标签:har getch lock 使用 global 函数 src 技术 核函数
本章介绍了页锁定内存和流的使用方法,给出了测试内存拷贝、(单 / 双)流控制下的内存拷贝的例子。
测试内存拷贝
1 #include <stdio.h> 2 #include "cuda_runtime.h" 3 #include "device_launch_parameters.h" 4 #include "D:\Code\CUDA\book\common\book.h" 5 6 #define SIZE (64*1024*1024) 7 #define TEST_TIMES (100) 8 9 float cuda_malloc_test(int size, bool up) 10 { 11 cudaEvent_t start, stop; 12 int *a, *dev_a; 13 float elapsedTime; 14 15 cudaEventCreate(&start); 16 cudaEventCreate(&stop); 17 18 a = (int*)malloc(size * sizeof(int)); 19 cudaMalloc((void**)&dev_a,size * sizeof(*dev_a)); 20 21 cudaEventRecord(start, 0); 22 if (up) 23 { 24 for (int i = 0; i < TEST_TIMES; i++) 25 cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice); 26 } 27 else 28 { 29 for (int i = 0; i < TEST_TIMES; i++) 30 cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost); 31 } 32 cudaEventRecord(stop, 0); 33 cudaEventSynchronize(stop); 34 cudaEventElapsedTime(&elapsedTime, start, stop); 35 36 free(a); 37 cudaFree(dev_a); 38 cudaEventDestroy(start); 39 cudaEventDestroy(stop); 40 return elapsedTime; 41 } 42 43 float cuda_host_alloc_test(int size, bool up) 44 { 45 cudaEvent_t start, stop; 46 int *a, *dev_a; 47 float elapsedTime; 48 cudaEventCreate(&start); 49 cudaEventCreate(&stop); 50 51 cudaHostAlloc((void**)&a, size * sizeof(int), cudaHostAllocDefault); 52 cudaMalloc((void**)&dev_a, size * sizeof(int)); 53 54 cudaEventRecord(start, 0); 55 if (up) 56 { 57 for (int i = 0; i < TEST_TIMES; i++) 58 cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); 59 } 60 else 61 { 62 for (int i = 0; i < TEST_TIMES; i++) 63 cudaMemcpy(a, dev_a, size * sizeof(int), cudaMemcpyDeviceToHost); 64 } 65 cudaEventRecord(stop, 0); 66 cudaEventSynchronize(stop); 67 cudaEventElapsedTime(&elapsedTime, start, stop); 68 69 cudaFreeHost(a); 70 cudaFree(dev_a); 71 cudaEventDestroy(start); 72 cudaEventDestroy(stop); 73 return elapsedTime; 74 } 75 76 int main(void) 77 { 78 float elapsedTime; 79 float testSizeByte = (float)SIZE * sizeof(int) * TEST_TIMES / 1024 / 1024; 80 81 elapsedTime = cuda_malloc_test(SIZE, true); 82 printf("\n\tcudaMalloc Upwards:\t\t%3.1f ms\t%3.1f MB/s",elapsedTime, testSizeByte / (elapsedTime / 1000)); 83 elapsedTime = cuda_malloc_test(SIZE, false); 84 printf("\n\tcudaMalloc Downwards:\t\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / 1000)); 85 86 elapsedTime = cuda_host_alloc_test(SIZE, true); 87 printf("\n\tcudaHostAlloc Upwards:\t\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / 1000)); 88 elapsedTime = cuda_host_alloc_test(SIZE, false); 89 printf("\n\tcudaHostAlloc Downwards:\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / 1000)); 90 91 getchar(); 92 return; 93 }
