalloc2 distribution, which has pre-defined targets for some popular systems (e.g. "make posix" for Posix threads). All that is typically required with regard to compiler flags is the selection of the thread package via defining one out of USE_PTHREADS, USE_THR or USE_SPROC. Check the thread-m.h file for what effects this has. Many/most systems will additionally require USE_TSD_DATA_HACK to be defined, so this is the default for "make posix". * Why use this malloc? This is not the fastest, most space-conserving, most portable, or most tunable malloc ever written. However it is among the fastest while also being among the most space-conserving, portable and tunable. Consistent balance across these factors results in a good general-purpose allocator for malloc-intensive programs. The main properties of the algorithms are: * For large (>= 512 bytes) requests, it is a pure best-fit allocator, with ties normally decided via FIFO (i.e. least recently used). * For small (<= 64 bytes by default) requests, it is a caching allocator, that maintains pools of quickly recycled chunks. * In between, and for combinations of large and small requests, it does the best it can trying to meet both goals at once. * For very large requests (>= 128KB by default), it relies on system memory mapping facilities, if supported. For a longer but slightly out of date high-level description, see http://gee.cs.oswego.edu/dl/html/malloc.html You may already by default be using a C library containing a malloc that is based on some version of this malloc (for example in linux). You might still want to use the one in this file in order to customize settings or to avoid overheads associated with library versions. * Contents, described in more detail in "description of public routines" below. Standard (ANSI/SVID/...) functions: malloc(size_t n); calloc(size_t n_elements, size_t element_size); free(Void_t* p); realloc(Void_t* p, size_t n); memalign(size_t alignment, size_t n); valloc(size_t n); mallinfo() mallopt(int parameter_number, int parameter_value) Additional functions: independent_calloc(size_t n_elements, size_t size, Void_t* chunks[]); independent_comalloc(size_t n_elements, size_t sizes[], Void_t* chunks[]); pvalloc(size_t n); cfree(Void_t* p); malloc_trim(size_t pad); malloc_usable_size(Void_t* p); malloc_stats(); * Vital statistics: Supported pointer representation: 4 or 8 bytes Supported size_t representation: 4 or 8 bytes Note that size_t is allowed to be 4 bytes even if pointers are 8. You can adjust this by defining INTERNAL_SIZE_T Alignment: 2 * sizeof(size_t) (default) (i.e., 8 byte alignment with 4byte size_t). This suffices for nearly all current machines and C compilers. However, you can define MALLOC_ALIGNMENT to be wider than this if necessary. Minimum overhead per allocated chunk: 4 or 8 bytes Each malloced chunk has a hidden word of overhead holding size and status information. Minimum allocated size: 4-byte ptrs: 16 bytes (including 4 overhead) 8-byte ptrs: 24/32 bytes (including, 4/8 overhead) When a chunk is freed, 12 (for 4byte ptrs) or 20 (for 8 byte ptrs but 4 byte size) or 24 (for 8/8) additional bytes are needed; 4 (8) for a trailing size field and 8 (16) bytes for free list pointers. Thus, the minimum allocatable size is 16/24/32 bytes. Even a request for zero bytes (i.e., malloc(0)) returns a pointer to something of the minimum allocatable size. The maximum overhead wastage (i.e., number of extra bytes allocated than were requested in malloc) is less than or equal to the minimum size, except for requests >= mmap_threshold that are serviced via mmap(), where the worst case wastage is 2 * sizeof(size_t) bytes plus the remainder from a system page (the minimal mmap unit); typically 4096 or 8192 bytes. Maximum allocated size: 4-byte size_t: 2^32 minus about two pages 8-byte size_t: 2^64 minus about two pages It is assumed that (possibly signed) size_t values suffice to represent chunk sizes. `Possibly signed‘ is due to the fact that `size_t‘ may be defined on a system as either a signed or an unsigned type. The ISO C standard says that it must be unsigned, but a few systems are known not to adhere to this. Additionally, even when size_t is unsigned, sbrk (which is by default used to obtain memory from system) accepts signed arguments, and may not be able to handle size_t-wide arguments with negative sign bit. Generally, values that would appear as negative after accounting for overhead and alignment are supported only via mmap(), which does not have this limitation. Requests for sizes outside the allowed range will perform an optional failure action and then return null. (Requests may also also fail because a system is out of memory.) Thread-safety: thread-safe unless NO_THREADS is defined Compliance: I believe it is compliant with the 1997 Single Unix Specification (See http://www.opennc.org). Also SVID/XPG, ANSI C, and probably others as well. * Synopsis of compile-time options: People have reported using previous versions of this malloc on all versions of Unix, sometimes by tweaking some of the defines below. It has been tested most extensively on Solaris and Linux. It is also reported to work on WIN32 platforms. People also report using it in stand-alone embedded systems. The implementation is in straight, hand-tuned ANSI C. It is not at all modular. (Sorry!) It uses a lot of macros. To be at all usable, this code should be compiled using an optimizing compiler (for example gcc -O3) that can simplify expressions and control paths. (FAQ: some macros import variables as arguments rather than declare locals because people reported that some debuggers otherwise get confused.) OPTION DEFAULT VALUE Compilation Environment options: __STD_C derived from C compiler defines WIN32 NOT defined HAVE_MEMCPY defined USE_MEMCPY 1 if HAVE_MEMCPY is defined HAVE_MMAP defined as 1 MMAP_CLEARS 1 HAVE_MREMAP 0 unless linux defined USE_ARENAS the same as HAVE_MMAP malloc_getpagesize derived from system #includes, or 4096 if not HAVE_USR_INCLUDE_MALLOC_H NOT defined LACKS_UNISTD_H NOT defined unless WIN32 LACKS_SYS_PARAM_H NOT defined unless WIN32 LACKS_SYS_MMAN_H NOT defined unless WIN32 Changing default word sizes: INTERNAL_SIZE_T size_t MALLOC_ALIGNMENT MAX (2 * sizeof(INTERNAL_SIZE_T), __alignof__ (long double)) Configuration and functionality options: USE_DL_PREFIX NOT defined USE_PUBLIC_MALLOC_WRAPPERS NOT defined USE_MALLOC_LOCK NOT defined MALLOC_DEBUG NOT defined REALLOC_ZERO_BYTES_FREES 1 MALLOC_FAILURE_ACTION errno = ENOMEM, if __STD_C defined, else no-op TRIM_FASTBINS 0 Options for customizing MORECORE: MORECORE sbrk MORECORE_FAILURE -1 MORECORE_CONTIGUOUS 1 MORECORE_CANNOT_TRIM NOT defined MORECORE_CLEARS 1 MMAP_AS_MORECORE_SIZE (1024 * 1024) Tuning options that are also dynamically changeable via mallopt: DEFAULT_MXFAST 64 (for 32bit), 128 (for 64bit) DEFAULT_TRIM_THRESHOLD 128 * 1024 DEFAULT_TOP_PAD 0 DEFAULT_MMAP_THRESHOLD 128 * 1024 DEFAULT_MMAP_MAX 65536 There are several other #defined constants and macros that you probably don‘t want to touch unless you are extending or adapting malloc. */ /* __STD_C should be nonzero if using ANSI-standard C compiler, a C++ compiler, or a C compiler sufficiently close to ANSI to get away with it. */ #ifndef __STD_C #if defined(__STDC__) || defined(__cplusplus) #define __STD_C 1 #else #define __STD_C 0 #endif #endif /*__STD_C*/ /* Void_t* is the pointer type that malloc should say it returns */ #ifndef Void_t #if (__STD_C || defined(WIN32)) #define Void_t void #else #define Void_t char #endif #endif /*Void_t*/ #if __STD_C #include <stddef.h> /* for size_t */ #include <stdlib.h> /* for getenv(), abort() */ #else #include <sys/types.h> #endif #include <malloc-machine.h> #ifdef _LIBC #ifdef ATOMIC_FASTBINS #include <atomic.h> #endif #include <stdio-common/_itoa.h> #include <bits/wordsize.h> #include <sys/sysinfo.h> #endif #ifdef __cplusplus extern "C" { #endif /* define LACKS_UNISTD_H if your system does not have a <unistd.h>. */ /* #define LACKS_UNISTD_H */ #ifndef LACKS_UNISTD_H #include <unistd.h> #endif /* define LACKS_SYS_PARAM_H if your system does not have a <sys/param.h>. */ /* #define LACKS_SYS_PARAM_H */ #include <stdio.h> /* needed for malloc_stats */ #include <errno.h> /* needed for optional MALLOC_FAILURE_ACTION */ /* For uintptr_t. */ #include <stdint.h> /* For va_arg, va_start, va_end. */ #include <stdarg.h> /* For writev and struct iovec. */ #include <sys/uio.h> /* For syslog. */ #include <sys/syslog.h> /* For various dynamic linking things. */ #include <dlfcn.h> /* Debugging: Because freed chunks may be overwritten with bookkeeping fields, this malloc will often die when freed memory is overwritten by user programs. This can be very effective (albeit in an annoying way) in helping track down dangling pointers. If you compile with -DMALLOC_DEBUG, a number of assertion checks are enabled that will catch more memory errors. You probably won‘t be able to make much sense of the actual assertion errors, but they should help you locate incorrectly overwritten memory. The checking is fairly extensive, and will slow down execution noticeably. Calling malloc_stats or mallinfo with MALLOC_DEBUG set will attempt to check every non-mmapped allocated and free chunk in the course of computing the summmaries. (By nature, mmapped regions cannot be checked very much automatically.) Setting MALLOC_DEBUG may also be helpful if you are trying to modify this code. The assertions in the check routines spell out in more detail the assumptions and invariants underlying the algorithms. Setting MALLOC_DEBUG does NOT provide an automated mechanism for checking that all accesses to malloced memory stay within their bounds. However, there are several add-ons and adaptations of this or other mallocs available that do this. */ #ifdef NDEBUG # define assert(expr) ((void) 0) #else # define assert(expr) ((expr) ? ((void) 0) : __malloc_assert (__STRING (expr), __FILE__, __LINE__, __func__)) extern const char *__progname; static void __malloc_assert (const char *assertion, const char *file, unsigned int line, const char *function) { (void) __fxprintf (NULL, "%s%s%s:%u: %s%sAssertion `%s‘ failed.\n", __progname, __progname[0] ? ": " : "", file, line, function ? function : "", function ? ": " : "", assertion); fflush (stderr); abort (); } #endif /* INTERNAL_SIZE_T is the word-size used for internal bookkeeping of chunk sizes. The default version is the same as size_t. While not strictly necessary, it is best to define this as an unsigned type, even if size_t is a signed type. This may avoid some artificial size limitations on some systems. On a 64-bit machine, you may be able to reduce malloc overhead by defining INTERNAL_SIZE_T to be a 32 bit `unsigned int‘ at the expense of not being able to handle more than 2^32 of malloced space. If this limitation is acceptable, you are encouraged to set this unless you are on a platform requiring 16byte alignments. In this case the alignment requirements turn out to negate any potential advantages of decreasing size_t word size. Implementors: Beware of the possible combinations of: - INTERNAL_SIZE_T might be signed or unsigned, might be 32 or 64 bits, and might be the same width as int or as long - size_t might have different width and signedness as INTERNAL_SIZE_T - int and long might be 32 or 64 bits, and might be the same width To deal with this, most comparisons and difference computations among INTERNAL_SIZE_Ts should cast them to unsigned long, being aware of the fact that casting an unsigned int to a wider long does not sign-extend. (This also makes checking for negative numbers awkward.) Some of these casts result in harmless compiler warnings on some systems. */ #ifndef INTERNAL_SIZE_T #define INTERNAL_SIZE_T size_t #endif /* The corresponding word size */ #define SIZE_SZ (sizeof(INTERNAL_SIZE_T)) /* MALLOC_ALIGNMENT is the minimum alignment for malloc‘ed chunks. It must be a power of two at least 2 * SIZE_SZ, even on machines for which smaller alignments would suffice. It may be defined as larger than this though. Note however that code and data structures are optimized for the case of 8-byte alignment. */ #ifndef MALLOC_ALIGNMENT /* XXX This is the correct definition. It differs from 2*SIZE_SZ only on powerpc32. For the time being, changing this is causing more compatibility problems due to malloc_get_state/malloc_set_state than will returning blocks not adequately aligned for long double objects under -mlong-double-128. #define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) ? __alignof__ (long double) : 2 * SIZE_SZ) */ #define MALLOC_ALIGNMENT (2 * SIZE_SZ) #endif /* The corresponding bit mask value */ #define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1) /* REALLOC_ZERO_BYTES_FREES should be set if a call to realloc with zero bytes should be the same as a call to free. This is required by the C standard. Otherwise, since this malloc returns a unique pointer for malloc(0), so does realloc(p, 0). */ #ifndef REALLOC_ZERO_BYTES_FREES #define REALLOC_ZERO_BYTES_FREES 1 #endif /* TRIM_FASTBINS controls whether free() of a very small chunk can immediately lead to trimming. Setting to true (1) can reduce memory footprint, but will almost always slow down programs that use a lot of small chunks. Define this only if you are willing to give up some speed to more aggressively reduce system-level memory footprint when releasing memory in programs that use many small chunks. You can get essentially the same effect by setting MXFAST to 0, but this can lead to even greater slowdowns in programs using many small chunks. TRIM_FASTBINS is an in-between compile-time option, that disables only those chunks bordering topmost memory from being placed in fastbins. */ #ifndef TRIM_FASTBINS #define TRIM_FASTBINS 0 #endif /* USE_DL_PREFIX will prefix all public routines with the string ‘dl‘. This is necessary when you only want to use this malloc in one part of a program, using your regular system malloc elsewhere. */ /* #define USE_DL_PREFIX */ /* Two-phase name translation. All of the actual routines are given mangled names. When wrappers are used, they become the public callable versions. When DL_PREFIX is used, the callable names are prefixed. */ #ifdef USE_DL_PREFIX #define public_cALLOc dlcalloc #define public_fREe dlfree #define public_cFREe dlcfree #define public_mALLOc dlmalloc #define public_mEMALIGn dlmemalign #define public_rEALLOc dlrealloc #define public_vALLOc dlvalloc #define public_pVALLOc dlpvalloc #define public_mALLINFo dlmallinfo #define public_mALLOPt dlmallopt #define public_mTRIm dlmalloc_trim #define public_mSTATs dlmalloc_stats #define public_mUSABLe dlmalloc_usable_size #define public_iCALLOc dlindependent_calloc #define public_iCOMALLOc dlindependent_comalloc #define public_gET_STATe dlget_state #define public_sET_STATe dlset_state #else /* USE_DL_PREFIX */ #ifdef _LIBC /* Special defines for the GNU C library. */ #define public_cALLOc __libc_calloc #define public_fREe __libc_free #define public_cFREe __libc_cfree #define public_mALLOc __libc_malloc #define public_mEMALIGn __libc_memalign #define public_rEALLOc __libc_realloc #define public_vALLOc __libc_valloc #define public_pVALLOc __libc_pvalloc #define public_mALLINFo __libc_mallinfo #define public_mALLOPt __libc_mallopt #define public_mTRIm __malloc_trim #define public_mSTATs __malloc_stats #define public_mUSABLe __malloc_usable_size #define public_iCALLOc __libc_independent_calloc #define public_iCOMALLOc __libc_independent_comalloc #define public_gET_STATe __malloc_get_state #define public_sET_STATe __malloc_set_state #define malloc_getpagesize __getpagesize() #define open __open #define mmap __mmap #define munmap __munmap #define mremap __mremap #define mprotect __mprotect #define MORECORE (*__morecore) #define MORECORE_FAILURE 0 Void_t * __default_morecore (ptrdiff_t); Void_t *(*__morecore)(ptrdiff_t) = __default_morecore; #else /* !_LIBC */ #define public_cALLOc calloc #define public_fREe free #define public_cFREe cfree #define public_mALLOc malloc #define public_mEMALIGn memalign #define public_rEALLOc realloc #define public_vALLOc valloc #define public_pVALLOc pvalloc #define public_mALLINFo mallinfo #define public_mALLOPt mallopt #define public_mTRIm malloc_trim #define public_mSTATs malloc_stats #define public_mUSABLe malloc_usable_size #define public_iCALLOc independent_calloc #define public_iCOMALLOc independent_comalloc #define public_gET_STATe malloc_get_state #define public_sET_STATe malloc_set_state #endif /* _LIBC */ #endif /* USE_DL_PREFIX */ #ifndef _LIBC #define __builtin_expect(expr, val) (expr) #define fwrite(buf, size, count, fp) _IO_fwrite (buf, size, count, fp) #endif /* HAVE_MEMCPY should be defined if you are not otherwise using ANSI STD C, but still have memcpy and memset in your C library and want to use them in calloc and realloc. Otherwise simple macro versions are defined below. USE_MEMCPY should be defined as 1 if you actually want to have memset and memcpy called. People report that the macro versions are faster than libc versions on some systems. Even if USE_MEMCPY is set to 1, loops to copy/clear small chunks (of <= 36 bytes) are manually unrolled in realloc and calloc. */ #define HAVE_MEMCPY #ifndef USE_MEMCPY #ifdef HAVE_MEMCPY #define USE_MEMCPY 1 #else #define USE_MEMCPY 0 #endif #endif #if (__STD_C || defined(HAVE_MEMCPY)) #ifdef _LIBC # include <string.h> #else #ifdef WIN32 /* On Win32 memset and memcpy are already declared in windows.h */ #else #if __STD_C void* memset(void*, int, size_t); void* memcpy(void*, const void*, size_t); #else Void_t* memset(); Void_t* memcpy(); #endif #endif #endif #endif /* Force a value to be in a register and stop the compiler referring to the source (mostly memory location) again. */ #define force_reg(val) \ ({ __typeof (val) _v; asm ("" : "=r" (_v) : "0" (val)); _v; }) /* MALLOC_FAILURE_ACTION is the action to take before "return 0" when malloc fails to be able to return memory, either because memory is exhausted or because of illegal arguments. By default, sets errno if running on STD_C platform, else does nothing. */ #ifndef MALLOC_FAILURE_ACTION #if __STD_C #define MALLOC_FAILURE_ACTION \ errno = ENOMEM; #else #define MALLOC_FAILURE_ACTION #endif #endif /* MORECORE-related declarations. By default, rely on sbrk */ #ifdef LACKS_UNISTD_H #if !defined(__FreeBSD__) && !defined(__OpenBSD__) && !defined(__NetBSD__) #if __STD_C extern Void_t* sbrk(ptrdiff_t); #else extern Void_t* sbrk(); #endif #endif #endif /* MORECORE is the name of the routine to call to obtain more memory from the system. See below for general guidance on writing alternative MORECORE functions, as well as a version for WIN32 and a sample version for pre-OSX macos. */ #ifndef MORECORE #define MORECORE sbrk #endif /* MORECORE_FAILURE is the value returned upon failure of MORECORE as well as mmap. Since it cannot be an otherwise valid memory address, and must reflect values of standard sys calls, you probably ought not try to redefine it. */ #ifndef MORECORE_FAILURE #define MORECORE_FAILURE (-1) #endif /* If MORECORE_CONTIGUOUS is true, take advantage of fact that consecutive calls to MORECORE with positive arguments always return contiguous increasing addresses. This is true of unix sbrk. Even if not defined, when regions happen to be contiguous, malloc will permit allocations spanning regions obtained from different calls. But defining this when applicable enables some stronger consistency checks and space efficiencies. */ #ifndef MORECORE_CONTIGUOUS #define MORECORE_CONTIGUOUS 1 #endif /* Define MORECORE_CANNOT_TRIM if your version of MORECORE cannot release space back to the system when given negative arguments. This is generally necessary only if you are using a hand-crafted MORECORE function that cannot handle negative arguments. */ /* #define MORECORE_CANNOT_TRIM */ /* MORECORE_CLEARS (default 1) The degree to which the routine mapped to MORECORE zeroes out memory: never (0), only for newly allocated space (1) or always (2). The distinction between (1) and (2) is necessary because on some systems, if the application first decrements and then increments the break value, the contents of the reallocated space are unspecified. */ #ifndef MORECORE_CLEARS #define MORECORE_CLEARS 1 #endif /* Define HAVE_MMAP as true to optionally make malloc() use mmap() to allocate very large blocks. These will be returned to the operating system immediately after a free(). Also, if mmap is available, it is used as a backup strategy in cases where MORECORE fails to provide space from system. This malloc is best tuned to work with mmap for large requests. If you do not have mmap, operations involving very large chunks (1MB or so) may be slower than you‘d like. */ #ifndef HAVE_MMAP #define HAVE_MMAP 1 /* Standard unix mmap using /dev/zero clears memory so calloc doesn‘t need to. */ #ifndef MMAP_CLEARS #define MMAP_CLEARS 1 #endif #else /* no mmap */ #ifndef MMAP_CLEARS #define MMAP_CLEARS 0 #endif #endif /* MMAP_AS_MORECORE_SIZE is the minimum mmap size argument to use if sbrk fails, and mmap is used as a backup (which is done only if HAVE_MMAP). The value must be a multiple of page size. This backup strategy generally applies only when systems have "holes" in address space, so sbrk cannot perform contiguous expansion, but there is still space available on system. On systems for which this is known to be useful (i.e. most linux kernels), this occurs only when programs allocate huge amounts of memory. Between this, and the fact that mmap regions tend to be limited, the size should be large, to avoid too many mmap calls and thus avoid running out of kernel resources. */ #ifndef MMAP_AS_MORECORE_SIZE #define MMAP_AS_MORECORE_SIZE (1024 * 1024) #endif /* Define HAVE_MREMAP to make realloc() use mremap() to re-allocate large blocks. This is currently only possible on Linux with kernel versions newer than 1.3.77. */ #ifndef HAVE_MREMAP #ifdef linux #define HAVE_MREMAP 1 #else #define HAVE_MREMAP 0 #endif #endif /* HAVE_MMAP */ /* Define USE_ARENAS to enable support for multiple `arenas‘. These are allocated using mmap(), are necessary for threads and occasionally useful to overcome address space limitations affecting sbrk(). */ #ifndef USE_ARENAS #define USE_ARENAS HAVE_MMAP #endif /* The system page size. To the extent possible, this malloc manages memory from the system in page-size units. Note that this value is cached during initialization into a field of malloc_state. So even if malloc_getpagesize is a function, it is only called once. The following mechanics for getpagesize were adapted from bsd/gnu getpagesize.h. If none of the system-probes here apply, a value of 4096 is used, which should be OK: If they don‘t apply, then using the actual value probably doesn‘t impact performance. */ #ifndef malloc_getpagesize #ifndef LACKS_UNISTD_H # include <unistd.h> #endif # ifdef _SC_PAGESIZE /* some SVR4 systems omit an underscore */ # ifndef _SC_PAGE_SIZE # define _SC_PAGE_SIZE _SC_PAGESIZE # endif # endif # ifdef _SC_PAGE_SIZE # define malloc_getpagesize sysconf(_SC_PAGE_SIZE) # else # if defined(BSD) || defined(DGUX) || defined(HAVE_GETPAGESIZE) extern size_t getpagesize(); # define malloc_getpagesize getpagesize() # else # ifdef WIN32 /* use supplied emulation of getpagesize */ # define malloc_getpagesize getpagesize() # else # ifndef LACKS_SYS_PARAM_H # include <sys/param.h> # endif # ifdef EXEC_PAGESIZE # define malloc_getpagesize EXEC_PAGESIZE # else # ifdef NBPG # ifndef CLSIZE # define malloc_getpagesize NBPG # else # define malloc_getpagesize (NBPG * CLSIZE) # endif # else # ifdef NBPC # define malloc_getpagesize NBPC # else # ifdef PAGESIZE # define malloc_getpagesize PAGESIZE # else /* just guess */ # define malloc_getpagesize (4096) # endif # endif # endif # endif # endif # endif # endif #endif /* This version of malloc supports the standard SVID/XPG mallinfo routine that returns a struct containing usage properties and statistics. It should work on any SVID/XPG compliant system that has a /usr/include/malloc.h defining struct mallinfo. (If you‘d like to install such a thing yourself, cut out the preliminary declarations as described above and below and save them in a malloc.h file. But there‘s no compelling reason to bother to do this.) The main declaration needed is the mallinfo struct that is returned (by-copy) by mallinfo(). The SVID/XPG malloinfo struct contains a bunch of fields that are not even meaningful in this version of malloc. These fields are are instead filled by mallinfo() with other numbers that might be of interest. HAVE_USR_INCLUDE_MALLOC_H should be set if you have a /usr/include/malloc.h file that includes a declaration of struct mallinfo. If so, it is included; else an SVID2/XPG2 compliant version is declared below. These must be precisely the same for mallinfo() to work. The original SVID version of this struct, defined on most systems with mallinfo, declares all fields as ints. But some others define as unsigned long. If your system defines the fields using a type of different width than listed here, you must #include your system version and #define HAVE_USR_INCLUDE_MALLOC_H. */ /* #define HAVE_USR_INCLUDE_MALLOC_H */ #ifdef HAVE_USR_INCLUDE_MALLOC_H #include "/usr/include/malloc.h" #endif /* ---------- description of public routines ------------ */ /* malloc(size_t n) Returns a pointer to a newly allocated chunk of at least n bytes, or null if no space is available. Additionally, on failure, errno is set to ENOMEM on ANSI C systems. If n is zero, malloc returns a minumum-sized chunk. (The minimum size is 16 bytes on most 32bit systems, and 24 or 32 bytes on 64bit systems.) On most systems, size_t is an unsigned type, so calls with negative arguments are interpreted as requests for huge amounts of space, which will often fail. The maximum supported value of n differs across systems, but is in all cases less than the maximum representable value of a size_t. */ #if __STD_C Void_t* public_mALLOc(size_t); #else Void_t* public_mALLOc(); #endif #ifdef libc_hidden_proto libc_hidden_proto (public_mALLOc) #endif /* free(Void_t* p) Releases the chunk of memory pointed to by p, that had been previously allocated using malloc or a related routine such as realloc. It has no effect if p is null. It can have arbitrary (i.e., bad!) effects if p has already been freed. Unless disabled (using mallopt), freeing very large spaces will when possible, automatically trigger operations that give back unused memory to the system, thus reducing program footprint. */ #if __STD_C void public_fREe(Void_t*); #else void public_fREe(); #endif #ifdef libc_hidden_proto libc_hidden_proto (public_fREe) #endif /* calloc(size_t n_elements, size_t element_size); Returns a pointer to n_elements * element_size bytes, with all locations set to zero. */ #if __STD_C Void_t* public_cALLOc(size_t, size_t); #else Void_t* public_cALLOc(); #endif /* realloc(Void_t* p, size_t n) Returns a pointer to a chunk of size n that contains the same data as does chunk p up to the minimum of (n, p‘s size) bytes, or null if no space is available. The returned pointer may or may not be the same as p. The algorithm prefers extending p when possible, otherwise it employs the equivalent of a malloc-copy-free sequence. If p is null, realloc is equivalent to malloc. If space is not available, realloc returns null, errno is set (if on ANSI) and p is NOT freed. if n is for fewer bytes than already held by p, the newly unused space is lopped off and freed if possible. Unless the #define REALLOC_ZERO_BYTES_FREES is set, realloc with a size argument of zero (re)allocates a minimum-sized chunk. Large chunks that were internally obtained via mmap will always be reallocated using malloc-copy-free sequences unless the system supports MREMAP (currently only linux). The old unix realloc convention of allowing the last-free‘d chunk to be used as an argument to realloc is not supported. */ #if __STD_C Void_t* public_rEALLOc(Void_t*, size_t); #else Void_t* public_rEALLOc(); #endif #ifdef libc_hidden_proto libc_hidden_proto (public_rEALLOc) #endif /* memalign(size_t alignment, size_t n); Returns a pointer to a newly allocated chunk of n bytes, aligned in accord with the alignment argument. The alignment argument should be a power of two. If the argument is not a power of two, the nearest greater power is used. 8-byte alignment is guaranteed by normal malloc calls, so don‘t bother calling memalign with an argument of 8 or less. Overreliance on memalign is a sure way to fragment space. */ #if __STD_C Void_t* public_mEMALIGn(size_t, size_t); #else Void_t* public_mEMALIGn(); #endif #ifdef libc_hidden_proto libc_hidden_proto (public_mEMALIGn) #endif /* valloc(size_t n); Equivalent to memalign(pagesize, n), where pagesize is the page size of the system. If the pagesize is unknown, 4096 is used. */ #if __STD_C Void_t* public_vALLOc(size_t); #else Void_t* public_vALLOc(); #endif /* mallopt(int parameter_number, int parameter_value) Sets tunable parameters The format is to provide a (parameter-number, parameter-value) pair. mallopt then sets the corresponding parameter to the argument value if it can (i.e., so long as the value is meaningful), and returns 1 if successful else 0. SVID/XPG/ANSI defines four standard param numbers for mallopt, normally defined in malloc.h. Only one of these (M_MXFAST) is used in this malloc. The others (M_NLBLKS, M_GRAIN, M_KEEP) don‘t apply, so setting them has no effect. But this malloc also supports four other options in mallopt. See below for details. Briefly, supported parameters are as follows (listed defaults are for "typical" configurations). Symbol param # default allowed param values M_MXFAST 1 64 0-80 (0 disables fastbins) M_TRIM_THRESHOLD -1 128*1024 any (-1U disables trimming) M_TOP_PAD -2 0 any M_MMAP_THRESHOLD -3 128*1024 any (or 0 if no MMAP support) M_MMAP_MAX -4 65536 any (0 disables use of mmap) */ #if __STD_C int public_mALLOPt(int, int); #else int public_mALLOPt(); #endif /* mallinfo() Returns (by copy) a struct containing various summary statistics: arena: current total non-mmapped bytes allocated from system ordblks: the number of free chunks smblks: the number of fastbin blocks (i.e., small chunks that have been freed but not use resused or consolidated) hblks: current number of mmapped regions hblkhd: total bytes held in mmapped regions usmblks: the maximum total allocated space. This will be greater than current total if trimming has occurred. fsmblks: total bytes held in fastbin blocks uordblks: current total allocated space (normal or mmapped) fordblks: total free space keepcost: the maximum number of bytes that could ideally be released back to system via malloc_trim. ("ideally" means that it ignores page restrictions etc.) Because these fields are ints, but internal bookkeeping may be kept as longs, the reported values may wrap around zero and thus be inaccurate. */ #if __STD_C struct mallinfo public_mALLINFo(void); #else struct mallinfo public_mALLINFo(); #endif #ifndef _LIBC /* independent_calloc(size_t n_elements, size_t element_size, Void_t* chunks[]); independent_calloc is similar to calloc, but instead of returning a single cleared space, it returns an array of pointers to n_elements independent elements that can hold contents of size elem_size, each of which starts out cleared, and can be independently freed, realloc‘ed etc. The elements are guaranteed to be adjacently allocated (this is not guaranteed to occur with multiple callocs or mallocs), which may also improve cache locality in some applications. The "chunks" argument is optional (i.e., may be null, which is probably the most typical usage). If it is null, the returned array is itself dynamically allocated and should also be freed when it is no longer needed. Otherwise, the chunks array must be of at least n_elements in length. It is filled in with the pointers to the chunks. In either case, independent_calloc returns this pointer array, or null if the allocation failed. If n_elements is zero and "chunks" is null, it returns a chunk representing an array with zero elements (which should be freed if not wanted). Each element must be individually freed when it is no longer needed. If you‘d like to instead be able to free all at once, you should instead use regular calloc and assign pointers into this space to represent elements. (In this case though, you cannot independently free elements.) independent_calloc simplifies and speeds up implementations of many kinds of pools. It may also be useful when constructing large data structures that initially have a fixed number of fixed-sized nodes, but the number is not known at compile time, and some of the nodes may later need to be freed. For example: struct Node { int item; struct Node* next; }; struct Node* build_list() { struct Node** pool; int n = read_number_of_nodes_needed(); if (n <= 0) return 0; pool = (struct Node**)(independent_calloc(n, sizeof(struct Node), 0); if (pool == 0) die(); // organize into a linked list... struct Node* first = pool[0]; for (i = 0; i < n-1; ++i) pool[i]->next = pool[i+1]; free(pool); // Can now free the array (or not, if it is needed later) return first; } */ #if __STD_C Void_t** public_iCALLOc(size_t, size_t, Void_t**); #else Void_t** public_iCALLOc(); #endif /* independent_comalloc(size_t n_elements, size_t sizes[], Void_t* chunks[]); independent_comalloc allocates, all at once, a set of n_elements chunks with sizes indicated in the "sizes" array. It returns an array of pointers to these elements, each of which can be independently freed, realloc‘ed etc. The elements are guaranteed to be adjacently allocated (this is not guaranteed to occur with multiple callocs or mallocs), which may also improve cache locality in some applications. The "chunks" argument is optional (i.e., may be null). If it is null the returned array is itself dynamically allocated and should also be freed when it is no longer needed. Otherwise, the chunks array must be of at least n_elements in length. It is filled in with the pointers to the chunks. In either case, independent_comalloc returns this pointer array, or null if the allocation failed. If n_elements is zero and chunks is null, it returns a chunk representing an array with zero elements (which should be freed if not wanted). Each element must be individually freed when it is no longer needed. If you‘d like to instead be able to free all at once, you should instead use a single regular malloc, and assign pointers at particular offsets in the aggregate space. (In this case though, you cannot independently free elements.) independent_comallac differs from independent_calloc in that each element may have a different size, and also that it does not automatically clear elements. independent_comalloc can be used to speed up allocation in cases where several structs or objects must always be allocated at the same time. For example: struct Head { ... } struct Foot { ... } void send_message(char* msg) { int msglen = strlen(msg); size_t sizes[3] = { sizeof(struct Head), msglen, sizeof(struct Foot) }; void* chunks[3]; if (independent_comalloc(3, sizes, chunks) == 0) die(); struct Head* head = (struct Head*)(chunks[0]); char* body = (char*)(chunks[1]); struct Foot* foot = (struct Foot*)(chunks[2]); // ... } In general though, independent_comalloc is worth using only for larger values of n_elements. For small values, you probably won‘t detect enough difference from series of malloc calls to bother. Overuse of independent_comalloc can increase overall memory usage, since it cannot reuse existing noncontiguous small chunks that might be available for some of the elements. */ #if __STD_C Void_t** public_iCOMALLOc(size_t, size_t*, Void_t**); #else Void_t** public_iCOMALLOc(); #endif #endif /* _LIBC */ /* pvalloc(size_t n); Equivalent to valloc(minimum-page-that-holds(n)), that is, round up n to nearest pagesize. */ #if __STD_C Void_t* public_pVALLOc(size_t); #else Void_t* public_pVALLOc(); #endif /* cfree(Void_t* p); Equivalent to free(p). cfree is needed/defined on some systems that pair it with calloc, for odd historical reasons (such as: cfree is used in example code in the first edition of K&R). */ #if __STD_C void public_cFREe(Void_t*); #else void public_cFREe(); #endif /* malloc_trim(size_t pad); If possible, gives memory back to the system (via negative arguments to sbrk) if there is unused memory at the `high‘ end of the malloc pool. You can call this after freeing large blocks of memory to potentially reduce the system-level memory requirements of a program. However, it cannot guarantee to reduce memory. Under some allocation patterns, some large free blocks of memory will be locked between two used chunks, so they cannot be given back to the system. The `pad‘ argument to malloc_trim represents the amount of free trailing space to leave untrimmed. If this argument is zero, only the minimum amount of memory to maintain internal data structures will be left (one page or less). Non-zero arguments can be supplied to maintain enough trailing space to service future expected allocations without having to re-obtain memory from the system. Malloc_trim returns 1 if it actually released any memory, else 0. On systems that do not support "negative sbrks", it will always return 0. */ #if __STD_C int public_mTRIm(size_t); #else int public_mTRIm(); #endif /* malloc_usable_size(Void_t* p); Returns the number of bytes you can actually use in an allocated chunk, which may be more than you requested (although often not) due to alignment and minimum size constraints. You can use this many bytes without worrying about overwriting other allocated objects. This is not a particularly great programming practice. malloc_usable_size can be more useful in debugging and assertions, for example: p = malloc(n); assert(malloc_usable_size(p) >= 256); */ #if __STD_C size_t public_mUSABLe(Void_t*); #else size_t public_mUSABLe(); #endif /* malloc_stats(); Prints on stderr the amount of space obtained from the system (both via sbrk and mmap), the maximum amount (which may be more than current if malloc_trim and/or munmap got called), and the current number of bytes allocated via malloc (or realloc, etc) but not yet freed. Note that this is the number of bytes allocated, not the number requested. It will be larger than the number requested because of alignment and bookkeeping overhead. Because it includes alignment wastage as being in use, this figure may be greater than zero even when no user-level chunks are allocated. The reported current and maximum system memory can be inaccurate if a program makes other calls to system memory allocation functions (normally sbrk) outside of malloc. malloc_stats prints only the most commonly interesting statistics. More information can be obtained by calling mallinfo. */ #if __STD_C void public_mSTATs(void); #else void public_mSTATs(); #endif /* malloc_get_state(void); Returns the state of all malloc variables in an opaque data structure. */ #if __STD_C Void_t* public_gET_STATe(void); #else Void_t* public_gET_STATe(); #endif /* malloc_set_state(Void_t* state); Restore the state of all malloc variables from data obtained with malloc_get_state(). */ #if __STD_C int public_sET_STATe(Void_t*); #else int public_sET_STATe(); #endif #ifdef _LIBC /* posix_memalign(void **memptr, size_t alignment, size_t size); POSIX wrapper like memalign(), checking for validity of size. */ int __posix_memalign(void **, size_t, size_t); #endif /* mallopt tuning options */ /* M_MXFAST is the maximum request size used for "fastbins", special bins that hold returned chunks without consolidating their spaces. This enables future requests for chunks of the same size to be handled very quickly, but can increase fragmentation, and thus increase the overall memory footprint of a program. This malloc manages fastbins very conservatively yet still efficiently, so fragmentation is rarely a problem for values less than or equal to the default. The maximum supported value of MXFAST is 80. You wouldn‘t want it any higher than this anyway. Fastbins are designed especially for use with many small structs, objects or strings -- the default handles structs/objects/arrays with sizes up to 8 4byte fields, or small strings representing words, tokens, etc. Using fastbins for larger objects normally worsens fragmentation without improving speed. M_MXFAST is set in REQUEST size units. It is internally used in chunksize units, which adds padding and alignment. You can reduce M_MXFAST to 0 to disable all use of fastbins. This causes the malloc algorithm to be a closer approximation of fifo-best-fit in all cases, not just for larger requests, but will generally cause it to be slower. */ /* M_MXFAST is a standard SVID/XPG tuning option, usually listed in malloc.h */ #ifndef M_MXFAST #define M_MXFAST 1 #endif #ifndef DEFAULT_MXFAST #define DEFAULT_MXFAST (64 * SIZE_SZ / 4) #endif /* M_TRIM_THRESHOLD is the maximum amount of unused top-most memory to keep before releasing via malloc_trim in free(). Automatic trimming is mainly useful in long-lived programs. Because trimming via sbrk can be slow on some systems, and can sometimes be wasteful (in cases where programs immediately afterward allocate more large chunks) the value should be high enough so that your overall system performance would improve by releasing this much memory. The trim threshold and the mmap control parameters (see below) can be traded off with one another. Trimming and mmapping are two different ways of releasing unused memory back to the system. Between these two, it is often possible to keep system-level demands of a long-lived program down to a bare minimum. For example, in one test