? 程序输出如下图,可见也锁定内存的读取速度要比内存快一些。
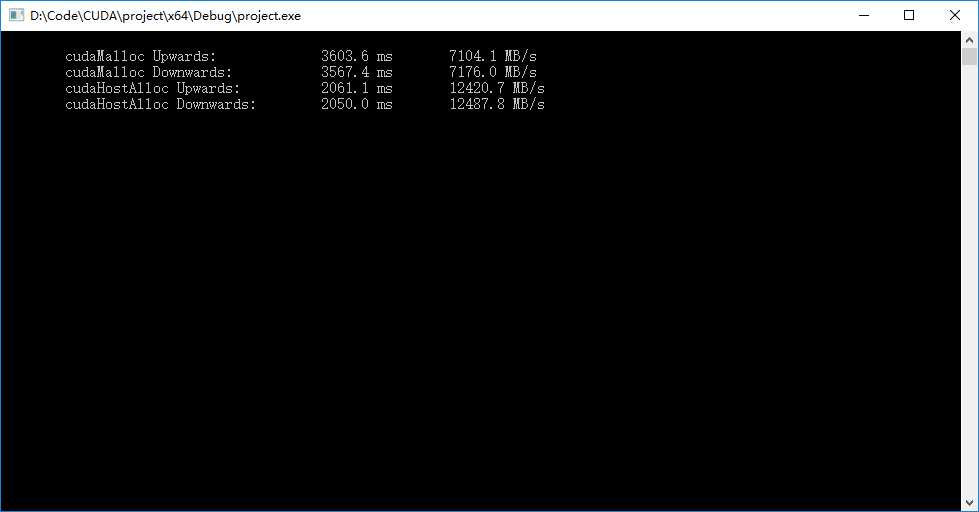
? 页锁定内存的使用方法
1 int *a, *dev_a, size; 2 3 cudaHostAlloc((void**)&a, sizeof(int) * size, cudaHostAllocDefault);// 申请页锁定内存 4 cudaMalloc((void**)&dev_a, sizeof(int) * size); 5 6 cudaMemcpy(dev_a, a, sizeof(int) * size, cudaMemcpyHostToDevice);// 使用普通的内存拷贝 7 cudaMemcpy(a, dev_a, sizeof(int) * size, cudaMemcpyDeviceToHost); 8 9 cudaFreeHost(a);// 释放内存 10 cudaFree(dev_a);
单流内存拷贝
1 #include <stdio.h> 2 #include "cuda_runtime.h" 3 #include "device_launch_parameters.h" 4 #include "D:\Code\CUDA\book\common\book.h" 5 6 #define N (1024*1024) 7 #define LOOP_TIMES (100) 8 9 __global__ void kernel(int *a, int *b, int *c) 10 { 11 int idx = threadIdx.x + blockIdx.x * blockDim.x; 12 if (idx < N) 13 { 14 int idx1 = (idx + 1) % 256; 15 int idx2 = (idx + 2) % 256; 16 float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f; 17 float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f; 18 c[idx] = (as + bs) / 2; 19 } 20 } 21 22 int main(void) 23 { 24 cudaEvent_t start, stop; 25 float elapsedTime; 26 cudaStream_t stream; 27 int *host_a, *host_b, *host_c; 28 int *dev_a, *dev_b, *dev_c; 29 30 cudaEventCreate(&start); 31 cudaEventCreate(&stop); 32 cudaStreamCreate(&stream); 33 34 cudaMalloc((void**)&dev_a, N * sizeof(int)); 35 cudaMalloc((void**)&dev_b, N * sizeof(int)); 36 cudaMalloc((void**)&dev_c, N * sizeof(int)); 37 38 cudaHostAlloc((void**)&host_a, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault); 39 cudaHostAlloc((void**)&host_b, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault); 40 cudaHostAlloc((void**)&host_c, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault); 41 42 for (int i = 0; i < N * LOOP_TIMES; i++) 43 { 44 host_a[i] = rand(); 45 host_b[i] = rand(); 46 } 47 48 cudaEventRecord(start, 0); 49 for (int i = 0; i < N * LOOP_TIMES; i += N) 50 { 51 cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream); 52 cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream); 53 54 kernel << <N / 256, 256, 0, stream >> >(dev_a, dev_b, dev_c); 55 56 cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream); 57 } 58 cudaStreamSynchronize(stream); 59 60 cudaEventRecord(stop, 0); 61 62 cudaEventSynchronize(stop); 63 cudaEventElapsedTime(&elapsedTime, start, stop); 64 printf("\n\tTest %d times, spending time:\t%3.1f ms\n", LOOP_TIMES, elapsedTime); 65 66 cudaFree(dev_a); 67 cudaFree(dev_b); 68 cudaFree(dev_c); 69 cudaFreeHost(host_a); 70 cudaFreeHost(host_b); 71 cudaFreeHost(host_c); 72 cudaStreamDestroy(stream); 73 cudaEventDestroy(start); 74 cudaEventDestroy(stop); 75 getchar(); 76 return 0; 77 }