suite of sessions measuring the XF86 X server on Linux, using a trim threshold of 128K and a mmap threshold of 192K led to near-minimal long term resource consumption. If you are using this malloc in a long-lived program, it should pay to experiment with these values. As a rough guide, you might set to a value close to the average size of a process (program) running on your system. Releasing this much memory would allow such a process to run in memory. Generally, it‘s worth it to tune for trimming rather tham memory mapping when a program undergoes phases where several large chunks are allocated and released in ways that can reuse each other‘s storage, perhaps mixed with phases where there are no such chunks at all. And in well-behaved long-lived programs, controlling release of large blocks via trimming versus mapping is usually faster. However, in most programs, these parameters serve mainly as protection against the system-level effects of carrying around massive amounts of unneeded memory. Since frequent calls to sbrk, mmap, and munmap otherwise degrade performance, the default parameters are set to relatively high values that serve only as safeguards. The trim value It must be greater than page size to have any useful effect. To disable trimming completely, you can set to (unsigned long)(-1) Trim settings interact with fastbin (MXFAST) settings: Unless TRIM_FASTBINS is defined, automatic trimming never takes place upon freeing a chunk with size less than or equal to MXFAST. Trimming is instead delayed until subsequent freeing of larger chunks. However, you can still force an attempted trim by calling malloc_trim. Also, trimming is not generally possible in cases where the main arena is obtained via mmap. Note that the trick some people use of mallocing a huge space and then freeing it at program startup, in an attempt to reserve system memory, doesn‘t have the intended effect under automatic trimming, since that memory will immediately be returned to the system. */ #define M_TRIM_THRESHOLD -1 #ifndef DEFAULT_TRIM_THRESHOLD #define DEFAULT_TRIM_THRESHOLD (128 * 1024) #endif /* M_TOP_PAD is the amount of extra `padding‘ space to allocate or retain whenever sbrk is called. It is used in two ways internally: * When sbrk is called to extend the top of the arena to satisfy a new malloc request, this much padding is added to the sbrk request. * When malloc_trim is called automatically from free(), it is used as the `pad‘ argument. In both cases, the actual amount of padding is rounded so that the end of the arena is always a system page boundary. The main reason for using padding is to avoid calling sbrk so often. Having even a small pad greatly reduces the likelihood that nearly every malloc request during program start-up (or after trimming) will invoke sbrk, which needlessly wastes time. Automatic rounding-up to page-size units is normally sufficient to avoid measurable overhead, so the default is 0. However, in systems where sbrk is relatively slow, it can pay to increase this value, at the expense of carrying around more memory than the program needs. */ #define M_TOP_PAD -2 #ifndef DEFAULT_TOP_PAD #define DEFAULT_TOP_PAD (0) #endif /* MMAP_THRESHOLD_MAX and _MIN are the bounds on the dynamically adjusted MMAP_THRESHOLD. */ #ifndef DEFAULT_MMAP_THRESHOLD_MIN #define DEFAULT_MMAP_THRESHOLD_MIN (128 * 1024) #endif #ifndef DEFAULT_MMAP_THRESHOLD_MAX /* For 32-bit platforms we cannot increase the maximum mmap threshold much because it is also the minimum value for the maximum heap size and its alignment. Going above 512k (i.e., 1M for new heaps) wastes too much address space. */ # if __WORDSIZE == 32 # define DEFAULT_MMAP_THRESHOLD_MAX (512 * 1024) # else # define DEFAULT_MMAP_THRESHOLD_MAX (4 * 1024 * 1024 * sizeof(long)) # endif #endif /* M_MMAP_THRESHOLD is the request size threshold for using mmap() to service a request. Requests of at least this size that cannot be allocated using already-existing space will be serviced via mmap. (If enough normal freed space already exists it is used instead.) Using mmap segregates relatively large chunks of memory so that they can be individually obtained and released from the host system. A request serviced through mmap is never reused by any other request (at least not directly; the system may just so happen to remap successive requests to the same locations). Segregating space in this way has the benefits that: 1. Mmapped space can ALWAYS be individually released back to the system, which helps keep the system level memory demands of a long-lived program low. 2. Mapped memory can never become `locked‘ between other chunks, as can happen with normally allocated chunks, which means that even trimming via malloc_trim would not release them. 3. On some systems with "holes" in address spaces, mmap can obtain memory that sbrk cannot. However, it has the disadvantages that: 1. The space cannot be reclaimed, consolidated, and then used to service later requests, as happens with normal chunks. 2. It can lead to more wastage because of mmap page alignment requirements 3. It causes malloc performance to be more dependent on host system memory management support routines which may vary in implementation quality and may impose arbitrary limitations. Generally, servicing a request via normal malloc steps is faster than going through a system‘s mmap. The advantages of mmap nearly always outweigh disadvantages for "large" chunks, but the value of "large" varies across systems. The default is an empirically derived value that works well in most systems. Update in 2006: The above was written in 2001. Since then the world has changed a lot. Memory got bigger. Applications got bigger. The virtual address space layout in 32 bit linux changed. In the new situation, brk() and mmap space is shared and there are no artificial limits on brk size imposed by the kernel. What is more, applications have started using transient allocations larger than the 128Kb as was imagined in 2001. The price for mmap is also high now; each time glibc mmaps from the kernel, the kernel is forced to zero out the memory it gives to the application. Zeroing memory is expensive and eats a lot of cache and memory bandwidth. This has nothing to do with the efficiency of the virtual memory system, by doing mmap the kernel just has no choice but to zero. In 2001, the kernel had a maximum size for brk() which was about 800 megabytes on 32 bit x86, at that point brk() would hit the first mmaped shared libaries and couldn‘t expand anymore. With current 2.6 kernels, the VA space layout is different and brk() and mmap both can span the entire heap at will. Rather than using a static threshold for the brk/mmap tradeoff, we are now using a simple dynamic one. The goal is still to avoid fragmentation. The old goals we kept are 1) try to get the long lived large allocations to use mmap() 2) really large allocations should always use mmap() and we‘re adding now: 3) transient allocations should use brk() to avoid forcing the kernel having to zero memory over and over again The implementation works with a sliding threshold, which is by default limited to go between 128Kb and 32Mb (64Mb for 64 bitmachines) and starts out at 128Kb as per the 2001 default. This allows us to satisfy requirement 1) under the assumption that long lived allocations are made early in the process‘ lifespan, before it has started doing dynamic allocations of the same size (which will increase the threshold). The upperbound on the threshold satisfies requirement 2) The threshold goes up in value when the application frees memory that was allocated with the mmap allocator. The idea is that once the application starts freeing memory of a certain size, it‘s highly probable that this is a size the application uses for transient allocations. This estimator is there to satisfy the new third requirement. */ #define M_MMAP_THRESHOLD -3 #ifndef DEFAULT_MMAP_THRESHOLD #define DEFAULT_MMAP_THRESHOLD DEFAULT_MMAP_THRESHOLD_MIN #endif /* M_MMAP_MAX is the maximum number of requests to simultaneously service using mmap. This parameter exists because some systems have a limited number of internal tables for use by mmap, and using more than a few of them may degrade performance. The default is set to a value that serves only as a safeguard. Setting to 0 disables use of mmap for servicing large requests. If HAVE_MMAP is not set, the default value is 0, and attempts to set it to non-zero values in mallopt will fail. */ #define M_MMAP_MAX -4 #ifndef DEFAULT_MMAP_MAX #if HAVE_MMAP #define DEFAULT_MMAP_MAX (65536) #else #define DEFAULT_MMAP_MAX (0) #endif #endif #ifdef __cplusplus } /* end of extern "C" */ #endif #include <malloc.h> #ifndef BOUNDED_N #define BOUNDED_N(ptr, sz) (ptr) #endif #ifndef RETURN_ADDRESS #define RETURN_ADDRESS(X_) (NULL) #endif /* On some platforms we can compile internal, not exported functions better. Let the environment provide a macro and define it to be empty if it is not available. */ #ifndef internal_function # define internal_function #endif /* Forward declarations. */ struct malloc_chunk; typedef struct malloc_chunk* mchunkptr; /* Internal routines. */ #if __STD_C static Void_t* _int_malloc(mstate, size_t); #ifdef ATOMIC_FASTBINS static void _int_free(mstate, mchunkptr, int); #else static void _int_free(mstate, mchunkptr); #endif static Void_t* _int_realloc(mstate, mchunkptr, INTERNAL_SIZE_T, INTERNAL_SIZE_T); static Void_t* _int_memalign(mstate, size_t, size_t); static Void_t* _int_valloc(mstate, size_t); static Void_t* _int_pvalloc(mstate, size_t); /*static Void_t* cALLOc(size_t, size_t);*/ #ifndef _LIBC static Void_t** _int_icalloc(mstate, size_t, size_t, Void_t**); static Void_t** _int_icomalloc(mstate, size_t, size_t*, Void_t**); #endif static int mTRIm(mstate, size_t); static size_t mUSABLe(Void_t*); static void mSTATs(void); static int mALLOPt(int, int); static struct mallinfo mALLINFo(mstate); static void malloc_printerr(int action, const char *str, void *ptr); static Void_t* internal_function mem2mem_check(Void_t *p, size_t sz); static int internal_function top_check(void); static void internal_function munmap_chunk(mchunkptr p); #if HAVE_MREMAP static mchunkptr internal_function mremap_chunk(mchunkptr p, size_t new_size); #endif static Void_t* malloc_check(size_t sz, const Void_t *caller); static void free_check(Void_t* mem, const Void_t *caller); static Void_t* realloc_check(Void_t* oldmem, size_t bytes, const Void_t *caller); static Void_t* memalign_check(size_t alignment, size_t bytes, const Void_t *caller); #ifndef NO_THREADS # ifdef _LIBC # if USE___THREAD || !defined SHARED /* These routines are never needed in this configuration. */ # define NO_STARTER # endif # endif # ifdef NO_STARTER # undef NO_STARTER # else static Void_t* malloc_starter(size_t sz, const Void_t *caller); static Void_t* memalign_starter(size_t aln, size_t sz, const Void_t *caller); static void free_starter(Void_t* mem, const Void_t *caller); # endif static Void_t* malloc_atfork(size_t sz, const Void_t *caller); static void free_atfork(Void_t* mem, const Void_t *caller); #endif #else static Void_t* _int_malloc(); static void _int_free(); static Void_t* _int_realloc(); static Void_t* _int_memalign(); static Void_t* _int_valloc(); static Void_t* _int_pvalloc(); /*static Void_t* cALLOc();*/ static Void_t** _int_icalloc(); static Void_t** _int_icomalloc(); static int mTRIm(); static size_t mUSABLe(); static void mSTATs(); static int mALLOPt(); static struct mallinfo mALLINFo(); #endif /* ------------- Optional versions of memcopy ---------------- */ #if USE_MEMCPY /* Note: memcpy is ONLY invoked with non-overlapping regions, so the (usually slower) memmove is not needed. */ #define MALLOC_COPY(dest, src, nbytes) memcpy(dest, src, nbytes) #define MALLOC_ZERO(dest, nbytes) memset(dest, 0, nbytes) #else /* !USE_MEMCPY */ /* Use Duff‘s device for good zeroing/copying performance. */ #define MALLOC_ZERO(charp, nbytes) do { INTERNAL_SIZE_T* mzp = (INTERNAL_SIZE_T*)(charp); unsigned long mctmp = (nbytes)/sizeof(INTERNAL_SIZE_T); long mcn; if (mctmp < 8) mcn = 0; else { mcn = (mctmp-1)/8; mctmp %= 8; } switch (mctmp) { case 0: for(;;) { *mzp++ = 0; case 7: *mzp++ = 0; case 6: *mzp++ = 0; case 5: *mzp++ = 0; case 4: *mzp++ = 0; case 3: *mzp++ = 0; case 2: *mzp++ = 0; case 1: *mzp++ = 0; if(mcn <= 0) break; mcn--; } } } while(0) #define MALLOC_COPY(dest,src,nbytes) do { INTERNAL_SIZE_T* mcsrc = (INTERNAL_SIZE_T*) src; INTERNAL_SIZE_T* mcdst = (INTERNAL_SIZE_T*) dest; unsigned long mctmp = (nbytes)/sizeof(INTERNAL_SIZE_T); long mcn; if (mctmp < 8) mcn = 0; else { mcn = (mctmp-1)/8; mctmp %= 8; } switch (mctmp) { case 0: for(;;) { *mcdst++ = *mcsrc++; case 7: *mcdst++ = *mcsrc++; case 6: *mcdst++ = *mcsrc++; case 5: *mcdst++ = *mcsrc++; case 4: *mcdst++ = *mcsrc++; case 3: *mcdst++ = *mcsrc++; case 2: *mcdst++ = *mcsrc++; case 1: *mcdst++ = *mcsrc++; if(mcn <= 0) break; mcn--; } } } while(0) #endif /* ------------------ MMAP support ------------------ */ #if HAVE_MMAP #include <fcntl.h> #ifndef LACKS_SYS_MMAN_H #include <sys/mman.h> #endif #if !defined(MAP_ANONYMOUS) && defined(MAP_ANON) # define MAP_ANONYMOUS MAP_ANON #endif #if !defined(MAP_FAILED) # define MAP_FAILED ((char*)-1) #endif #ifndef MAP_NORESERVE # ifdef MAP_AUTORESRV # define MAP_NORESERVE MAP_AUTORESRV # else # define MAP_NORESERVE 0 # endif #endif /* Nearly all versions of mmap support MAP_ANONYMOUS, so the following is unlikely to be needed, but is supplied just in case. */ #ifndef MAP_ANONYMOUS static int dev_zero_fd = -1; /* Cached file descriptor for /dev/zero. */ #define MMAP(addr, size, prot, flags) ((dev_zero_fd < 0) ? \ (dev_zero_fd = open("/dev/zero", O_RDWR), mmap((addr), (size), (prot), (flags), dev_zero_fd, 0)) : mmap((addr), (size), (prot), (flags), dev_zero_fd, 0)) #else #define MMAP(addr, size, prot, flags) \ (mmap((addr), (size), (prot), (flags)|MAP_ANONYMOUS, -1, 0)) #endif #endif /* HAVE_MMAP */ /* ----------------------- Chunk representations ----------------------- */ /* This struct declaration is misleading (but accurate and necessary). It declares a "view" into memory allowing access to necessary fields at known offsets from a given base. See explanation below. */ struct malloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ struct malloc_chunk* fd; /* double links -- used only if free. */ struct malloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ struct malloc_chunk* bk_nextsize; }; /* malloc_chunk details: (The following includes lightly edited explanations by Colin Plumb.) Chunks of memory are maintained using a `boundary tag‘ method as described in e.g., Knuth or Standish. (See the paper by Paul Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a survey of such techniques.) Sizes of free chunks are stored both in the front of each chunk and at the end. This makes consolidating fragmented chunks into bigger chunks very fast. The size fields also hold bits representing whether chunks are free or in use. An allocated chunk looks like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if allocated | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Where "chunk" is the front of the chunk for the purpose of most of the malloc code, but "mem" is the pointer that is returned to the user. "Nextchunk" is the beginning of the next contiguous chunk. Chunks always begin on even word boundries, so the mem portion (which is returned to the user) is also on an even word boundary, and thus at least double-word aligned. Free chunks are stored in circular doubly-linked lists, and look like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `head:‘ | Size of chunk, in bytes |P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Forward pointer to next chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Back pointer to previous chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Unused space (may be 0 bytes long) . . . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `foot:‘ | Size of chunk, in bytes | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ The P (PREV_INUSE) bit, stored in the unused low-order bit of the chunk size (which is always a multiple of two words), is an in-use bit for the *previous* chunk. If that bit is *clear*, then the word before the current chunk size contains the previous chunk size, and can be used to find the front of the previous chunk. The very first chunk allocated always has this bit set, preventing access to non-existent (or non-owned) memory. If prev_inuse is set for any given chunk, then you CANNOT determine the size of the previous chunk, and might even get a memory addressing fault when trying to do so. Note that the `foot‘ of the current chunk is actually represented as the prev_size of the NEXT chunk. This makes it easier to deal with alignments etc but can be very confusing when trying to extend or adapt this code. The two exceptions to all this are 1. The special chunk `top‘ doesn‘t bother using the trailing size field since there is no next contiguous chunk that would have to index off it. After initialization, `top‘ is forced to always exist. If it would become less than MINSIZE bytes long, it is replenished. 2. Chunks allocated via mmap, which have the second-lowest-order bit M (IS_MMAPPED) set in their size fields. Because they are allocated one-by-one, each must contain its own trailing size field. */ /* ---------- Size and alignment checks and conversions ---------- */ /* conversion from malloc headers to user pointers, and back */ #define chunk2mem(p) ((Void_t*)((char*)(p) + 2*SIZE_SZ)) #define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ)) /* The smallest possible chunk */ #define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize)) /* The smallest size we can malloc is an aligned minimal chunk */ #define MINSIZE \ (unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)) /* Check if m has acceptable alignment */ #define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0) #define misaligned_chunk(p) \ ((uintptr_t)(MALLOC_ALIGNMENT == 2 * SIZE_SZ ? (p) : chunk2mem (p)) & MALLOC_ALIGN_MASK) /* Check if a request is so large that it would wrap around zero when padded and aligned. To simplify some other code, the bound is made low enough so that adding MINSIZE will also not wrap around zero. */ #define REQUEST_OUT_OF_RANGE(req) \ ((unsigned long)(req) >= (unsigned long)(INTERNAL_SIZE_T)(-2 * MINSIZE)) /* pad request bytes into a usable size -- internal version */ #define request2size(req) \ (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? MINSIZE : ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) /* Same, except also perform argument check */ #define checked_request2size(req, sz) if (REQUEST_OUT_OF_RANGE(req)) { MALLOC_FAILURE_ACTION; return 0; } (sz) = request2size(req); /* --------------- Physical chunk operations --------------- */ /* size field is or‘ed with PREV_INUSE when previous adjacent chunk in use */ #define PREV_INUSE 0x1 /* extract inuse bit of previous chunk */ #define prev_inuse(p) ((p)->size & PREV_INUSE) /* size field is or‘ed with IS_MMAPPED if the chunk was obtained with mmap() */ #define IS_MMAPPED 0x2 /* check for mmap()‘ed chunk */ #define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED) /* size field is or‘ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x4 /* check for chunk from non-main arena */ #define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA) /* Bits to mask off when extracting size Note: IS_MMAPPED is intentionally not masked off from size field in macros for which mmapped chunks should never be seen. This should cause helpful core dumps to occur if it is tried by accident by people extending or adapting this malloc. */ #define SIZE_BITS (PREV_INUSE|IS_MMAPPED|NON_MAIN_ARENA) /* Get size, ignoring use bits */ #define chunksize(p) ((p)->size & ~(SIZE_BITS)) /* Ptr to next physical malloc_chunk. */ #define next_chunk(p) ((mchunkptr)( ((char*)(p)) + ((p)->size & ~SIZE_BITS) )) /* Ptr to previous physical malloc_chunk */ #define prev_chunk(p) ((mchunkptr)( ((char*)(p)) - ((p)->prev_size) )) /* Treat space at ptr + offset as a chunk */ #define chunk_at_offset(p, s) ((mchunkptr)(((char*)(p)) + (s))) /* extract p‘s inuse bit */ #define inuse(p)\ ((((mchunkptr)(((char*)(p))+((p)->size & ~SIZE_BITS)))->size) & PREV_INUSE) /* set/clear chunk as being inuse without otherwise disturbing */ #define set_inuse(p)\ ((mchunkptr)(((char*)(p)) + ((p)->size & ~SIZE_BITS)))->size |= PREV_INUSE #define clear_inuse(p)\ ((mchunkptr)(((char*)(p)) + ((p)->size & ~SIZE_BITS)))->size &= ~(PREV_INUSE) /* check/set/clear inuse bits in known places */ #define inuse_bit_at_offset(p, s)\ (((mchunkptr)(((char*)(p)) + (s)))->size & PREV_INUSE) #define set_inuse_bit_at_offset(p, s)\ (((mchunkptr)(((char*)(p)) + (s)))->size |= PREV_INUSE) #define clear_inuse_bit_at_offset(p, s)\ (((mchunkptr)(((char*)(p)) + (s)))->size &= ~(PREV_INUSE)) /* Set size at head, without disturbing its use bit */ #define set_head_size(p, s) ((p)->size = (((p)->size & SIZE_BITS) | (s))) /* Set size/use field */ #define set_head(p, s) ((p)->size = (s)) /* Set size at footer (only when chunk is not in use) */ #define set_foot(p, s) (((mchunkptr)((char*)(p) + (s)))->prev_size = (s)) /* -------------------- Internal data structures -------------------- All internal state is held in an instance of malloc_state defined below. There are no other static variables, except in two optional cases: * If USE_MALLOC_LOCK is defined, the mALLOC_MUTEx declared above. * If HAVE_MMAP is true, but mmap doesn‘t support MAP_ANONYMOUS, a dummy file descriptor for mmap. Beware of lots of tricks that minimize the total bookkeeping space requirements. The result is a little over 1K bytes (for 4byte pointers and size_t.) */ /* Bins An array of bin headers for free chunks. Each bin is doubly linked. The bins are approximately proportionally (log) spaced. There are a lot of these bins (128). This may look excessive, but works very well in practice. Most bins hold sizes that are unusual as malloc request sizes, but are more usual for fragments and consolidated sets of chunks, which is what these bins hold, so they can be found quickly. All procedures maintain the invariant that no consolidated chunk physically borders another one, so each chunk in a list is known to be preceeded and followed by either inuse chunks or the ends of memory. Chunks in bins are kept in size order, with ties going to the approximately least recently used chunk. Ordering isn‘t needed for the small bins, which all contain the same-sized chunks, but facilitates best-fit allocation for larger chunks. These lists are just sequential. Keeping them in order almost never requires enough traversal to warrant using fancier ordered data structures. Chunks of the same size are linked with the most recently freed at the front, and allocations are taken from the back. This results in LRU (FIFO) allocation order, which tends to give each chunk an equal opportunity to be consolidated with adjacent freed chunks, resulting in larger free chunks and less fragmentation. To simplify use in double-linked lists, each bin header acts as a malloc_chunk. This avoids special-casing for headers. But to conserve space and improve locality, we allocate only the fd/bk pointers of bins, and then use repositioning tricks to treat these as the fields of a malloc_chunk*. */ typedef struct malloc_chunk* mbinptr; /* addressing -- note that bin_at(0) does not exist */ #define bin_at(m, i) \ (mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) - offsetof (struct malloc_chunk, fd)) /* analog of ++bin */ #define next_bin(b) ((mbinptr)((char*)(b) + (sizeof(mchunkptr)<<1))) /* Reminders about list directionality within bins */ #define first(b) ((b)->fd) #define last(b) ((b)->bk) /* Take a chunk off a bin list */ #define unlink(P, BK, FD) { \ FD = P->fd; BK = P->bk; if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) malloc_printerr (check_action, "corrupted double-linked list", P); else { FD->bk = BK; BK->fd = FD; if (!in_smallbin_range (P->size) && __builtin_expect (P->fd_nextsize != NULL, 0)) { assert (P->fd_nextsize->bk_nextsize == P); assert (P->bk_nextsize->fd_nextsize == P); if (FD->fd_nextsize == NULL) { if (P->fd_nextsize == P) FD->fd_nextsize = FD->bk_nextsize = FD; else { FD->fd_nextsize = P->fd_nextsize; FD->bk_nextsize = P->bk_nextsize; P->fd_nextsize->bk_nextsize = FD; P->bk_nextsize->fd_nextsize = FD; } } else { P->fd_nextsize->bk_nextsize = P->bk_nextsize; P->bk_nextsize->fd_nextsize = P->fd_nextsize; } } } } /* Indexing Bins for sizes < 512 bytes contain chunks of all the same size, spaced 8 bytes apart. Larger bins are approximately logarithmically spaced: 64 bins of size 8 32 bins of size 64 16 bins of size 512 8 bins of size 4096 4 bins of size 32768 2 bins of size 262144 1 bin of size what‘s left There is actually a little bit of slop in the numbers in bin_index for the sake of speed. This makes no difference elsewhere. The bins top out around 1MB because we expect to service large requests via mmap. */ #define NBINS 128 #define NSMALLBINS 64 #define SMALLBIN_WIDTH MALLOC_ALIGNMENT #define MIN_LARGE_SIZE (NSMALLBINS * SMALLBIN_WIDTH) #define in_smallbin_range(sz) \ ((unsigned long)(sz) < (unsigned long)MIN_LARGE_SIZE) #define smallbin_index(sz) \ (SMALLBIN_WIDTH == 16 ? (((unsigned)(sz)) >> 4) : (((unsigned)(sz)) >> 3)) #define largebin_index_32(sz) \ (((((unsigned long)(sz)) >> 6) <= 38)? 56 + (((unsigned long)(sz)) >> 6): ((((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): ((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): ((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): ((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): 126) // XXX It remains to be seen whether it is good to keep the widths of // XXX the buckets the same or whether it should be scaled by a factor // XXX of two as well. #define largebin_index_64(sz) \ (((((unsigned long)(sz)) >> 6) <= 48)? 48 + (((unsigned long)(sz)) >> 6): ((((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): ((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): ((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): ((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): 126) #define largebin_index(sz) \ (SIZE_SZ == 8 ? largebin_index_64 (sz) : largebin_index_32 (sz)) #define bin_index(sz) \ ((in_smallbin_range(sz)) ? smallbin_index(sz) : largebin_index(sz)) /* Unsorted chunks All remainders from chunk splits, as well as all returned chunks, are first placed in the "unsorted" bin. They are then placed in regular bins after malloc gives them ONE chance to be used before binning. So, basically, the unsorted_chunks list acts as a queue, with chunks being placed on it in free (and malloc_consolidate), and taken off (to be either used or placed in bins) in malloc. The NON_MAIN_ARENA flag is never set for unsorted chunks, so it does not have to be taken into account in size comparisons. */ /* The otherwise unindexable 1-bin is used to hold unsorted chunks. */ #define unsorted_chunks(M) (bin_at(M, 1)) /* Top The top-most available chunk (i.e., the one bordering the end of available memory) is treated specially. It is never included in any bin, is used only if no other chunk is available, and is released back to the system if it is very large (see M_TRIM_THRESHOLD). Because top initially points to its own bin with initial zero size, thus forcing extension on the first malloc request, we avoid having any special code in malloc to check whether it even exists yet. But we still need to do so when getting memory from system, so we make initial_top treat the bin as a legal but unusable chunk during the interval between initialization and the first call to sYSMALLOc. (This is somewhat delicate, since it relies on the 2 preceding words to be zero during this interval as well.) */ /* Conveniently, the unsorted bin can be used as dummy top on first call */ #define initial_top(M) (unsorted_chunks(M)) /* Binmap To help compensate for the large number of bins, a one-level index structure is used for bin-by-bin searching. `binmap‘ is a bitvector recording whether bins are definitely empty so they can be skipped over during during traversals. The bits are NOT always cleared as soon as bins are empty, but instead only when they are noticed to be empty during traversal in malloc. */ /* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP) #define idx2block(i) ((i) >> BINMAPSHIFT) #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT)-1)))) #define mark_bin(m,i) ((m)->binmap[idx2block(i)] |= idx2bit(i)) #define unmark_bin(m,i) ((m)->binmap[idx2block(i)] &= ~(idx2bit(i))) #define get_binmap(m,i) ((m)->binmap[idx2block(i)] & idx2bit(i)) /* Fastbins An array of lists holding recently freed small chunks. Fastbins are not doubly linked. It is faster to single-link them, and since chunks are never removed from the middles of these lists, double linking is not necessary. Also, unlike regular bins, they are not even processed in FIFO order (they use faster LIFO) since ordering doesn‘t much matter in the transient contexts in which fastbins are normally used. Chunks in fastbins keep their inuse bit set, so they cannot be consolidated with other free chunks. malloc_consolidate releases all chunks in fastbins and consolidates them with other free chunks. */ typedef struct malloc_chunk* mfastbinptr; #define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx]) /* offset 2 to use otherwise unindexable first 2 bins */ #define fastbin_index(sz) \ ((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) /* The maximum fastbin request size we support */ #define MAX_FAST_SIZE (80 * SIZE_SZ / 4) #define NFASTBINS (fastbin_index(request2size(MAX_FAST_SIZE))+1) /* FASTBIN_CONSOLIDATION_THRESHOLD is the size of a chunk in free() that triggers automatic consolidation of possibly-surrounding fastbin chunks. This is a heuristic, so the exact value should not matter too much. It is defined at half the default trim threshold as a compromise heuristic to only attempt consolidation if it is likely to lead to trimming. However, it is not dynamically tunable, since consolidation reduces fragmentation surrounding large chunks even if trimming is not used. */ #define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL) /* Since the lowest 2 bits in max_fast don‘t matter in size comparisons, they are used as flags. */ /* FASTCHUNKS_BIT held in max_fast indicates that there are probably some fastbin chunks. It is set true on entering a chunk into any fastbin, and cleared only in malloc_consolidate. The truth value is inverted so that have_fastchunks will be true upon startup (since statics are zero-filled), simplifying initialization checks. */ #define FASTCHUNKS_BIT (1U) #define have_fastchunks(M) (((M)->flags & FASTCHUNKS_BIT) == 0) #ifdef ATOMIC_FASTBINS #define clear_fastchunks(M) catomic_or (&(M)->flags, FASTCHUNKS_BIT) #define set_fastchunks(M) catomic_and (&(M)->flags, ~FASTCHUNKS_BIT) #else #define clear_fastchunks(M) ((M)->flags |= FASTCHUNKS_BIT) #define set_fastchunks(M) ((M)->flags &= ~FASTCHUNKS_BIT) #endif /* NONCONTIGUOUS_BIT indicates that MORECORE does not return contiguous regions. Otherwise, contiguity is exploited in merging together, when possible, results from consecutive MORECORE calls. The initial value comes from MORECORE_CONTIGUOUS, but is changed dynamically if mmap is ever used as an sbrk substitute. */ #define NONCONTIGUOUS_BIT (2U) #define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0) #define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0) #define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT) #define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT) /* Set value of max_fast. Use impossibly small value if 0. Precondition: there are no existing fastbin chunks. Setting the value clears fastchunk bit but preserves noncontiguous bit. */ #define set_max_fast(s) \ global_max_fast = ((s) == 0)? SMALLBIN_WIDTH: request2size(s) #define get_max_fast() global_max_fast /* ----------- Internal state representation and initialization ----------- */ struct malloc_state { /* Serialize access. */ mutex_t mutex; /* Flags (formerly in max_fast). */ int flags; #if THREAD_STATS /* Statistics for locking. Only used if THREAD_STATS is defined. */ long stat_lock_direct, stat_lock_loop, stat_lock_wait; #endif /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsigned int binmap[BINMAPSIZE]; /* Linked list */ struct malloc_state *next; #ifdef PER_THREAD /* Linked list for free arenas. */ struct malloc_state *next_free; #endif /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; }; struct malloc_par { /* Tunable parameters */ unsigned long trim_threshold; INTERNAL_SIZE_T top_pad; INTERNAL_SIZE_T mmap_threshold; #ifdef PER_THREAD INTERNAL_SIZE_T arena_test; INTERNAL_SIZE_T arena_max; #endif /* Memory map support */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ int no_dyn_threshold; /* Cache malloc_getpagesize */ unsigned int pagesize; /* Statistics */ INTERNAL_SIZE_T mmapped_mem; /*INTERNAL_SIZE_T sbrked_mem;*/ /*INTERNAL_SIZE_T max_sbrked_mem;*/ INTERNAL_SIZE_T max_mmapped_mem; INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS */ /* First address handed out by MORECORE/sbrk. */ char* sbrk_base; }; /* There are several instances of this struct ("arenas") in this malloc. If you are adapting this malloc in a way that does NOT use a static or mmapped malloc_state, you MUST explicitly zero-fill it before using. This malloc relies on the property that malloc_state is initialized to all zeroes (as is true of C statics). */ static struct malloc_state main_arena; /* There is only one instance of the malloc parameters. */ static struct malloc_par mp_; #ifdef PER_THREAD /* Non public mallopt parameters. */ #define M_ARENA_TEST -7 #define M_ARENA_MAX -8 #endif /* Maximum size of memory handled in fastbins. */ static INTERNAL_SIZE_T global_max_fast; /* Initialize a malloc_state struct. This is called only from within malloc_consolidate, which needs be called in the same contexts anyway. It is never called directly outside of malloc_consolidate because some optimizing compilers try to inline it at all call points, which turns out not to be an optimization at all. (Inlining it in malloc_consolidate is fine though.) */ #if __STD_C static void malloc_init_state(mstate av) #else static void malloc_init_state(av) mstate av; #endif { int i; mbinptr bin; /* Establish circular links for normal bins */ for (i = 1; i < NBINS; ++i) { bin = bin_at(av,i); bin->fd = bin->bk = bin; } #if MORECORE_CONTIGUOUS if (av != &main_arena) #endif set_noncontiguous(av); if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); av->flags |= FASTCHUNKS_BIT; av->top = initial_top(av); } /* Other internal utilities operating on mstates */ #if __STD_C static Void_t* sYSMALLOc(INTERNAL_SIZE_T, mstate); static int sYSTRIm(size_t, mstate); static void malloc_consolidate(mstate); #ifndef _LIBC static Void_t** iALLOc(mstate, size_t, size_t*, int, Void_t**); #endif #else static Void_t* sYSMALLOc(); static int sYSTRIm(); static void malloc_consolidate(); static Void_t** iALLOc(); #endif /* -------------- Early definitions for debugging hooks ---------------- */ /* Define and initialize the hook variables. These weak definitions must appear before any use of the variables in a function (arena.c uses one). */ #ifndef weak_variable #ifndef _LIBC #define weak_variable /**/ #else /* In GNU libc we want the hook variables to be weak definitions to avoid a problem with Emacs. */ #define weak_variable weak_function #endif #endif /* Forward declarations. */ static Void_t* malloc_hook_ini __MALLOC_P ((size_t sz, const __malloc_ptr_t caller)); static Void_t* realloc_hook_ini __MALLOC_P ((Void_t* ptr, size_t sz, const __malloc_ptr_t caller)); static Void_t* memalign_hook_ini __MALLOC_P ((size_t alignment, size_t sz, const __malloc_ptr_t caller)); void weak_variable (*__malloc_initialize_hook) (void) = NULL; void weak_variable (*__free_hook) (__malloc_ptr_t __ptr, const __malloc_ptr_t) = NULL; __malloc_ptr_t weak_variable (*__malloc_hook) (size_t __size, const __malloc_ptr_t) = malloc_hook_ini; __malloc_ptr_t weak_variable (*__realloc_hook) (__malloc_ptr_t __ptr, size_t __size, const __malloc_ptr_t) = realloc_hook_ini; __malloc_ptr_t weak_variable (*__memalign_hook) (size_t __alignment, size_t __size, const __malloc_ptr_t) = memalign_hook_ini; void weak_variable (*__after_morecore_hook) (void) = NULL; /* ---------------- Error behavior ------------------------------------ */ #ifndef DEFAULT_CHECK_ACTION #define DEFAULT_CHECK_ACTION 3 #endif static int check_action = DEFAULT_CHECK_ACTION; /* ------------------ Testing support ----------------------------------*/ static int perturb_byte; #define alloc_perturb(p, n) memset (p, (perturb_byte ^ 0xff) & 0xff, n) #define free_perturb(p, n) memset (p, perturb_byte & 0xff, n) /* ------------------- Support for multiple arenas -------------------- */ #include "arena.c" /* Debugging support These routines make a number of assertions about the states of data structures that should be true at all times. If any are not true, it‘s very likely that a user program has somehow trashed memory. (It‘s also possible that there is a coding error in malloc. In which case, please report it!) */ #if ! MALLOC_DEBUG #define check_chunk(A,P) #define check_free_chunk(A,P) #define check_inuse_chunk(A,P) #define check_remalloced_chunk(A,P,N) #define check_malloced_chunk(A,P,N) #define check_malloc_state(A) #else #define check_chunk(A,P) do_check_chunk(A,P) #define check_free_chunk(A,P) do_check_free_chunk(A,P) #define check_inuse_chunk(A,P) do_check_inuse_chunk(A,P) #define check_remalloced_chunk(A,P,N) do_check_remalloced_chunk(A,P,N) #define check_malloced_chunk(A,P,N) do_check_malloced_chunk(A,P,N) #define check_malloc_state(A) do_check_malloc_state(A) /* Properties of all chunks */ #if __STD_C static void do_check_chunk(mstate av, mchunkptr p) #else static void do_check_chunk(av, p) mstate av; mchunkptr p; #endif { unsigned long sz = chunksize(p); /* min and max possible addresses assuming contiguous allocation */ char* max_address = (char*)(av->top) + chunksize(av->top); char* min_address = max_address - av->system_mem; if (!chunk_is_mmapped(p)) { /* Has legal address ... */ if (p != av->top) { if (contiguous(av)) { assert(((char*)p) >= min_address); assert(((char*)p + sz) <= ((char*)(av->top))); } } else { /* top size is always at least MINSIZE */ assert((unsigned long)(sz) >= MINSIZE); /* top predecessor always marked inuse */ assert(prev_inuse(p)); } } else { #if HAVE_MMAP /* address is outside main heap */ if (contiguous(av) && av->top != initial_top(av)) { assert(((char*)p) < min_address || ((char*)p) >= max_address); } /* chunk is page-aligned */ assert(((p->prev_size + sz) & (mp_.pagesize-1)) == 0); /* mem is aligned */ assert(aligned_OK(chunk2mem(p))); #else /* force an appropriate assert violation if debug set */ assert(!chunk_is_mmapped(p)); #endif } } /* Properties of free chunks */ #if __STD_C static void do_check_free_chunk(mstate av, mchunkptr p) #else static void do_check_free_chunk(av, p) mstate av; mchunkptr p; #endif { INTERNAL_SIZE_T sz = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); mchunkptr next = chunk_at_offset(p, sz); do_check_chunk(av, p); /* Chunk must claim to be free ... */ assert(!inuse(p)); assert (!chunk_is_mmapped(p)); /* Unless a special marker, must have OK fields */ if ((unsigned long)(sz) >= MINSIZE) { assert((sz & MALLOC_ALIGN_MASK) == 0); assert(aligned_OK(chunk2mem(p))); /* ... matching footer field */ assert(next->prev_size == sz); /* ... and is fully consolidated */ assert(prev_inuse(p)); assert (next == av->top || inuse(next)); /* ... and has minimally sane links */ assert(p->fd->bk == p); assert(p->bk->fd == p); } else /* markers are always of size SIZE_SZ */ assert(sz == SIZE_SZ); } /* Properties of inuse chunks */ #if __STD_C static void do_check_inuse_chunk(mstate av, mchunkptr p) #else static void do_check_inuse_chunk(av, p) mstate av; mchunkptr p; #endif { mchunkptr next; do_check_chunk(av, p); if (chunk_is_mmapped(p)) return; /* mmapped chunks have no next/prev */ /* Check whether it claims to be in use ... */ assert(inuse(p)); next = next_chunk(p); /* ... and is surrounded by OK chunks. Since more things can be checked with free chunks than inuse ones, if an inuse chunk borders them and debug is on, it‘s worth doing them. */ if (!prev_inuse(p)) { /* Note that we cannot even look at prev unless it is not inuse */ mchunkptr prv = prev_chunk(p); assert(next_chunk(prv) == p); do_check_free_chunk(av, prv); } if (next == av->top) { assert(prev_inuse(next)); assert(chunksize(next) >= MINSIZE); } else if (!inuse(next)) do_check_free_chunk(av, next); } /* Properties of chunks recycled from fastbins */ #if __STD_C static void do_check_remalloced_chunk(mstate av, mchunkptr p, INTERNAL_SIZE_T s) #else static void do_check_remalloced_chunk(av, p, s) mstate av; mchunkptr p; INTERNAL_SIZE_T s; #endif { INTERNAL_SIZE_T sz = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); if (!chunk_is_mmapped(p)) { assert(av == arena_for_chunk(p)); if (chunk_non_main_arena(p)) assert(av != &main_arena); else assert(av == &main_arena); } do_check_inuse_chunk(av, p); /* Legal size ... */ assert((sz & MALLOC_ALIGN_MASK) == 0); assert((unsigned long)(sz) >= MINSIZE); /* ... and alignment */ assert(aligned_OK(chunk2mem(p))); /* chunk is less than MINSIZE more than request */ assert((long)(sz) - (long)(s) >= 0); assert((long)(sz) - (long)(s + MINSIZE) < 0); } /* Properties of nonrecycled chunks at the point they are malloced */ #if __STD_C static void do_check_malloced_chunk(mstate av, mchunkptr p, INTERNAL_SIZE_T