? 程序输出
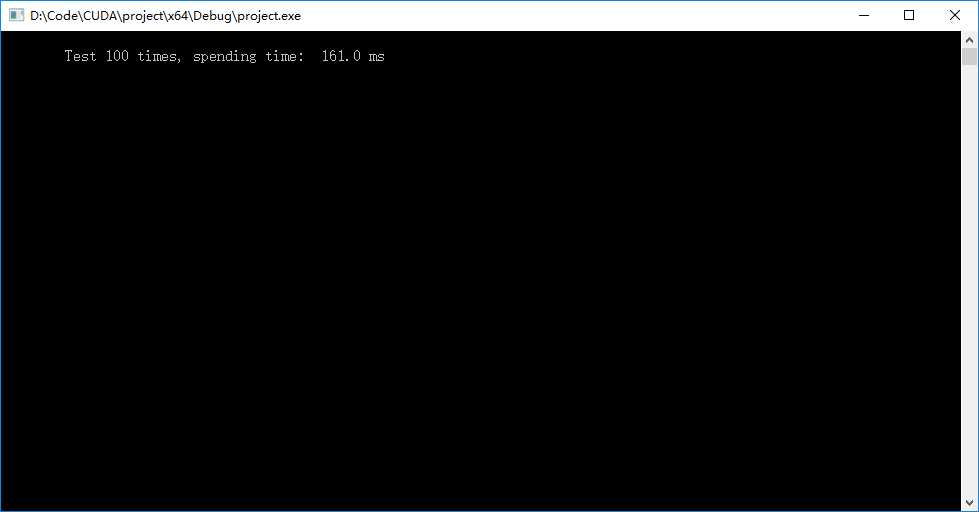
? 限定流作为内存拷贝工作时要使用函数cudaMemcpyAsync(),其简单声明和使用为:
1 cudaError_t cudaMemcpyAsync(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream __dv(0)); 2 3 cudaMemcpyAsync(dev_a, host_a, size, cudaMemcpyHostToDevice, stream); 4 cudaMemcpyAsync(host_a, dev_a, size, cudaMemcpyDeviceToHost, stream);
? 使用流的基本过程
1 cudaStream_t stream;// 创建流变量 2 int *host_a; 3 int *dev_a; 4 host_a = (int *)malloc(sizeof(int)*N); 5 cudaMalloc((void**)&dev_a, N * sizeof(int)); 6 7 cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);// 采用异步内存拷贝 8 9 kernel << <blocksize, threadsize, stream >> > (dev_a);// 执行核函数,注意标记流编号 10 11 cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream);/ 12 13 cudaStreamSynchronize(stream);// 流同步,保证该留内的工作全部完成 14 15 free(a);// 释放内存和销毁流变量 16 cudaFree(dev_a); 17 cudaStreamDestroy(stream);
双流内存拷贝
1 #include <stdio.h> 2 #include "cuda_runtime.h" 3 #include "device_launch_parameters.h" 4 #include "D:\Code\CUDA\book\common\book.h" 5 6 #define N (1024*1024) 7 #define LOOP_TIMES (100) 8 #define NAIVE true 9 10 __global__ void kernel(int *a, int *b, int *c) 11 { 12 int idx = threadIdx.x + blockIdx.x * blockDim.x; 13 if (idx < N) 14 { 15 int idx1 = (idx + 1) % 256; 16 int idx2 = (idx + 2) % 256; 17 float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f; 18 float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f; 19 c[idx] = (as + bs) / 2; 20 } 21 } 22 23 int main(void) 24 { 25 cudaEvent_t start, stop; 26 float elapsedTime; 27 cudaStream_t stream0, stream1; 28 int *host_a, *host_b, *host_c; 29 int *dev_a0, *dev_b0, *dev_c0; 30 int *dev_a1, *dev_b1, *dev_c1; 31 32 cudaEventCreate(&start); 33 cudaEventCreate(&stop); 34 35 cudaStreamCreate(&stream0); 36 cudaStreamCreate(&stream1); 37 38 cudaMalloc((void**)&dev_a0,N * sizeof(int)); 39 cudaMalloc((void**)&dev_b0,N * sizeof(int)); 40 cudaMalloc((void**)&dev_c0,N * sizeof(int)); 41 cudaMalloc((void**)&dev_a1,N * sizeof(int)); 42 cudaMalloc((void**)&dev_b1,N * sizeof(int)); 43 cudaMalloc((void**)&dev_c1,N * sizeof(int)); 44 45 cudaHostAlloc((void**)&host_a, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault); 