s) #else static void do_check_malloced_chunk(av, p, s) mstate av; mchunkptr p; INTERNAL_SIZE_T s; #endif { /* same as recycled case ... */ do_check_remalloced_chunk(av, p, s); /* ... plus, must obey implementation invariant that prev_inuse is always true of any allocated chunk; i.e., that each allocated chunk borders either a previously allocated and still in-use chunk, or the base of its memory arena. This is ensured by making all allocations from the the `lowest‘ part of any found chunk. This does not necessarily hold however for chunks recycled via fastbins. */ assert(prev_inuse(p)); } /* Properties of malloc_state. This may be useful for debugging malloc, as well as detecting user programmer errors that somehow write into malloc_state. If you are extending or experimenting with this malloc, you can probably figure out how to hack this routine to print out or display chunk addresses, sizes, bins, and other instrumentation. */ static void do_check_malloc_state(mstate av) { int i; mchunkptr p; mchunkptr q; mbinptr b; unsigned int idx; INTERNAL_SIZE_T size; unsigned long total = 0; int max_fast_bin; /* internal size_t must be no wider than pointer type */ assert(sizeof(INTERNAL_SIZE_T) <= sizeof(char*)); /* alignment is a power of 2 */ assert((MALLOC_ALIGNMENT & (MALLOC_ALIGNMENT-1)) == 0); /* cannot run remaining checks until fully initialized */ if (av->top == 0 || av->top == initial_top(av)) return; /* pagesize is a power of 2 */ assert((mp_.pagesize & (mp_.pagesize-1)) == 0); /* A contiguous main_arena is consistent with sbrk_base. */ if (av == &main_arena && contiguous(av)) assert((char*)mp_.sbrk_base + av->system_mem == (char*)av->top + chunksize(av->top)); /* properties of fastbins */ /* max_fast is in allowed range */ assert((get_max_fast () & ~1) <= request2size(MAX_FAST_SIZE)); max_fast_bin = fastbin_index(get_max_fast ()); for (i = 0; i < NFASTBINS; ++i) { p = av->fastbins[i]; /* The following test can only be performed for the main arena. While mallopt calls malloc_consolidate to get rid of all fast bins (especially those larger than the new maximum) this does only happen for the main arena. Trying to do this for any other arena would mean those arenas have to be locked and malloc_consolidate be called for them. This is excessive. And even if this is acceptable to somebody it still cannot solve the problem completely since if the arena is locked a concurrent malloc call might create a new arena which then could use the newly invalid fast bins. */ /* all bins past max_fast are empty */ if (av == &main_arena && i > max_fast_bin) assert(p == 0); while (p != 0) { /* each chunk claims to be inuse */ do_check_inuse_chunk(av, p); total += chunksize(p); /* chunk belongs in this bin */ assert(fastbin_index(chunksize(p)) == i); p = p->fd; } } if (total != 0) assert(have_fastchunks(av)); else if (!have_fastchunks(av)) assert(total == 0); /* check normal bins */ for (i = 1; i < NBINS; ++i) { b = bin_at(av,i); /* binmap is accurate (except for bin 1 == unsorted_chunks) */ if (i >= 2) { unsigned int binbit = get_binmap(av,i); int empty = last(b) == b; if (!binbit) assert(empty); else if (!empty) assert(binbit); } for (p = last(b); p != b; p = p->bk) { /* each chunk claims to be free */ do_check_free_chunk(av, p); size = chunksize(p); total += size; if (i >= 2) { /* chunk belongs in bin */ idx = bin_index(size); assert(idx == i); /* lists are sorted */ assert(p->bk == b || (unsigned long)chunksize(p->bk) >= (unsigned long)chunksize(p)); if (!in_smallbin_range(size)) { if (p->fd_nextsize != NULL) { if (p->fd_nextsize == p) assert (p->bk_nextsize == p); else { if (p->fd_nextsize == first (b)) assert (chunksize (p) < chunksize (p->fd_nextsize)); else assert (chunksize (p) > chunksize (p->fd_nextsize)); if (p == first (b)) assert (chunksize (p) > chunksize (p->bk_nextsize)); else assert (chunksize (p) < chunksize (p->bk_nextsize)); } } else assert (p->bk_nextsize == NULL); } } else if (!in_smallbin_range(size)) assert (p->fd_nextsize == NULL && p->bk_nextsize == NULL); /* chunk is followed by a legal chain of inuse chunks */ for (q = next_chunk(p); (q != av->top && inuse(q) && (unsigned long)(chunksize(q)) >= MINSIZE); q = next_chunk(q)) do_check_inuse_chunk(av, q); } } /* top chunk is OK */ check_chunk(av, av->top); /* sanity checks for statistics */ #ifdef NO_THREADS assert(total <= (unsigned long)(mp_.max_total_mem)); assert(mp_.n_mmaps >= 0); #endif assert(mp_.n_mmaps <= mp_.max_n_mmaps); assert((unsigned long)(av->system_mem) <= (unsigned long)(av->max_system_mem)); assert((unsigned long)(mp_.mmapped_mem) <= (unsigned long)(mp_.max_mmapped_mem)); #ifdef NO_THREADS assert((unsigned long)(mp_.max_total_mem) >= (unsigned long)(mp_.mmapped_mem) + (unsigned long)(av->system_mem)); #endif } #endif /* ----------------- Support for debugging hooks -------------------- */ #include "hooks.c" /* ----------- Routines dealing with system allocation -------------- */ /* sysmalloc handles malloc cases requiring more memory from the system. On entry, it is assumed that av->top does not have enough space to service request for nb bytes, thus requiring that av->top be extended or replaced. */ #if __STD_C static Void_t* sYSMALLOc(INTERNAL_SIZE_T nb, mstate av) #else static Void_t* sYSMALLOc(nb, av) INTERNAL_SIZE_T nb; mstate av; #endif { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char* old_end; /* its end address */ long size; /* arg to first MORECORE or mmap call */ char* brk; /* return value from MORECORE */ long correction; /* arg to 2nd MORECORE call */ char* snd_brk; /* 2nd return val */ INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char* aligned_brk; /* aligned offset into brk */ mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsigned long remainder_size; /* its size */ unsigned long sum; /* for updating stats */ size_t pagemask = mp_.pagesize - 1; bool tried_mmap = false; #if HAVE_MMAP /* If have mmap, and the request size meets the mmap threshold, and the system supports mmap, and there are few enough currently allocated mmapped regions, try to directly map this request rather than expanding top. */ if ((unsigned long)(nb) >= (unsigned long)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max)) { char* mm; /* return value from mmap call*/ try_mmap: /* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. */ #if 1 /* See the front_misalign handling below, for glibc there is no need for further alignments. */ size = (nb + SIZE_SZ + pagemask) & ~pagemask; #else size = (nb + SIZE_SZ + MALLOC_ALIGN_MASK + pagemask) & ~pagemask; #endif tried_mmap = true; /* Don‘t try if size wraps around 0 */ if ((unsigned long)(size) > (unsigned long)(nb)) { mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE)); if (mm != MAP_FAILED) { /* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */ #if 1 /* For glibc, chunk2mem increases the address by 2*SIZE_SZ and MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap‘ed area is page aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */ assert (((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0); #else front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { correction = MALLOC_ALIGNMENT - front_misalign; p = (mchunkptr)(mm + correction); p->prev_size = correction; set_head(p, (size - correction) |IS_MMAPPED); } else #endif { p = (mchunkptr)mm; set_head(p, size|IS_MMAPPED); } /* update statistics */ if (++mp_.n_mmaps > mp_.max_n_mmaps) mp_.max_n_mmaps = mp_.n_mmaps; sum = mp_.mmapped_mem += size; if (sum > (unsigned long)(mp_.max_mmapped_mem)) mp_.max_mmapped_mem = sum; #ifdef NO_THREADS sum += av->system_mem; if (sum > (unsigned long)(mp_.max_total_mem)) mp_.max_total_mem = sum; #endif check_chunk(av, p); return chunk2mem(p); } } } #endif /* Record incoming configuration of top */ old_top = av->top; old_size = chunksize(old_top); old_end = (char*)(chunk_at_offset(old_top, old_size)); brk = snd_brk = (char*)(MORECORE_FAILURE); /* If not the first time through, we require old_size to be at least MINSIZE and to have prev_inuse set. */ assert((old_top == initial_top(av) && old_size == 0) || ((unsigned long) (old_size) >= MINSIZE && prev_inuse(old_top) && ((unsigned long)old_end & pagemask) == 0)); /* Precondition: not enough current space to satisfy nb request */ assert((unsigned long)(old_size) < (unsigned long)(nb + MINSIZE)); #ifndef ATOMIC_FASTBINS /* Precondition: all fastbins are consolidated */ assert(!have_fastchunks(av)); #endif if (av != &main_arena) { heap_info *old_heap, *heap; size_t old_heap_size; /* First try to extend the current heap. */ old_heap = heap_for_ptr(old_top); old_heap_size = old_heap->size; if ((long) (MINSIZE + nb - old_size) > 0 && grow_heap(old_heap, MINSIZE + nb - old_size) == 0) { av->system_mem += old_heap->size - old_heap_size; arena_mem += old_heap->size - old_heap_size; #if 0 if(mmapped_mem + arena_mem + sbrked_mem > max_total_mem) max_total_mem = mmapped_mem + arena_mem + sbrked_mem; #endif set_head(old_top, (((char *)old_heap + old_heap->size) - (char *)old_top) | PREV_INUSE); } else if ((heap = new_heap(nb + (MINSIZE + sizeof(*heap)), mp_.top_pad))) { /* Use a newly allocated heap. */ heap->ar_ptr = av; heap->prev = old_heap; av->system_mem += heap->size; arena_mem += heap->size; #if 0 if((unsigned long)(mmapped_mem + arena_mem + sbrked_mem) > max_total_mem) max_total_mem = mmapped_mem + arena_mem + sbrked_mem; #endif /* Set up the new top. */ top(av) = chunk_at_offset(heap, sizeof(*heap)); set_head(top(av), (heap->size - sizeof(*heap)) | PREV_INUSE); /* Setup fencepost and free the old top chunk. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size -= MINSIZE; set_head(chunk_at_offset(old_top, old_size + 2*SIZE_SZ), 0|PREV_INUSE); if (old_size >= MINSIZE) { set_head(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)|PREV_INUSE); set_foot(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)); set_head(old_top, old_size|PREV_INUSE|NON_MAIN_ARENA); #ifdef ATOMIC_FASTBINS _int_free(av, old_top, 1); #else _int_free(av, old_top); #endif } else { set_head(old_top, (old_size + 2*SIZE_SZ)|PREV_INUSE); set_foot(old_top, (old_size + 2*SIZE_SZ)); } } else if (!tried_mmap) /* We can at least try to use to mmap memory. */ goto try_mmap; } else { /* av == main_arena */ /* Request enough space for nb + pad + overhead */ size = nb + mp_.top_pad + MINSIZE; /* If contiguous, we can subtract out existing space that we hope to combine with new space. We add it back later only if we don‘t actually get contiguous space. */ if (contiguous(av)) size -= old_size; /* Round to a multiple of page size. If MORECORE is not contiguous, this ensures that we only call it with whole-page arguments. And if MORECORE is contiguous and this is not first time through, this preserves page-alignment of previous calls. Otherwise, we correct to page-align below. */ size = (size + pagemask) & ~pagemask; /* Don‘t try to call MORECORE if argument is so big as to appear negative. Note that since mmap takes size_t arg, it may succeed below even if we cannot call MORECORE. */ if (size > 0) brk = (char*)(MORECORE(size)); if (brk != (char*)(MORECORE_FAILURE)) { /* Call the `morecore‘ hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); } else { /* If have mmap, try using it as a backup when MORECORE fails or cannot be used. This is worth doing on systems that have "holes" in address space, so sbrk cannot extend to give contiguous space, but space is available elsewhere. Note that we ignore mmap max count and threshold limits, since the space will not be used as a segregated mmap region. */ #if HAVE_MMAP /* Cannot merge with old top, so add its size back in */ if (contiguous(av)) size = (size + old_size + pagemask) & ~pagemask; /* If we are relying on mmap as backup, then use larger units */ if ((unsigned long)(size) < (unsigned long)(MMAP_AS_MORECORE_SIZE)) size = MMAP_AS_MORECORE_SIZE; /* Don‘t try if size wraps around 0 */ if ((unsigned long)(size) > (unsigned long)(nb)) { char *mbrk = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE)); if (mbrk != MAP_FAILED) { /* We do not need, and cannot use, another sbrk call to find end */ brk = mbrk; snd_brk = brk + size; /* Record that we no longer have a contiguous sbrk region. After the first time mmap is used as backup, we do not ever rely on contiguous space since this could incorrectly bridge regions. */ set_noncontiguous(av); } } #endif } if (brk != (char*)(MORECORE_FAILURE)) { if (mp_.sbrk_base == 0) mp_.sbrk_base = brk; av->system_mem += size; /* If MORECORE extends previous space, we can likewise extend top size. */ if (brk == old_end && snd_brk == (char*)(MORECORE_FAILURE)) set_head(old_top, (size + old_size) | PREV_INUSE); else if (contiguous(av) && old_size && brk < old_end) { /* Oops! Someone else killed our space.. Can‘t touch anything. */ malloc_printerr (3, "break adjusted to free malloc space", brk); } /* Otherwise, make adjustments: * If the first time through or noncontiguous, we need to call sbrk just to find out where the end of memory lies. * We need to ensure that all returned chunks from malloc will meet MALLOC_ALIGNMENT * If there was an intervening foreign sbrk, we need to adjust sbrk request size to account for fact that we will not be able to combine new space with existing space in old_top. * Almost all systems internally allocate whole pages at a time, in which case we might as well use the whole last page of request. So we allocate enough more memory to hit a page boundary now, which in turn causes future contiguous calls to page-align. */ else { front_misalign = 0; end_misalign = 0; correction = 0; aligned_brk = brk; /* handle contiguous cases */ if (contiguous(av)) { /* Count foreign sbrk as system_mem. */ if (old_size) av->system_mem += brk - old_end; /* Guarantee alignment of first new chunk made from this space */ front_misalign = (INTERNAL_SIZE_T)chunk2mem(brk) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { /* Skip over some bytes to arrive at an aligned position. We don‘t need to specially mark these wasted front bytes. They will never be accessed anyway because prev_inuse of av->top (and any chunk created from its start) is always true after initialization. */ correction = MALLOC_ALIGNMENT - front_misalign; aligned_brk += correction; } /* If this isn‘t adjacent to existing space, then we will not be able to merge with old_top space, so must add to 2nd request. */ correction += old_size; /* Extend the end address to hit a page boundary */ end_misalign = (INTERNAL_SIZE_T)(brk + size + correction); correction += ((end_misalign + pagemask) & ~pagemask) - end_misalign; assert(correction >= 0); snd_brk = (char*)(MORECORE(correction)); /* If can‘t allocate correction, try to at least find out current brk. It might be enough to proceed without failing. Note that if second sbrk did NOT fail, we assume that space is contiguous with first sbrk. This is a safe assumption unless program is multithreaded but doesn‘t use locks and a foreign sbrk occurred between our first and second calls. */ if (snd_brk == (char*)(MORECORE_FAILURE)) { correction = 0; snd_brk = (char*)(MORECORE(0)); } else { /* Call the `morecore‘ hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); } } /* handle non-contiguous cases */ else { /* MORECORE/mmap must correctly align */ assert(((unsigned long)chunk2mem(brk) & MALLOC_ALIGN_MASK) == 0); /* Find out current end of memory */ if (snd_brk == (char*)(MORECORE_FAILURE)) { snd_brk = (char*)(MORECORE(0)); } } /* Adjust top based on results of second sbrk */ if (snd_brk != (char*)(MORECORE_FAILURE)) { av->top = (mchunkptr)aligned_brk; set_head(av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE); av->system_mem += correction; /* If not the first time through, we either have a gap due to foreign sbrk or a non-contiguous region. Insert a double fencepost at old_top to prevent consolidation with space we don‘t own. These fenceposts are artificial chunks that are marked as inuse and are in any case too small to use. We need two to make sizes and alignments work out. */ if (old_size != 0) { /* Shrink old_top to insert fenceposts, keeping size a multiple of MALLOC_ALIGNMENT. We know there is at least enough space in old_top to do this. */ old_size = (old_size - 4*SIZE_SZ) & ~MALLOC_ALIGN_MASK; set_head(old_top, old_size | PREV_INUSE); /* Note that the following assignments completely overwrite old_top when old_size was previously MINSIZE. This is intentional. We need the fencepost, even if old_top otherwise gets lost. */ chunk_at_offset(old_top, old_size )->size = (2*SIZE_SZ)|PREV_INUSE; chunk_at_offset(old_top, old_size + 2*SIZE_SZ)->size = (2*SIZE_SZ)|PREV_INUSE; /* If possible, release the rest. */ if (old_size >= MINSIZE) { #ifdef ATOMIC_FASTBINS _int_free(av, old_top, 1); #else _int_free(av, old_top); #endif } } } } /* Update statistics */ #ifdef NO_THREADS sum = av->system_mem + mp_.mmapped_mem; if (sum > (unsigned long)(mp_.max_total_mem)) mp_.max_total_mem = sum; #endif } } /* if (av != &main_arena) */ if ((unsigned long)av->system_mem > (unsigned long)(av->max_system_mem)) av->max_system_mem = av->system_mem; check_malloc_state(av); /* finally, do the allocation */ p = av->top; size = chunksize(p); /* check that one of the above allocation paths succeeded */ if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE)) { remainder_size = size - nb; remainder = chunk_at_offset(p, nb); av->top = remainder; set_head(p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); check_malloced_chunk(av, p, nb); return chunk2mem(p); } /* catch all failure paths */ MALLOC_FAILURE_ACTION; return 0; } /* sYSTRIm is an inverse of sorts to sYSMALLOc. It gives memory back to the system (via negative arguments to sbrk) if there is unused memory at the `high‘ end of the malloc pool. It is called automatically by free() when top space exceeds the trim threshold. It is also called by the public malloc_trim routine. It returns 1 if it actually released any memory, else 0. */ #if __STD_C static int sYSTRIm(size_t pad, mstate av) #else static int sYSTRIm(pad, av) size_t pad; mstate av; #endif { long top_size; /* Amount of top-most memory */ long extra; /* Amount to release */ long released; /* Amount actually released */ char* current_brk; /* address returned by pre-check sbrk call */ char* new_brk; /* address returned by post-check sbrk call */ size_t pagesz; pagesz = mp_.pagesize; top_size = chunksize(av->top); /* Release in pagesize units, keeping at least one page */ extra = ((top_size - pad - MINSIZE + (pagesz-1)) / pagesz - 1) * pagesz; if (extra > 0) { /* Only proceed if end of memory is where we last set it. This avoids problems if there were foreign sbrk calls. */ current_brk = (char*)(MORECORE(0)); if (current_brk == (char*)(av->top) + top_size) { /* Attempt to release memory. We ignore MORECORE return value, and instead call again to find out where new end of memory is. This avoids problems if first call releases less than we asked, of if failure somehow altered brk value. (We could still encounter problems if it altered brk in some very bad way, but the only thing we can do is adjust anyway, which will cause some downstream failure.) */ MORECORE(-extra); /* Call the `morecore‘ hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); new_brk = (char*)(MORECORE(0)); if (new_brk != (char*)MORECORE_FAILURE) { released = (long)(current_brk - new_brk); if (released != 0) { /* Success. Adjust top. */ av->system_mem -= released; set_head(av->top, (top_size - released) | PREV_INUSE); check_malloc_state(av); return 1; } } } } return 0; } #ifdef HAVE_MMAP static void internal_function #if __STD_C munmap_chunk(mchunkptr p) #else munmap_chunk(p) mchunkptr p; #endif { INTERNAL_SIZE_T size = chunksize(p); assert (chunk_is_mmapped(p)); #if 0 assert(! ((char*)p >= mp_.sbrk_base && (char*)p < mp_.sbrk_base + mp_.sbrked_mem)); assert((mp_.n_mmaps > 0)); #endif uintptr_t block = (uintptr_t) p - p->prev_size; size_t total_size = p->prev_size + size; /* Unfortunately we have to do the compilers job by hand here. Normally we would test BLOCK and TOTAL-SIZE separately for compliance with the page size. But gcc does not recognize the optimization possibility (in the moment at least) so we combine the two values into one before the bit test. */ if (__builtin_expect (((block | total_size) & (mp_.pagesize - 1)) != 0, 0)) { malloc_printerr (check_action, "munmap_chunk(): invalid pointer", chunk2mem (p)); return; } mp_.n_mmaps--; mp_.mmapped_mem -= total_size; int ret __attribute__ ((unused)) = munmap((char *)block, total_size); /* munmap returns non-zero on failure */ assert(ret == 0); } #if HAVE_MREMAP static mchunkptr internal_function #if __STD_C mremap_chunk(mchunkptr p, size_t new_size) #else mremap_chunk(p, new_size) mchunkptr p; size_t new_size; #endif { size_t page_mask = mp_.pagesize - 1; INTERNAL_SIZE_T offset = p->prev_size; INTERNAL_SIZE_T size = chunksize(p); char *cp; assert (chunk_is_mmapped(p)); #if 0 assert(! ((char*)p >= mp_.sbrk_base && (char*)p < mp_.sbrk_base + mp_.sbrked_mem)); assert((mp_.n_mmaps > 0)); #endif assert(((size + offset) & (mp_.pagesize-1)) == 0); /* Note the extra SIZE_SZ overhead as in mmap_chunk(). */ new_size = (new_size + offset + SIZE_SZ + page_mask) & ~page_mask; /* No need to remap if the number of pages does not change. */ if (size + offset == new_size) return p; cp = (char *)mremap((char *)p - offset, size + offset, new_size, MREMAP_MAYMOVE); if (cp == MAP_FAILED) return 0; p = (mchunkptr)(cp + offset); assert(aligned_OK(chunk2mem(p))); assert((p->prev_size == offset)); set_head(p, (new_size - offset)|IS_MMAPPED); mp_.mmapped_mem -= size + offset; mp_.mmapped_mem += new_size; if ((unsigned long)mp_.mmapped_mem > (unsigned long)mp_.max_mmapped_mem) mp_.max_mmapped_mem = mp_.mmapped_mem; #ifdef NO_THREADS if ((unsigned long)(mp_.mmapped_mem + arena_mem + main_arena.system_mem) > mp_.max_total_mem) mp_.max_total_mem = mp_.mmapped_mem + arena_mem + main_arena.system_mem; #endif return p; } #endif /* HAVE_MREMAP */ #endif /* HAVE_MMAP */ /*------------------------ Public wrappers. --------------------------------*/ Void_t* public_mALLOc(size_t bytes) { mstate ar_ptr; Void_t *victim; __malloc_ptr_t (*hook) (size_t, __const __malloc_ptr_t) = force_reg (__malloc_hook); if (__builtin_expect (hook != NULL, 0)) return (*hook)(bytes, RETURN_ADDRESS (0)); arena_lookup(ar_ptr); #if 0 // XXX We need double-word CAS and fastbins must be extended to also // XXX hold a generation counter for each entry. if (ar_ptr) { INTERNAL_SIZE_T nb; /* normalized request size */ checked_request2size(bytes, nb); if (nb <= get_max_fast ()) { long int idx = fastbin_index(nb); mfastbinptr* fb = &fastbin (ar_ptr, idx); mchunkptr pp = *fb; mchunkptr v; do { v = pp; if (v == NULL) break; } while ((pp = catomic_compare_and_exchange_val_acq (fb, v->fd, v)) != v); if (v != 0) { if (__builtin_expect (fastbin_index (chunksize (v)) != idx, 0)) malloc_printerr (check_action, "malloc(): memory corruption (fast)", chunk2mem (v)); check_remalloced_chunk(ar_ptr, v, nb); void *p = chunk2mem(v); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } } #endif arena_lock(ar_ptr, bytes); if(!ar_ptr) return 0; victim = _int_malloc(ar_ptr, bytes); if(!victim) { /* Maybe the failure is due to running out of mmapped areas. */ if(ar_ptr != &main_arena) { (void)mutex_unlock(&ar_ptr->mutex); ar_ptr = &main_arena; (void)mutex_lock(&ar_ptr->mutex); victim = _int_malloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex); } else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ ar_ptr = arena_get2(ar_ptr->next ? ar_ptr : 0, bytes); (void)mutex_unlock(&main_arena.mutex); if(ar_ptr) { victim = _int_malloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex); } #endif } } else (void)mutex_unlock(&ar_ptr->mutex); assert(!victim || chunk_is_mmapped(mem2chunk(victim)) || ar_ptr == arena_for_chunk(mem2chunk(victim))); return victim; } #ifdef libc_hidden_def libc_hidden_def(public_mALLOc) #endif void public_fREe(Void_t* mem) { mstate ar_ptr; mchunkptr p; /* chunk corresponding to mem */ void (*hook) (__malloc_ptr_t, __const __malloc_ptr_t) = force_reg (__free_hook); if (__builtin_expect (hook != NULL, 0)) { (*hook)(mem, RETURN_ADDRESS (0)); return; } if (mem == 0) /* free(0) has no effect */ return; p = mem2chunk(mem); #if HAVE_MMAP if (chunk_is_mmapped(p)) /* release mmapped memory. */ { /* see if the dynamic brk/mmap threshold needs adjusting */ if (!mp_.no_dyn_threshold && p->size > mp_.mmap_threshold && p->size <= DEFAULT_MMAP_THRESHOLD_MAX) { mp_.mmap_threshold = chunksize (p); mp_.trim_threshold = 2 * mp_.mmap_threshold; } munmap_chunk(p); return; } #endif ar_ptr = arena_for_chunk(p); #ifdef ATOMIC_FASTBINS _int_free(ar_ptr, p, 0); #else # if THREAD_STATS if(!mutex_trylock(&ar_ptr->mutex)) ++(ar_ptr->stat_lock_direct); else { (void)mutex_lock(&ar_ptr->mutex); ++(ar_ptr->stat_lock_wait); } # else (void)mutex_lock(&ar_ptr->mutex); # endif _int_free(ar_ptr, p); (void)mutex_unlock(&ar_ptr->mutex); #endif } #ifdef libc_hidden_def libc_hidden_def (public_fREe) #endif Void_t* public_rEALLOc(Void_t* oldmem, size_t bytes) { mstate ar_ptr; INTERNAL_SIZE_T nb; /* padded request size */ Void_t* newp; /* chunk to return */ __malloc_ptr_t (*hook) (__malloc_ptr_t, size_t, __const __malloc_ptr_t) = force_reg (__realloc_hook); if (__builtin_expect (hook != NULL, 0)) return (*hook)(oldmem, bytes, RETURN_ADDRESS (0)); #if REALLOC_ZERO_BYTES_FREES if (bytes == 0 && oldmem != NULL) { public_fREe(oldmem); return 0; } #endif /* realloc of null is supposed to be same as malloc */ if (oldmem == 0) return public_mALLOc(bytes); /* chunk corresponding to oldmem */ const mchunkptr oldp = mem2chunk(oldmem); /* its size */ const INTERNAL_SIZE_T oldsize = chunksize(oldp); /* Little security check which won‘t hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) oldp > (uintptr_t) -oldsize, 0) || __builtin_expect (misaligned_chunk (oldp), 0)) { malloc_printerr (check_action, "realloc(): invalid pointer", oldmem); return NULL; } checked_request2size(bytes, nb); #if HAVE_MMAP if (chunk_is_mmapped(oldp)) { Void_t* newmem; #if HAVE_MREMAP newp = mremap_chunk(oldp, nb); if(newp) return chunk2mem(newp); #endif /* Note the extra SIZE_SZ overhead. */ if(oldsize - SIZE_SZ >= nb) return oldmem; /* do nothing */ /* Must alloc, copy, free. */ newmem = public_mALLOc(bytes); if (newmem == 0) return 0; /* propagate failure */ MALLOC_COPY(newmem, oldmem, oldsize - 2*SIZE_SZ); munmap_chunk(oldp); return newmem; } #endif ar_ptr = arena_for_chunk(oldp); #if THREAD_STATS if(!mutex_trylock(&ar_ptr->mutex)) ++(ar_ptr->stat_lock_direct); else { (void)mutex_lock(&ar_ptr->mutex); ++(ar_ptr->stat_lock_wait); } #else (void)mutex_lock(&ar_ptr->mutex); #endif #if !defined NO_THREADS && !defined PER_THREAD /* As in malloc(), remember this arena for the next allocation. */ tsd_setspecific(arena_key, (Void_t *)ar_ptr); #endif newp = _int_realloc(ar_ptr, oldp, oldsize, nb); (void)mutex_unlock(&ar_ptr->mutex); assert(!newp || chunk_is_mmapped(mem2chunk(newp)) || ar_ptr == arena_for_chunk(mem2chunk(newp))); if (newp == NULL) { /* Try harder to allocate memory in other arenas. */ newp = public_mALLOc(bytes); if (newp != NULL) { MALLOC_COPY (newp, oldmem, oldsize - SIZE_SZ); #ifdef ATOMIC_FASTBINS _int_free(ar_ptr, oldp, 0); #else # if THREAD_STATS if(!mutex_trylock(&ar_ptr->mutex)) ++(ar_ptr->stat_lock_direct); else { (void)mutex_lock(&ar_ptr->mutex); ++(ar_ptr->stat_lock_wait); } # else (void)mutex_lock(&ar_ptr->mutex); # endif _int_free(ar_ptr, oldp); (void)mutex_unlock(&ar_ptr->mutex); #endif } } return newp; } #ifdef libc_hidden_def libc_hidden_def (public_rEALLOc) #endif Void_t* public_mEMALIGn(size_t alignment, size_t bytes) { mstate ar_ptr; Void_t *p; __malloc_ptr_t (*hook) __MALLOC_PMT ((size_t, size_t, __const __malloc_ptr_t)) = force_reg (__memalign_hook); if (__builtin_expect (hook != NULL, 0)) return (*hook)(alignment, bytes, RETURN_ADDRESS (0)); /* If need less alignment than we give anyway, just relay to malloc */ if (alignment <= MALLOC_ALIGNMENT) return public_mALLOc(bytes); /* Otherwise, ensure that it is at least a minimum chunk size */ if (alignment < MINSIZE) alignment = MINSIZE; arena_get(ar_ptr, bytes + alignment + MINSIZE); if(!ar_ptr) return 0; p = _int_memalign(ar_ptr, alignment, bytes); if(!p) { /* Maybe the failure is due to running out of mmapped areas. */ if(ar_ptr != &main_arena) { (void)mutex_unlock(&ar_ptr->mutex); ar_ptr = &main_arena; (void)mutex_lock(&ar_ptr->mutex); p = _int_memalign(ar_ptr, alignment, bytes); (void)mutex_unlock(&ar_ptr->mutex); } else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ mstate prev = ar_ptr->next ? ar_ptr : 0; (void)mutex_unlock(&ar_ptr->mutex); ar_ptr = arena_get2(prev, bytes); if(ar_ptr) { p = _int_memalign(ar_ptr, alignment, bytes); (void)mutex_unlock(&ar_ptr->mutex); } #endif } } else (void)mutex_unlock(&ar_ptr->mutex); assert(!p || chunk_is_mmapped(mem2chunk(p)) || ar_ptr == arena_for_chunk(mem2chunk(p))); return p; } #ifdef libc_hidden_def libc_hidden_def (public_mEMALIGn) #endif Void_t* public_vALLOc(size_t bytes) { mstate ar_ptr; Void_t *p; if(__malloc_initialized < 0) ptmalloc_init (); size_t pagesz = mp_.pagesize; __malloc_ptr_t (*hook) __MALLOC_PMT ((size_t, size_t, __const __malloc_ptr_t)) = force_reg (__memalign_hook); if (__builtin_expect (hook != NULL, 0)) return (*hook)(pagesz, bytes, RETURN_ADDRESS (0)); arena_get(ar_ptr, bytes + pagesz + MINSIZE); if(!ar_ptr) return 0; p = _int_valloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex); if(!p) { /* Maybe the failure is due to running out of mmapped areas. */ if(ar_ptr != &main_arena) { (void)mutex_lock(&main_arena.mutex); p = _int_memalign(&main_arena, pagesz, bytes); (void)mutex_unlock(&main_arena.mutex); } else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ ar_ptr = arena_get2(ar_ptr->next ? ar_ptr : 0, bytes); if(ar_ptr) { p = _int_memalign(ar_ptr, pagesz, bytes); (void)mutex_unlock(&ar_ptr->mutex); } #endif } } assert(!p || chunk_is_mmapped(mem2chunk(p)) || ar_ptr == arena_for_chunk(mem2chunk(p))); return p; } Void_t* public_pVALLOc(size_t bytes) { mstate ar_ptr; Void_t *p; if(__malloc_initialized < 0) ptmalloc_init (); size_t pagesz = mp_.pagesize; size_t page_mask = mp_.pagesize - 1; size_t rounded_bytes = (bytes + page_mask) & ~(page_mask); __malloc_ptr_t (*hook) __MALLOC_PMT ((size_t, size_t, __const __malloc_ptr_t)) = force_reg (__memalign_hook); if (__builtin_expect (hook != NULL, 0)) return (*hook)(pagesz, rounded_bytes, RETURN_ADDRESS (0)); arena_get(ar_ptr, bytes + 2*pagesz + MINSIZE); p = _int_pvalloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex); if(!p) { /* Maybe the failure is due to running out of mmapped areas. */ if(ar_ptr != &main_arena) { (void)mutex_lock(&main_arena.mutex); p = _int_memalign(&main_arena, pagesz, rounded_bytes); (void)mutex_unlock(&main_arena.mutex); } else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ ar_ptr = arena_get2(ar_ptr->next ? ar_ptr : 0, bytes + 2*pagesz + MINSIZE); if(ar_ptr) { p = _int_memalign(ar_ptr, pagesz, rounded_bytes); (void)mutex_unlock(&ar_ptr->mutex); } #endif } } assert(!p || chunk_is_mmapped(mem2chunk(p)) || ar_ptr == arena_for_chunk(mem2chunk(p))); return p; } Void_t* public_cALLOc(size_t n, size_t elem_size) { mstate av; mchunkptr oldtop, p; INTERNAL_SIZE_T bytes, sz, csz, oldtopsize; Void_t* mem; unsigned long clearsize; unsigned long nclears; INTERNAL_SIZE_T* d; /* size_t is unsigned so the behavior on overflow is defined. */ bytes = n * elem_size; #define HALF_INTERNAL_SIZE_T \ (((INTERNAL_SIZE_T) 1) << (8 * sizeof (INTERNAL_SIZE_T) / 2)) if (__builtin_expect ((n | elem_size) >= HALF_INTERNAL_SIZE_T, 0)) { if (elem_size != 0 && bytes / elem_size != n) { MALLOC_FAILURE_ACTION; return 0; } } __malloc_ptr_t (*hook) __MALLOC_PMT ((size_t, __const __malloc_ptr_t)) = force_reg (__malloc_hook); if (__builtin_expect (hook != NULL, 0)) { sz = bytes; mem = (*hook)(sz, RETURN_ADDRESS (0)); if(mem == 0) return 0; #ifdef HAVE_MEMCPY return memset(mem, 0, sz); #else while(sz > 0) ((char*)mem)[--sz] = 0; /* rather inefficient */ return mem; #endif } sz = bytes; arena_get(av, sz); if(!av) return 0; /* Check if we hand out the top chunk, in which case there may be no need to clear. */ #if MORECORE_CLEARS oldtop = top(av); oldtopsize = chunksize(top(av)); #if MORECORE_CLEARS < 2 /* Only newly allocated memory is guaranteed to be cleared. */ if (av == &main_arena && oldtopsize < mp_.sbrk_base + av->max_system_mem - (char *)oldtop) oldtopsize = (mp_.sbrk_base + av->max_system_mem - (char *)oldtop); #endif if (av != &main_arena) { heap_info *heap = heap_for_ptr (oldtop); if (oldtopsize < (char *) heap + heap->mprotect_size - (char *) oldtop) oldtopsize = (char *) heap + heap->mprotect_size - (char *) oldtop; } #endif mem = _int_malloc(av, sz); /* Only clearing follows, so we can unlock early. */ (void)mutex_unlock(&av->mutex); assert(!mem || chunk_is_mmapped(mem2chunk(mem)) || av == arena_for_chunk(mem2chunk(mem))); if (mem == 0) { /* Maybe the failure is due to running out of mmapped areas. */ if(av != &main_arena) { (void)mutex_lock(&main_arena.mutex); mem = _int_malloc(&main_arena, sz); (void)mutex_unlock(&main_arena.mutex); } else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ (void)mutex_lock(&main_arena.mutex); av = arena_get2(av->next ? av : 0, sz); (void)mutex_unlock(&main_arena.mutex); if(av) { mem = _int_malloc(av, sz); (void)mutex_unlock(&av->mutex); } #endif } if (mem == 0) return 0; } p = mem2chunk(mem); /* Two optional cases in which clearing not necessary */ #if HAVE_MMAP if (chunk_is_mmapped (p)) { if (__builtin_expect (perturb_byte, 0)) MALLOC_ZERO (mem, sz); return mem; } #endif csz = chunksize(p); #if MORECORE_CLEARS if (perturb_byte == 0 && (p == oldtop && csz > oldtopsize)) { /* clear only the bytes from non-freshly-sbrked memory */ csz = oldtopsize; } #endif /* Unroll clear of <= 36 bytes (72 if 8byte sizes). We know that contents have an odd number of INTERNAL_SIZE_T-sized words; minimally 3. */ d = (INTERNAL_SIZE_T*)mem; clearsize = csz - SIZE_SZ; nclears = clearsize / sizeof(INTERNAL_SIZE_T); assert(nclears >= 3); if (nclears > 9) MALLOC_ZERO(d, clearsize); else { *(d+0) = 0; *(d+1) = 0; *(d+2) = 0; if (nclears > 4) { *(d+3) = 0; *(d+4) = 0; if (nclears > 6) { *(d+5) = 0; *(d+6) = 0; if (nclears > 8) { *(d+7) = 0; *(d+8) = 0; } } } } return mem; } #ifndef _LIBC Void_t** public_iCALLOc(size_t n, size_t elem_size, Void_t** chunks) { mstate ar_ptr; Void_t** m; arena_get(ar_ptr, n*elem_size); if(!ar_ptr) return 0; m = _int_icalloc(ar_ptr, n, elem_size, chunks); (void)mutex_unlock(&ar_ptr->mutex); return m; } Void_t** public_iCOMALLOc(size_t n, size_t sizes[], Void_t** chunks) { mstate ar_ptr; Void_t** m; arena_get(ar_ptr, 0); if(!ar_ptr) return 0; m = _int_icomalloc(ar_ptr, n, sizes, chunks); (void)mutex_unlock(&ar_ptr->mutex); return m; } void public_cFREe(Void_t* m) { public_fREe(m); } #endif /* _LIBC */ int public_mTRIm(size_t s) { int result = 0; if(__malloc_initialized < 0) ptmalloc_init (); mstate ar_ptr = &main_arena; do { (void) mutex_lock (&ar_ptr->mutex); result |= mTRIm (ar_ptr, s); (void) mutex_unlock (&ar_ptr->mutex); ar_ptr = ar_ptr->next; } while (ar_ptr != &main_arena); return result; } size_t public_mUSABLe(Void_t* m) { size_t result; result = mUSABLe(m); return result; } void public_mSTATs() { mSTATs(); } struct mallinfo public_mALLINFo() { struct mallinfo m; if(__malloc_initialized < 0) ptmalloc_init (); (void)mutex_lock(&main_arena.mutex); m = mALLINFo(&main_arena); (void)mutex_unlock(&main_arena.mutex); return m; } int public_mALLOPt(int p, int v) { int result; result = mALLOPt(p, v); return result; } /* ------------------------------ malloc ------------------------------ */ static Void_t* _int_malloc(mstate av, size_t bytes) { INTERNAL_SIZE_T nb; /* normalized request size */ unsigned int idx; /* associated bin index */ mbinptr bin; /* associated bin */ mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */ mchunkptr remainder; /* remainder from a split */ unsigned long remainder_size; /* its size */ unsigned int block; /* bit map traverser */ unsigned int bit; /* bit map traverser */ unsigned int map; /* current word of binmap */ mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */ const char *errstr = NULL; /* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */ checked_request2size(bytes, nb); /* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */ if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) { idx = fastbin_index(nb); mfastbinptr* fb = &fastbin (av, idx); #ifdef ATOMIC_FASTBINS mchunkptr pp = *fb; do { victim = pp; if (victim == NULL) break; } while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) != victim); #else victim = *fb; #endif if (victim != 0) { if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) { errstr = "malloc(): memory corruption (fast)"; errout: malloc_printerr (check_action, errstr, chunk2mem (victim)); } #ifndef ATOMIC_FASTBINS *fb = victim->fd; #endif check_remalloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } /* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */ if (in_smallbin_range(nb)) { idx = smallbin_index(nb); bin = bin_at(av,idx); if ( (victim = last(bin)) != bin) { if (victim == 0) /* initialization check */ malloc_consolidate(av); else { bck = victim->bk; if (__builtin_expect (bck->fd != victim, 0)) { errstr = "malloc(): smallbin double linked list corrupted"; goto errout; } set_inuse_bit_at_offset(victim, nb); bin->bk = bck; bck->fd = bin; if (av != &main_arena) victim->size |= NON_MAIN_ARENA; check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } } /* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */ else { idx = largebin_index(nb); if (have_fastchunks(av)) malloc_consolidate(av); } /* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins. The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */ for(;;) { int iters = 0; while ( (victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) { bck = victim->bk; if (__builtin_expect (victim->size <= 2 * SIZE_SZ, 0) || __builtin_expect (victim->size > av->system_mem, 0)) malloc_printerr (check_action, "malloc(): memory corruption", chunk2mem (victim)); size = chunksize(victim); /* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */ if (in_smallbin_range(nb) && bck == unsorted_chunks(av) && victim == av->last_remainder && (unsigned long)(size) > (unsigned long)(nb + MINSIZE)) { /* split and reattach remainder */ remainder_size = size - nb; remainder = chunk_at_offset(victim, nb); unsorted_chunks(av)->bk = unsorted_chunks(av)->fd = remainder; av->last_remainder = remainder; remainder->bk = remainder->fd = unsorted_chunks(av); if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } /* remove from unsorted list */ unsorted_chunks(av)->bk = bck; bck->fd = unsorted_chunks(av); /* Take now instead of binning if exact fit */ if (size == nb) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } /* place chunk in bin */ if (in_smallbin_range(size)) { //size属于small bins victim_index = smallbin_index(size); bck = bin_at(av, victim_index); //根据victim_index查出要放入bins中的位置 fwd = bck->fd; //bck是头结点,fwd为第一个chunk } else { victim_index = largebin_index(size); //size属于large bins bck = bin_at(av, victim_index); fwd = bck->fd; /* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsigned long)(size) < (unsigned long)(bck->bk->size)) { fwd = bck; bck = bck->bk; victim->fd_nextsize = fwd->fd; victim->bk_nextsize = fwd->fd->bk_nextsize; fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; } else { assert((fwd->size & NON_MAIN_ARENA) == 0); while ((unsigned long) size < fwd->size) { fwd = fwd->fd_nextsize; assert((fwd->size & NON_MAIN_ARENA) == 0); } if ((unsigned long) size == (unsigned long) fwd->size) /* Always insert in the second position. */ fwd = fwd->fd; else { victim->fd_nextsize = fwd; victim->bk_nextsize = fwd->bk_nextsize; fwd->bk_nextsize = victim; victim->bk_nextsize->fd_nextsize = victim; } bck = fwd->bk; } } else victim->fd_nextsize = victim->bk_nextsize = victim; } mark_bin(av, victim_index); victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim; #define MAX_ITERS 10000 if (++iters >= MAX_ITERS) break; } /* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */ /* 从large bins中查找出一个 */ if (!in_smallbin_range(nb)) { bin = bin_at(av, idx); /* skip scan if empty or largest chunk is too small */ if ((victim = first(bin)) != bin && (unsigned long)(victim->size) >= (unsigned long)(nb)) { victim = victim->bk_nextsize; while (((unsigned long)(size = chunksize(victim)) < (unsigned long)(nb))) victim = victim->bk_nextsize; /* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last(bin) && victim->size == victim->fd->size) victim = victim->fd; remainder_size = size - nb; unlink(victim, bck, fwd); /* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; } /* Split */ else { remainder = chunk_at_offset(victim, nb); /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "malloc(): corrupted unsorted chunks"; goto errout; } remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } /* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */ ++idx; bin = bin_at(av,idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx); for (;;) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ( (map = av->binmap[block]) == 0); bin = bin_at(av, (block << BINMAPSHIFT)); bit = 1; } /* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin(bin); bit <<= 1; assert(bit != 0); } /* Inspect the bin. It is likely to be non-empty */ victim = last(bin); /* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1; } else { size = chunksize(victim); /* We know the first chunk in this bin is big enough to use. */ assert((unsigned long)(size) >= (unsigned long)(nb)); remainder_size = size - nb; /* unlink */ unlink(victim, bck, fwd); /* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; } /* Split */ else { remainder = chunk_at_offset(victim, nb); /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "malloc(): corrupted unsorted chunks 2"; goto errout; } remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; /* advertise as last remainder */ if (in_smallbin_range(nb)) av->last_remainder = remainder; if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */ victim = av->top; size = chunksize(victim); if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE)) { remainder_size = size - nb; remainder = chunk_at_offset(victim, nb); av->top = remainder; set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } #ifdef ATOMIC_FASTBINS /* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ else if (have_fastchunks(av)) { malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); } #else /* If there is space available in fastbins, consolidate and retry, to possibly avoid expanding memory. This can occur only if nb is in smallbin range so we didn‘t consolidate upon entry. */ else if (have_fastchunks(av)) { assert(in_smallbin_range(nb)); malloc_consolidate(av); idx = smallbin_index(nb); /* restore original bin index */ } #endif /* Otherwise, relay to handle system-dependent cases */ else { void *p = sYSMALLOc(nb, av); if (p != NULL && __builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } } /* ------------------------------ free ------------------------------ */ static void #ifdef ATOMIC_FASTBINS _int_free(mstate av, mchunkptr p, int have_lock) #else _int_free(mstate av, mchunkptr p) #endif { INTERNAL_SIZE_T size; /* its size */ mfastbinptr* fb; /* associated fastbin */ mchunkptr nextchunk; /* next contiguous chunk */ INTERNAL_SIZE_T nextsize; /* its size */ int nextinuse; /* true if nextchunk is used */ INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */ mchunkptr bck; /* misc temp for linking */ mchunkptr fwd; /* misc temp for linking */ const char *errstr = NULL; #ifdef ATOMIC_FASTBINS int locked = 0; #endif size = chunksize(p); /* Little security check which won‘t hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) { errstr = "free(): invalid pointer"; errout: #ifdef ATOMIC_FASTBINS if (! have_lock && locked) (void)mutex_unlock(&av->mutex); #endif malloc_printerr (check_action, errstr, chunk2mem(p)); return; } /* We know that each chunk is at least MINSIZE bytes in size. */ if (__builtin_expect (size < MINSIZE, 0)) { errstr = "free(): invalid size"; goto errout; } check_inuse_chunk(av, p); /* If eligible, place chunk on a fastbin so it can be found and used quickly in malloc. */ if ((unsigned long)(size) <= (unsigned long)(get_max_fast ()) #if TRIM_FASTBINS /* If TRIM_FASTBINS set, don‘t place chunks bordering top into fastbins */ && (chunk_at_offset(p, size) != av->top) #endif ) { if (__builtin_expect (chunk_at_offset (p, size)->size <= 2 * SIZE_SZ, 0) || __builtin_expect (chunksize (chunk_at_offset (p, size)) >= av->system_mem, 0)) { #ifdef ATOMIC_FASTBINS /* We might not have a lock at this point and concurrent modifications of system_mem might have let to a false positive. Redo the test after getting the lock. */ if (have_lock || ({ assert (locked == 0); mutex_lock(&av->mutex); locked = 1; chunk_at_offset (p, size)->size <= 2 * SIZE_SZ || chunksize (chunk_at_offset (p, size)) >= av->system_mem; })) #endif { errstr = "free(): invalid next size (fast)"; goto errout; } #ifdef ATOMIC_FASTBINS if (! have_lock) { (void)mutex_unlock(&av->mutex); locked = 0; } #endif } if (__builtin_expect (perturb_byte, 0)) free_perturb (chunk2mem(p), size - SIZE_SZ); set_fastchunks(av); fb = &fastbin (av, fastbin_index(size)); #ifdef ATOMIC_FASTBINS mchunkptr fd; mchunkptr old = *fb; do { /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } p->fd = fd = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, fd)) != fd); #else /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (*fb == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } p->fd = *fb; *fb = p; #endif } /* Consolidate other non-mmapped chunks as they arrive. */ else if (!chunk_is_mmapped(p)) { #ifdef ATOMIC_FASTBINS if (! have_lock) { # if THREAD_STATS if(!mutex_trylock(&av->mutex)) ++(av->stat_lock_direct); else { (void)mutex_lock(&av->mutex); ++(av->stat_lock_wait); } # else (void)mutex_lock(&av->mutex); # endif locked = 1; } #endif nextchunk = chunk_at_offset(p, size); /* Lightweight tests: check whether the block is already the top block. */ if (__builtin_expect (p == av->top, 0)) { errstr = "double free or corruption (top)"; goto errout; } /* Or whether the next chunk is beyond the boundaries of the arena. */ if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) { errstr = "double free or corruption (out)"; goto errout; } /* Or whether the block is actually not marked used. */ if (__builtin_expect (!prev_inuse(nextchunk), 0)) { errstr = "double free or corruption (!prev)"; goto errout; } nextsize = chunksize(nextchunk); if (__builtin_expect (nextchunk->size <= 2 * SIZE_SZ, 0) || __builtin_expect (nextsize >= av->system_mem, 0)) { errstr = "free(): invalid next size (normal)"; goto errout; } if (__builtin_expect (perturb_byte, 0)) free_perturb (chunk2mem(p), size - SIZE_SZ); /* consolidate backward */ if (!prev_inuse(p)) { prevsize = p->prev_size; size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); unlink(p, bck, fwd); } if (nextchunk != av->top) { /* get and clear inuse bit */ nextinuse = inuse_bit_at_offset(nextchunk, nextsize); /* consolidate forward */ if (!nextinuse) { unlink(nextchunk, bck, fwd); size += nextsize; } else clear_inuse_bit_at_offset(nextchunk, 0); /* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "free(): corrupted unsorted chunks"; goto errout; } p->fd = fwd; p->bk = bck; if (!in_smallbin_range(size)) { p->fd_nextsize = NULL; p->bk_nextsize = NULL; } bck->fd = p; fwd->bk = p; set_head(p, size | PREV_INUSE); set_foot(p, size); check_free_chunk(av, p); } /* If the chunk borders the current high end of memory, consolidate into top */ else { size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; check_chunk(av, p); } /* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top. Unless max_fast is 0, we don‘t know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don‘t want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */ if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (have_fastchunks(av)) malloc_consolidate(av); if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsigned long)(chunksize(av->top)) >= (unsigned long)(mp_.trim_threshold)) sYSTRIm(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av)); assert(heap->ar_ptr == av); heap_trim(heap, mp_.top_pad); } } #ifdef ATOMIC_FASTBINS if (! have_lock) { assert (locked); (void)mutex_unlock(&av->mutex); } #endif } /* If the chunk was allocated via mmap, release via munmap(). Note that if HAVE_MMAP is false but chunk_is_mmapped is true, then user must have overwritten memory. There‘s nothing we can do to catch this error unless MALLOC_DEBUG is set, in which case check_inuse_chunk (above) will have triggered error. */ else { #if HAVE_MMAP munmap_chunk (p); #endif } } /* ------------------------- malloc_consolidate ------------------------- malloc_consolidate is a specialized version of free() that tears down chunks held in fastbins. Free itself cannot be used for this purpose since, among other things, it might place chunks back onto fastbins. So, instead, we need to use a minor variant of the same code. Also, because this routine needs to be called the first time through malloc anyway, it turns out to be the perfect place to trigger initialization code. */ #if __STD_C static void malloc_consolidate(mstate av) #else static void malloc_consolidate(av) mstate av; #endif { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */ /* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse; mchunkptr bck; mchunkptr fwd; /* If max_fast is 0, we know that av hasn‘t yet been initialized, in which case do so below */ if (get_max_fast () != 0) { clear_fastchunks(av); unsorted_bin = unsorted_chunks(av); /* Remove each chunk from fast bin and consolidate it, placing it then in unsorted bin. Among other reasons for doing this, placing in unsorted bin avoids needing to calculate actual bins until malloc is sure that chunks aren‘t immediately going to be reused anyway. */ #if 0 /* It is wrong to limit the fast bins to search using get_max_fast because, except for the main arena, all the others might have blocks in the high fast bins. It‘s not worth it anyway, just search all bins all the time. */ maxfb = &fastbin (av, fastbin_index(get_max_fast ())); #else maxfb = &fastbin (av, NFASTBINS - 1); #endif fb = &fastbin (av, 0); do { #ifdef ATOMIC_FASTBINS p = atomic_exchange_acq (fb, 0); #else p = *fb; #endif if (p != 0) { #ifndef ATOMIC_FASTBINS *fb = 0; #endif do { check_inuse_chunk(av, p); nextp = p->fd; /* Slightly streamlined version of consolidation code in free() */ size = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk); if (!prev_inuse(p)) { prevsize = p->prev_size; size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); unlink(p, bck, fwd); } if (nextchunk != av->top) { nextinuse = inuse_bit_at_offset(nextchunk, nextsize); if (!nextinuse) { size += nextsize; unlink(nextchunk, bck, fwd); } else clear_inuse_bit_at_offset(nextchunk, 0); first_unsorted = unsorted_bin->fd; unsorted_bin->fd = p; first_unsorted->bk = p; if (!in_smallbin_range (size)) { p->fd_nextsize = NULL; p->bk_nextsize = NULL; } set_head(p, size | PREV_INUSE); p->bk = unsorted_bin; p->fd = first_unsorted; set_foot(p, size); } else { size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; } } while ( (p = nextp) != 0); } } while (fb++ != maxfb); } else { malloc_init_state(av); check_malloc_state(av); } } /* ------------------------------ realloc ------------------------------ */ Void_t* _int_realloc(mstate av, mchunkptr oldp, INTERNAL_SIZE_T oldsize, INTERNAL_SIZE_T nb) { mchunkptr newp; /* chunk to return */ INTERNAL_SIZE_T newsize; /* its size */ Void_t* newmem; /* corresponding user mem */ mchunkptr next; /* next contiguous chunk after oldp */ mchunkptr remainder; /* extra space at end of newp */ unsigned long remainder_size; /* its size */ mchunkptr bck; /* misc temp for linking */ mchunkptr fwd; /* misc temp for linking */ unsigned long copysize; /* bytes to copy */ unsigned int ncopies; /* INTERNAL_SIZE_T words to copy */ INTERNAL_SIZE_T* s; /* copy source */ INTERNAL_SIZE_T* d; /* copy destination */ const char *errstr = NULL; /* oldmem size */ if (__builtin_expect (oldp->size <= 2 * SIZE_SZ, 0) || __builtin_expect (oldsize >= av->system_mem, 0)) { errstr = "realloc(): invalid old size"; errout: malloc_printerr (check_action, errstr, chunk2mem(oldp)); return NULL; } check_inuse_chunk(av, oldp); /* All callers already filter out mmap‘ed chunks. */ #if 0 if (!chunk_is_mmapped(oldp)) #else assert (!chunk_is_mmapped(oldp)); #endif { next = chunk_at_offset(oldp, oldsize); INTERNAL_SIZE_T nextsize = chunksize(next); if (__builtin_expect (next->size <= 2 * SIZE_SZ, 0) || __builtin_expect (nextsize >= av->system_mem, 0)) { errstr = "realloc(): invalid next size"; goto errout; } if ((unsigned long)(oldsize) >= (unsigned long)(nb)) { /* already big enough; split below */ newp = oldp; newsize = oldsize; } else { /* Try to expand forward into top */ if (next == av->top && (unsigned long)(newsize = oldsize + nextsize) >= (unsigned long)(nb + MINSIZE)) { set_head_size(oldp, nb | (av != &main_arena ? NON_MAIN_ARENA : 0)); av->top = chunk_at_offset(oldp, nb); set_head(av->top, (newsize - nb) | PREV_INUSE); check_inuse_chunk(av, oldp); return chunk2mem(oldp); } /* Try to expand forward into next chunk; split off remainder below */ else if (next != av->top && !inuse(next) && (unsigned long)(newsize = oldsize + nextsize) >= (unsigned long)(nb)) { newp = oldp; unlink(next, bck, fwd); } /* allocate, copy, free */ else { newmem = _int_malloc(av, nb - MALLOC_ALIGN_MASK); if (newmem == 0) return 0; /* propagate failure */ newp = mem2chunk(newmem); newsize = chunksize(newp); /* Avoid copy if newp is next chunk after oldp. */ if (newp == next) { newsize += oldsize; newp = oldp; } else { /* Unroll copy of <= 36 bytes (72 if 8byte sizes) We know that contents have an odd number of INTERNAL_SIZE_T-sized words; minimally 3. */ copysize = oldsize - SIZE_SZ; s = (INTERNAL_SIZE_T*)(chunk2mem(oldp)); d = (INTERNAL_SIZE_T*)(newmem); ncopies = copysize / sizeof(INTERNAL_SIZE_T); assert(ncopies >= 3); if (ncopies > 9) MALLOC_COPY(d, s, copysize); else { *(d+0) = *(s+0); *(d+1) = *(s+1); *(d+2) = *(s+2); if (ncopies > 4) { *(d+3) = *(s+3); *(d+4) = *(s+4); if (ncopies > 6) { *(d+5) = *(s+5); *(d+6) = *(s+6); if (ncopies > 8) { *(d+7) = *(s+7); *(d+8) = *(s+8); } } } } #ifdef ATOMIC_FASTBINS _int_free(av, oldp, 1); #else _int_free(av, oldp); #endif check_inuse_chunk(av, newp); return chunk2mem(newp); } } } /* If possible, free extra space in old or extended chunk */ assert((unsigned long)(newsize) >= (unsigned long)(nb)); remainder_size = newsize - nb; if (remainder_size < MINSIZE) { /* not enough extra to split off */ set_head_size(newp, newsize | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_inuse_bit_at_offset(newp, newsize); } else { /* split remainder */ remainder = chunk_at_offset(newp, nb); set_head_size(newp, nb | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); /* Mark remainder as inuse so free() won‘t complain */ set_inuse_bit_at_offset(remainder, remainder_size); #ifdef ATOMIC_FASTBINS _int_free(av, remainder, 1); #else _int_free(av, remainder); #endif } check_inuse_chunk(av, newp); return chunk2mem(newp); } #if 0 /* Handle mmap cases */ else { #if HAVE_MMAP #if HAVE_MREMAP INTERNAL_SIZE_T offset = oldp->prev_size; size_t pagemask = mp_.pagesize - 1; char *cp; unsigned long sum; /* Note the extra SIZE_SZ overhead */ newsize = (nb + offset + SIZE_SZ + pagemask) & ~pagemask; /* don‘t need to remap if still within same page */ if (oldsize == newsize - offset) return chunk2mem(oldp); cp = (char*)mremap((char*)oldp - offset, oldsize + offset, newsize, 1); if (cp != MAP_FAILED) { newp = (mchunkptr)(cp + offset); set_head(newp, (newsize - offset)|IS_MMAPPED); assert(aligned_OK(chunk2mem(newp))); assert((newp->prev_size == offset)); /* update statistics */ sum = mp_.mmapped_mem += newsize - oldsize; if (sum > (unsigned long)(mp_.max_mmapped_mem)) mp_.max_mmapped_mem = sum; #ifdef NO_THREADS sum += main_arena.system_mem; if (sum > (unsigned long)(mp_.max_total_mem)) mp_.max_total_mem = sum; #endif return chunk2mem(newp); } #endif /* Note the extra SIZE_SZ overhead. */ if ((unsigned long)(oldsize) >= (unsigned long)(nb + SIZE_SZ)) newmem = chunk2mem(oldp); /* do nothing */ else { /* Must alloc, copy, free. */ newmem = _int_malloc(av, nb - MALLOC_ALIGN_MASK); if (newmem != 0) { MALLOC_COPY(newmem, chunk2mem(oldp), oldsize - 2*SIZE_SZ); #ifdef ATOMIC_FASTBINS _int_free(av, oldp, 1); #else _int_free(av, oldp); #endif } } return newmem; #else /* If !HAVE_MMAP, but chunk_is_mmapped, user must have overwritten mem */ check_malloc_state(av); MALLOC_FAILURE_ACTION; return 0; #endif } #endif } /* ------------------------------ memalign ------------------------------ */ static Void_t* _int_memalign(mstate av, size_t alignment, size_t bytes) { INTERNAL_SIZE_T nb; /* padded request size */ char* m; /* memory returned by malloc call */ mchunkptr p; /* corresponding chunk */ char* brk; /* alignment point within p */ mchunkptr newp; /* chunk to return */ INTERNAL_SIZE_T newsize; /* its size */ INTERNAL_SIZE_T leadsize; /* leading space before alignment point */ mchunkptr remainder; /* spare room at end to split off */ unsigned long remainder_size; /* its size */ INTERNAL_SIZE_T size; /* If need less alignment than we give anyway, just relay to malloc */ if (alignment <= MALLOC_ALIGNMENT) return _int_malloc(av, bytes); /* Otherwise, ensure that it is at least a minimum chunk size */ if (alignment < MINSIZE) alignment = MINSIZE; /* Make sure alignment is power of 2 (in case MINSIZE is not). */ if ((alignment & (alignment - 1)) != 0) { size_t a = MALLOC_ALIGNMENT * 2; while ((unsigned long)a < (unsigned long)alignment) a <<= 1; alignment = a; } checked_request2size(bytes, nb); /* Strategy: find a spot within that chunk that meets the alignment request, and then possibly free the leading and trailing space. */ /* Call malloc with worst case padding to hit alignment. */ m = (char*)(_int_malloc(av, nb + alignment + MINSIZE)); if (m == 0) return 0; /* propagate failure */ p = mem2chunk(m); if ((((unsigned long)(m)) % alignment) != 0) { /* misaligned */ /* Find an aligned spot inside chunk. Since we need to give back leading space in a chunk of at least MINSIZE, if the first calculation places us at a spot with less than MINSIZE leader, we can move to the next aligned spot -- we‘ve allocated enough total room so that this is always possible. */ brk = (char*)mem2chunk(((unsigned long)(m + alignment - 1)) & -((signed long) alignment)); if ((unsigned long)(brk - (char*)(p)) < MINSIZE) brk += alignment; newp = (mchunkptr)brk; leadsize = brk - (char*)(p); newsize = chunksize(p) - leadsize; /* For mmapped chunks, just adjust offset */ if (chunk_is_mmapped(p)) { newp->prev_size = p->prev_size + leadsize; set_head(newp, newsize|IS_MMAPPED); return chunk2mem(newp); } /* Otherwise, give back leader, use the rest */ set_head(newp, newsize | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_inuse_bit_at_offset(newp, newsize); set_head_size(p, leadsize | (av != &main_arena ? NON_MAIN_ARENA : 0)); #ifdef ATOMIC_FASTBINS _int_free(av, p, 1); #else _int_free(av, p); #endif p = newp; assert (newsize >= nb && (((unsigned long)(chunk2mem(p))) % alignment) == 0); } /* Also give back spare room at the end */ if (!chunk_is_mmapped(p)) { size = chunksize(p); if ((unsigned long)(size) > (unsigned long)(nb + MINSIZE)) { remainder_size = size - nb; remainder = chunk_at_offset(p, nb); set_head(remainder, remainder_size | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head_size(p, nb); #ifdef ATOMIC_FASTBINS _int_free(av, remainder, 1); #else _int_free(av, remainder); #endif } } check_inuse_chunk(av, p); return chunk2mem(p); } #if 0 /* ------------------------------ calloc ------------------------------ */ #if __STD_C Void_t* cALLOc(size_t n_elements, size_t elem_size) #else Void_t* cALLOc(n_elements, elem_size) size_t n_elements; size_t elem_size; #endif { mchunkptr p; unsigned long clearsize; unsigned long nclears; INTERNAL_SIZE_T* d; Void_t* mem = mALLOc(n_elements * elem_size); if (mem != 0) { p = mem2chunk(mem); #if MMAP_CLEARS if (!chunk_is_mmapped(p)) /* don‘t need to clear mmapped space */ #endif { /* Unroll clear of <= 36 bytes (72 if 8byte sizes) We know that contents have an odd number of INTERNAL_SIZE_T-sized words; minimally 3. */ d = (INTERNAL_SIZE_T*)mem; clearsize = chunksize(p) - SIZE_SZ; nclears = clearsize / sizeof(INTERNAL_SIZE_T); assert(nclears >= 3); if (nclears > 9) MALLOC_ZERO(d, clearsize); else { *(d+0) = 0; *(d+1) = 0; *(d+2) = 0; if (nclears > 4) { *(d+3) = 0; *(d+4) = 0; if (nclears > 6) { *(d+5) = 0; *(d+6) = 0; if (nclears > 8) { *(d+7) = 0; *(d+8) = 0; } } } } } } return mem; } #endif /* 0 */ #ifndef _LIBC /* ------------------------- independent_calloc ------------------------- */ Void_t** #if __STD_C _int_icalloc(mstate av, size_t n_elements, size_t elem_size, Void_t* chunks[]) #else _int_icalloc(av, n_elements, elem_size, chunks) mstate av; size_t n_elements; size_t elem_size; Void_t* chunks[]; #endif { size_t sz = elem_size; /* serves as 1-element array */ /* opts arg of 3 means all elements are same size, and should be cleared */ return iALLOc(av, n_elements, &sz, 3, chunks); } /* ------------------------- independent_comalloc ------------------------- */ Void_t** #if __STD_C _int_icomalloc(mstate av, size_t n_elements, size_t sizes[], Void_t* chunks[]) #else _int_icomalloc(av, n_elements, sizes, chunks) mstate av; size_t n_elements; size_t sizes[]; Void_t* chunks[]; #endif { return iALLOc(av, n_elements, sizes, 0, chunks); } /* ------------------------------ ialloc ------------------------------ ialloc provides common support for independent_X routines, handling all of the combinations that can result. The opts arg has: bit 0 set if all elements are same size (using sizes[0]) bit 1 set if elements should be zeroed */ static Void_t** #if __STD_C iALLOc(mstate av, size_t n_elements, size_t* sizes, int opts, Void_t* chunks[]) #else iALLOc(av, n_elements, sizes, opts, chunks) mstate av; size_t n_elements; size_t* sizes; int opts; Void_t* chunks[]; #endif { INTERNAL_SIZE_T element_size; /* chunksize of each element, if all same */ INTERNAL_SIZE_T contents_size; /* total size of elements */ INTERNAL_SIZE_T array_size; /* request size of pointer array */ Void_t* mem; /* malloced aggregate space */ mchunkptr p; /* corresponding chunk */ INTERNAL_SIZE_T remainder_size; /* remaining bytes while splitting */ Void_t** marray; /* either "chunks" or malloced ptr array */ mchunkptr array_chunk; /* chunk for malloced ptr array */ int mmx; /* to disable mmap */ INTERNAL_SIZE_T size; INTERNAL_SIZE_T size_flags; size_t i; /* Ensure initialization/consolidation */ if (have_fastchunks(av)) malloc_consolidate(av); /* compute array length, if needed */ if (chunks != 0) { if (n_elements == 0) return chunks; /* nothing to do */ marray = chunks; array_size = 0; } else { /* if empty req, must still return chunk representing empty array */ if (n_elements == 0) return (Void_t**) _int_malloc(av, 0); marray = 0; array_size = request2size(n_elements * (sizeof(Void_t*))); } /* compute total element size */ if (opts & 0x1) { /* all-same-size */ element_size = request2size(*sizes); contents_size = n_elements * element_size; } else { /* add up all the sizes */ element_size = 0; contents_size = 0; for (i = 0; i != n_elements; ++i) contents_size += request2size(sizes[i]); } /* subtract out alignment bytes from total to minimize overallocation */ size = contents_size + array_size - MALLOC_ALIGN_MASK; /* Allocate the aggregate chunk. But first disable mmap so malloc won‘t use it, since we would not be able to later free/realloc space internal to a segregated mmap region. */ mmx = mp_.n_mmaps_max; /* disable mmap */ mp_.n_mmaps_max = 0; mem = _int_malloc(av, size); mp_.n_mmaps_max = mmx; /* reset mmap */ if (mem == 0) return 0; p = mem2chunk(mem); assert(!chunk_is_mmapped(p)); remainder_size = chunksize(p); if (opts & 0x2) { /* optionally clear the elements */ MALLOC_ZERO(mem, remainder_size - SIZE_SZ - array_size); } size_flags = PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0); /* If not provided, allocate the pointer array as final part of chunk */ if (marray == 0) { array_chunk = chunk_at_offset(p, contents_size); marray = (Void_t**) (chunk2mem(array_chunk)); set_head(array_chunk, (remainder_size - contents_size) | size_flags); remainder_size = contents_size; } /* split out elements */ for (i = 0; ; ++i) { marray[i] = chunk2mem(p); if (i != n_elements-1) { if (element_size != 0) size = element_size; else size = request2size(sizes[i]); remainder_size -= size; set_head(p, size | size_flags); p = chunk_at_offset(p, size); } else { /* the final element absorbs any overallocation slop */ set_head(p, remainder_size | size_flags); break; } } #if MALLOC_DEBUG if (marray != chunks) { /* final element must have exactly exhausted chunk */ if (element_size != 0) assert(remainder_size == element_size); else assert(remainder_size == request2size(sizes[i])); check_inuse_chunk(av, mem2chunk(marray)); } for (i = 0; i != n_elements; ++i) check_inuse_chunk(av, mem2chunk(marray[i])); #endif return marray; } #endif /* _LIBC */ /* ------------------------------ valloc ------------------------------ */ static Void_t* #if __STD_C _int_valloc(mstate av, size_t bytes) #else _int_valloc(av, bytes) mstate av; size_t bytes; #endif { /* Ensure initialization/consolidation */ if (have_fastchunks(av)) malloc_consolidate(av); return _int_memalign(av, mp_.pagesize, bytes); } /* ------------------------------ pvalloc ------------------------------ */ static Void_t* #if __STD_C _int_pvalloc(mstate av, size_t bytes) #else _int_pvalloc(av, bytes) mstate av, size_t bytes; #endif { size_t pagesz; /* Ensure initialization/consolidation */ if (have_fastchunks(av)) malloc_consolidate(av); pagesz = mp_.pagesize; return _int_memalign(av, pagesz, (bytes + pagesz - 1) & ~(pagesz - 1)); } /* ------------------------------ malloc_trim ------------------------------ */ #if __STD_C static int mTRIm(mstate av, size_t pad) #else static int mTRIm(av, pad) mstate av; size_t pad; #endif { /* Ensure initialization/consolidation */ malloc_consolidate (av); const size_t ps = mp_.pagesize; int psindex = bin_index (ps); const size_t psm1 = ps - 1; int result = 0; for (int i = 1; i < NBINS; ++i) if (i == 1 || i >= psindex) { mbinptr bin = bin_at (av, i); for (mchunkptr p = last (bin); p != bin; p = p->bk) { INTERNAL_SIZE_T size = chunksize (p); if (size > psm1 + sizeof (struct malloc_chunk)) { /* See whether the chunk contains at least one unused page. */ char *paligned_mem = (char *) (((uintptr_t) p + sizeof (struct malloc_chunk) + psm1) & ~psm1); assert ((char *) chunk2mem (p) + 4 * SIZE_SZ <= paligned_mem); assert ((char *) p + size > paligned_mem); /* This is the size we could potentially free. */ size -= paligned_mem - (char *) p; if (size > psm1) { #ifdef MALLOC_DEBUG /* When debugging we simulate destroying the memory content. */ memset (paligned_mem, 0x89, size & ~psm1); #endif madvise (paligned_mem, size & ~psm1, MADV_DONTNEED); result = 1; } } } } #ifndef MORECORE_CANNOT_TRIM return result | (av == &main_arena ? sYSTRIm (pad, av) : 0); #else return result; #endif } /* ------------------------- malloc_usable_size ------------------------- */ #if __STD_C size_t mUSABLe(Void_t* mem) #else size_t mUSABLe(mem) Void_t* mem; #endif { mchunkptr p; if (mem != 0) { p = mem2chunk(mem); if (chunk_is_mmapped(p)) return chunksize(p) - 2*SIZE_SZ; else if (inuse(p)) return chunksize(p) - SIZE_SZ; } return 0; } /* ------------------------------ mallinfo ------------------------------ */ struct mallinfo mALLINFo(mstate av) { struct mallinfo mi; size_t i; mbinptr b; mchunkptr p; INTERNAL_SIZE_T avail; INTERNAL_SIZE_T fastavail; int nblocks; int nfastblocks; /* Ensure initialization */ if (av->top == 0) malloc_consolidate(av); check_malloc_state(av); /* Account for top */ avail = chunksize(av->top); nblocks = 1; /* top always exists */ /* traverse fastbins */ nfastblocks = 0; fastavail = 0; for (i = 0; i < NFASTBINS; ++i) { for (p = fastbin (av, i); p != 0; p = p->fd) { ++nfastblocks; fastavail += chunksize(p); } } avail += fastavail; /* traverse regular bins */ for (i = 1; i < NBINS; ++i) { b = bin_at(av, i); for (p = last(b); p != b; p = p->bk) { ++nblocks; avail += chunksize(p); } } mi.smblks = nfastblocks; mi.ordblks = nblocks; mi.fordblks = avail; mi.uordblks = av->system_mem - avail; mi.arena = av->system_mem; mi.hblks = mp_.n_mmaps; mi.hblkhd = mp_.mmapped_mem; mi.fsmblks = fastavail; mi.keepcost = chunksize(av->top); mi.usmblks = mp_.max_total_mem; return mi; } /* ------------------------------ malloc_stats ------------------------------ */ void mSTATs() { int i; mstate ar_ptr; struct mallinfo mi; unsigned int in_use_b = mp_.mmapped_mem, system_b = in_use_b; #if THREAD_STATS long stat_lock_direct = 0, stat_lock_loop = 0, stat_lock_wait = 0; #endif if(__malloc_initialized < 0) ptmalloc_init (); #ifdef _LIBC _IO_flockfile (stderr); int old_flags2 = ((_IO_FILE *) stderr)->_flags2; ((_IO_FILE *) stderr)->_flags2 |= _IO_FLAGS2_NOTCANCEL; #endif for (i=0, ar_ptr = &main_arena;; i++) { (void)mutex_lock(&ar_ptr->mutex); mi = mALLINFo(ar_ptr); fprintf(stderr, "Arena %d:\n", i); fprintf(stderr, "system bytes = %10u\n", (unsigned int)mi.arena); fprintf(stderr, "in use bytes = %10u\n", (unsigned int)mi.uordblks); #if MALLOC_DEBUG > 1 if (i > 0) dump_heap(heap_for_ptr(top(ar_ptr))); #endif system_b += mi.arena; in_use_b += mi.uordblks; #if THREAD_STATS stat_lock_direct += ar_ptr->stat_lock_direct; stat_lock_loop += ar_ptr->stat_lock_loop; stat_lock_wait += ar_ptr->stat_lock_wait; #endif (void)mutex_unlock(&ar_ptr->mutex); ar_ptr = ar_ptr->next; if(ar_ptr == &main_arena) break; } #if HAVE_MMAP fprintf(stderr, "Total (incl. mmap):\n"); #else fprintf(stderr, "Total:\n"); #endif fprintf(stderr, "system bytes = %10u\n", system_b); fprintf(stderr, "in use bytes = %10u\n", in_use_b); #ifdef NO_THREADS fprintf(stderr, "max system bytes = %10u\n", (unsigned int)mp_.max_total_mem); #endif #if HAVE_MMAP fprintf(stderr, "max mmap regions = %10u\n", (unsigned int)mp_.max_n_mmaps); fprintf(stderr, "max mmap bytes = %10lu\n", (unsigned long)mp_.max_mmapped_mem); #endif #if THREAD_STATS fprintf(stderr, "heaps created = %10d\n", stat_n_heaps); fprintf(stderr, "locked directly = %10ld\n", stat_lock_direct); fprintf(stderr, "locked in loop = %10ld\n", stat_lock_loop); fprintf(stderr, "locked waiting = %10ld\n", stat_lock_wait); fprintf(stderr, "locked total = %10ld\n", stat_lock_direct + stat_lock_loop + stat_lock_wait); #endif #ifdef _LIBC ((_IO_FILE *) stderr)->_flags2 |= old_flags2; _IO_funlockfile (stderr); #endif } /* ------------------------------ mallopt ------------------------------ */ #if __STD_C int mALLOPt(int param_number, int value) #else int mALLOPt(param_number, value) int param_number; int value; #endif { mstate av = &main_arena; int res = 1; if(__malloc_initialized < 0) ptmalloc_init (); (void)mutex_lock(&av->mutex); /* Ensure initialization/consolidation */ malloc_consolidate(av); switch(param_number) { case M_MXFAST: if (value >= 0 && value <= MAX_FAST_SIZE) { set_max_fast(value); } else res = 0; break; case M_TRIM_THRESHOLD: mp_.trim_threshold = value; mp_.no_dyn_threshold = 1; break; case M_TOP_PAD: mp_.top_pad = value; mp_.no_dyn_threshold = 1; break; case M_MMAP_THRESHOLD: #if USE_ARENAS /* Forbid setting the threshold too high. */ if((unsigned long)value > HEAP_MAX_SIZE/2) res = 0; else #endif mp_.mmap_threshold = value; mp_.no_dyn_threshold = 1; break; case M_MMAP_MAX: #if !HAVE_MMAP if (value != 0) res = 0; else #endif mp_.n_mmaps_max = value; mp_.no_dyn_threshold = 1; break; case M_CHECK_ACTION: check_action = value; break; case M_PERTURB: perturb_byte = value; break; #ifdef PER_THREAD case M_ARENA_TEST: if (value > 0) mp_.arena_test = value; break; case M_ARENA_MAX: if (value > 0) mp_.arena_max = value; break; #endif } (void)mutex_unlock(&av->mutex); return res; } /* -------------------- Alternative MORECORE functions -------------------- */ /* General Requirements for MORECORE. The MORECORE function must have the following properties: If MORECORE_CONTIGUOUS is false: * MORECORE must allocate in multiples of pagesize. It will only be called with arguments that are multiples of pagesize. * MORECORE(0) must return an address that is at least MALLOC_ALIGNMENT aligned. (Page-aligning always suffices.) else (i.e. If MORECORE_CONTIGUOUS is true): * Consecutive calls to MORECORE with positive arguments return increasing addresses, indicating that space has been contiguously extended. * MORECORE need not allocate in multiples of pagesize. Calls to MORECORE need not have args of multiples of pagesize. * MORECORE need not page-align. In either case: * MORECORE may allocate more memory than requested. (Or even less, but this will generally result in a malloc failure.) * MORECORE must not allocate memory when given argument zero, but instead return one past the end address of memory from previous nonzero call. This malloc does NOT call MORECORE(0) until at least one call with positive arguments is made, so the initial value returned is not important. * Even though consecutive calls to MORECORE need not return contiguous addresses, it must be OK for malloc‘ed chunks to span multiple regions in those cases where they do happen to be contiguous. * MORECORE need not handle negative arguments -- it may instead just return MORECORE_FAILURE when given negative arguments. Negative arguments are always multiples of pagesize. MORECORE must not misinterpret negative args as large positive unsigned args. You can suppress all such calls from even occurring by defining MORECORE_CANNOT_TRIM, There is some variation across systems about the type of the argument to sbrk/MORECORE. If size_t is unsigned, then it cannot actually be size_t, because sbrk supports negative args, so it is normally the signed type of the same width as size_t (sometimes declared as "intptr_t", and sometimes "ptrdiff_t"). It doesn‘t much matter though. Internally, we use "long" as arguments, which should work across all reasonable possibilities. Additionally, if MORECORE ever returns failure for a positive request, and HAVE_MMAP is true, then mmap is used as a noncontiguous system allocator. This is a useful backup strategy for systems with holes in address spaces -- in this case sbrk cannot contiguously expand the heap, but mmap may be able to map noncontiguous space. If you‘d like mmap to ALWAYS be used, you can define MORECORE to be a function that always returns MORECORE_FAILURE. If you are using this malloc with something other than sbrk (or its emulation) to supply memory regions, you probably want to set MORECORE_CONTIGUOUS as false. As an example, here is a custom allocator kindly contributed for pre-OSX macOS. It uses virtually but not necessarily physically contiguous non-paged memory (locked in, present and won‘t get swapped out). You can use it by uncommenting this section, adding some #includes, and setting up the appropriate defines above: #define MORECORE osMoreCore #define MORECORE_CONTIGUOUS 0 There is also a shutdown routine that should somehow be called for cleanup upon program exit. #define MAX_POOL_ENTRIES 100 #define MINIMUM_MORECORE_SIZE (64 * 1024) static int next_os_pool; void *our_os_pools[MAX_POOL_ENTRIES]; void *osMoreCore(int size) { void *ptr = 0; static void *sbrk_top = 0; if (size > 0) { if (size < MINIMUM_MORECORE_SIZE) size = MINIMUM_MORECORE_SIZE; if (CurrentExecutionLevel() == kTaskLevel) ptr = PoolAllocateResident(size + RM_PAGE_SIZE, 0); if (ptr == 0) { return (void *) MORECORE_FAILURE; } // save ptrs so they can be freed during cleanup our_os_pools[next_os_pool] = ptr; next_os_pool++; ptr = (void *) ((((unsigned long) ptr) + RM_PAGE_MASK) & ~RM_PAGE_MASK); sbrk_top = (char *) ptr + size; return ptr; } else if (size < 0) { // we don‘t currently support shrink behavior return (void *) MORECORE_FAILURE; } else { return sbrk_top; } } // cleanup any allocated memory pools // called as last thing before shutting down driver void osCleanupMem(void) { void **ptr; for (ptr = our_os_pools; ptr < &our_os_pools[MAX_POOL_ENTRIES]; ptr++) if (*ptr) { PoolDeallocate(*ptr); *ptr = 0; } } */ /* Helper code. */ extern char **__libc_argv attribute_hidden; static void malloc_printerr(int action, const char *str, void *ptr) { if ((action & 5) == 5) __libc_message (action & 2, "%s\n", str); else if (action & 1) { char buf[2 * sizeof (uintptr_t) + 1]; buf[sizeof (buf) - 1] = ‘\0‘; char *cp = _itoa_word ((uintptr_t) ptr, &buf[sizeof (buf) - 1], 16, 0); while (cp > buf) *--cp = ‘0‘; __libc_message (action & 2, "*** glibc detected *** %s: %s: 0x%s ***\n", __libc_argv[0] ?: "<unknown>", str, cp); } else if (action & 2) abort (); } #ifdef _LIBC # include <sys/param.h> /* We need a wrapper function for one of the additions of POSIX. */ int __posix_memalign (void **memptr, size_t alignment, size_t size) { void *mem; /* Test whether the SIZE argument is valid. It must be a power of two multiple of sizeof (void *). */ if (alignment % sizeof (void *) != 0 || !powerof2 (alignment / sizeof (void *)) != 0 || alignment == 0) return EINVAL; /* Call the hook here, so that caller is posix_memalign‘s caller and not posix_memalign itself. */ __malloc_ptr_t (*hook) __MALLOC_PMT ((size_t, size_t, __const __malloc_ptr_t)) = force_reg (__memalign_hook); if (__builtin_expect (hook != NULL, 0)) mem = (*hook)(alignment, size, RETURN_ADDRESS (0)); else mem = public_mEMALIGn (alignment, size); if (mem != NULL) { *memptr = mem; return 0; } return ENOMEM; } weak_alias (__posix_memalign, posix_memalign) int malloc_info (int options, FILE *fp) { /* For now, at least. */ if (options != 0) return EINVAL; int n = 0; size_t total_nblocks = 0; size_t total_nfastblocks = 0; size_t total_avail = 0; size_t total_fastavail = 0; size_t total_system = 0; size_t total_max_system = 0; size_t total_aspace = 0; size_t total_aspace_mprotect = 0; void mi_arena (mstate ar_ptr) { fprintf (fp, "<heap nr=\"%d\">\n<sizes>\n", n++); size_t nblocks = 0; size_t nfastblocks = 0; size_t avail = 0; size_t fastavail = 0; struct { size_t from; size_t to; size_t total; size_t count; } sizes[NFASTBINS + NBINS - 1]; #define nsizes (sizeof (sizes) / sizeof (sizes[0])) mutex_lock (&ar_ptr->mutex); for (size_t i = 0; i < NFASTBINS; ++i) { mchunkptr p = fastbin (ar_ptr, i); if (p != NULL) { size_t nthissize = 0; size_t thissize = chunksize (p); while (p != NULL) { ++nthissize; p = p->fd; } fastavail += nthissize * thissize; nfastblocks += nthissize; sizes[i].from = thissize - (MALLOC_ALIGNMENT - 1); sizes[i].to = thissize; sizes[i].count = nthissize; } else sizes[i].from = sizes[i].to = sizes[i].count = 0; sizes[i].total = sizes[i].count * sizes[i].to; } mbinptr bin = bin_at (ar_ptr, 1); struct malloc_chunk *r = bin->fd; while (r != bin) { ++sizes[NFASTBINS].count; sizes[NFASTBINS].total += r->size; sizes[NFASTBINS].from = MIN (sizes[NFASTBINS].from, r->size); sizes[NFASTBINS].to = MAX (sizes[NFASTBINS].to, r->size); r = r->fd; } nblocks += sizes[NFASTBINS].count; avail += sizes[NFASTBINS].total; for (size_t i = 2; i < NBINS; ++i) { bin = bin_at (ar_ptr, i); r = bin->fd; sizes[NFASTBINS - 1 + i].from = ~((size_t) 0); sizes[NFASTBINS - 1 + i].to = sizes[NFASTBINS - 1 + i].total = sizes[NFASTBINS - 1 + i].count = 0; while (r != bin) { ++sizes[NFASTBINS - 1 + i].count; sizes[NFASTBINS - 1 + i].total += r->size; sizes[NFASTBINS - 1 + i].from = MIN (sizes[NFASTBINS - 1 + i].from, r->size); sizes[NFASTBINS - 1 + i].to = MAX (sizes[NFASTBINS - 1 + i].to, r->size); r = r->fd; } if (sizes[NFASTBINS - 1 + i].count == 0) sizes[NFASTBINS - 1 + i].from = 0; nblocks += sizes[NFASTBINS - 1 + i].count; avail += sizes[NFASTBINS - 1 + i].total; } mutex_unlock (&ar_ptr->mutex); total_nfastblocks += nfastblocks; total_fastavail += fastavail; total_nblocks += nblocks; total_avail += avail; for (size_t i = 0; i < nsizes; ++i) if (sizes[i].count != 0 && i != NFASTBINS) fprintf (fp, "\ <size from=\"%zu\" to=\"%zu\" total=\"%zu\" count=\"%zu\"/>\n", sizes[i].from, sizes[i].to, sizes[i].total, sizes[i].count); if (sizes[NFASTBINS].count != 0) fprintf (fp, "\ <unsorted from=\"%zu\" to=\"%zu\" total=\"%zu\" count=\"%zu\"/>\n", sizes[NFASTBINS].from, sizes[NFASTBINS].to, sizes[NFASTBINS].total, sizes[NFASTBINS].count); total_system += ar_ptr->system_mem; total_max_system += ar_ptr->max_system_mem; fprintf (fp, "</sizes>\n<total type=\"fast\" count=\"%zu\" size=\"%zu\"/>\n" "<total type=\"rest\" count=\"%zu\" size=\"%zu\"/>\n" "<system type=\"current\" size=\"%zu\"/>\n" "<system type=\"max\" size=\"%zu\"/>\n", nfastblocks, fastavail, nblocks, avail, ar_ptr->system_mem, ar_ptr->max_system_mem); if (ar_ptr != &main_arena) { heap_info *heap = heap_for_ptr(top(ar_ptr)); fprintf (fp, "<aspace type=\"total\" size=\"%zu\"/>\n" "<aspace type=\"mprotect\" size=\"%zu\"/>\n", heap->size, heap->mprotect_size); total_aspace += heap->size; total_aspace_mprotect += heap->mprotect_size; } else { fprintf (fp, "<aspace type=\"total\" size=\"%zu\"/>\n" "<aspace type=\"mprotect\" size=\"%zu\"/>\n", ar_ptr->system_mem, ar_ptr->system_mem); total_aspace += ar_ptr->system_mem; total_aspace_mprotect += ar_ptr->system_mem; } fputs ("</heap>\n", fp); } fputs ("<malloc version=\"1\">\n", fp); /* Iterate over all arenas currently in use. */ mstate ar_ptr = &main_arena; do { mi_arena (ar_ptr); ar_ptr = ar_ptr->next; } while (ar_ptr != &main_arena); fprintf (fp, "<total type=\"fast\" count=\"%zu\" size=\"%zu\"/>\n" "<total type=\"rest\" count=\"%zu\" size=\"%zu\"/>\n" "<system type=\"current\" size=\"%zu\"/>\n" "<system type=\"max\" size=\"%zu\"/>\n" "<aspace type=\"total\" size=\"%zu\"/>\n" "<aspace type=\"mprotect\" size=\"%zu\"/>\n" "</malloc>\n", total_nfastblocks, total_fastavail, total_nblocks, total_avail, total_system, total_max_system, total_aspace, total_aspace_mprotect); return 0; } strong_alias (__libc_calloc, __calloc) weak_alias (__libc_calloc, calloc) strong_alias (__libc_free, __cfree) weak_alias (__libc_free, cfree) strong_alias (__libc_free, __free) strong_alias (__libc_free, free) strong_alias (__libc_malloc, __malloc) strong_alias (__libc_malloc, malloc) strong_alias (__libc_memalign, __memalign) weak_alias (__libc_memalign, memalign) strong_alias (__libc_realloc, __realloc) strong_alias (__libc_realloc, realloc) strong_alias (__libc_valloc, __valloc) weak_alias (__libc_valloc, valloc) strong_alias (__libc_pvalloc, __pvalloc) weak_alias (__libc_pvalloc, pvalloc) strong_alias (__libc_mallinfo, __mallinfo) weak_alias (__libc_mallinfo, mallinfo) strong_alias (__libc_mallopt, __mallopt) weak_alias (__libc_mallopt, mallopt) weak_alias (__malloc_stats, malloc_stats) weak_alias (__malloc_usable_size, malloc_usable_size) weak_alias (__malloc_trim, malloc_trim) weak_alias (__malloc_get_state, malloc_get_state) weak_alias (__malloc_set_state, malloc_set_state) #endif /* _LIBC */ /* ------------------------------------------------------------ History: [see ftp://g.oswego.edu/pub/misc/malloc.c for the history of dlmalloc] */ /* * Local variables: * c-basic-offset: 2 * End: */
标签:des style blog http color io os 使用 ar
原文地址:http://www.cnblogs.com/taek/p/3946605.html