46 cudaHostAlloc((void**)&host_b, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault); 47 cudaHostAlloc((void**)&host_c, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault); 48 49 for (int i = 0; i < N * LOOP_TIMES; i++) 50 { 51 host_a[i] = rand(); 52 host_b[i] = rand(); 53 } 54 printf("\n\tArray initialized!"); 55 56 cudaEventRecord(start, 0); 57 for (int i = 0; i < N * LOOP_TIMES; i += N * 2)// 每次吃两个N的长度 58 { 59 #if NAIVE 60 cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int),cudaMemcpyHostToDevice,stream0);// 前半段给dev_a0和dev_b0 61 cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int),cudaMemcpyHostToDevice,stream0); 62 63 kernel << <N / 256, 256, 0, stream0 >> >(dev_a0, dev_b0, dev_c0); 64 65 cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int),cudaMemcpyDeviceToHost,stream0); 66 67 cudaMemcpyAsync(dev_a1, host_a + i + N,N * sizeof(int),cudaMemcpyHostToDevice,stream1);//后半段给dev_a1和dev_b1 68 cudaMemcpyAsync(dev_b1, host_b + i + N,N * sizeof(int),cudaMemcpyHostToDevice,stream1); 69 70 kernel << <N / 256, 256, 0, stream1 >> >(dev_a1, dev_b1, dev_c1); 71 72 cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int),cudaMemcpyDeviceToHost,stream1); 73 #else 74 cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);// 两个半段拷贝任务 75 cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); 76 77 cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);// 两个半段拷贝任务 78 cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); 79 80 kernel << <N / 256, 256, 0, stream0 >> >(dev_a0, dev_b0, dev_c0);// 两个计算执行 81 kernel << <N / 256, 256, 0, stream1 >> >(dev_a1, dev_b1, dev_c1); 82 83 cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0);// 两个半段拷贝任务 84 cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1); 85 #endif 86 } 87 cudaStreamSynchronize(stream0); 88 cudaStreamSynchronize(stream1); 89 90 cudaEventRecord(stop, 0); 91 92 cudaEventSynchronize(stop); 93 cudaEventElapsedTime(&elapsedTime,start, stop); 94 printf("\n\tTest %d times, spending time:\t%3.1f ms\n", LOOP_TIMES, elapsedTime); 95 96 cudaFree(dev_a0); 97 cudaFree(dev_b0); 98 cudaFree(dev_c0); 99 cudaFree(dev_a1); 100 cudaFree(dev_b1); 101 cudaFree(dev_c1); 102 cudaFreeHost(host_a); 103 cudaFreeHost(host_b); 104 cudaFreeHost(host_c); 105 cudaStreamDestroy(stream0); 106 cudaStreamDestroy(stream1); 107 getchar(); 108 return 0; 109 }
? 书上简单双流版本输出结果如下左图,异步双流版本输出结果如下右图。发现异步以后速度范围下降了。
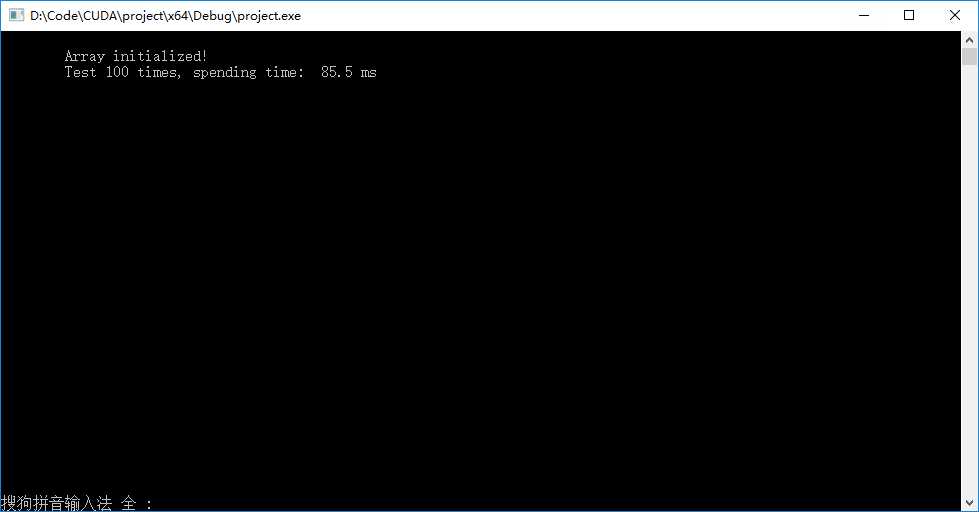
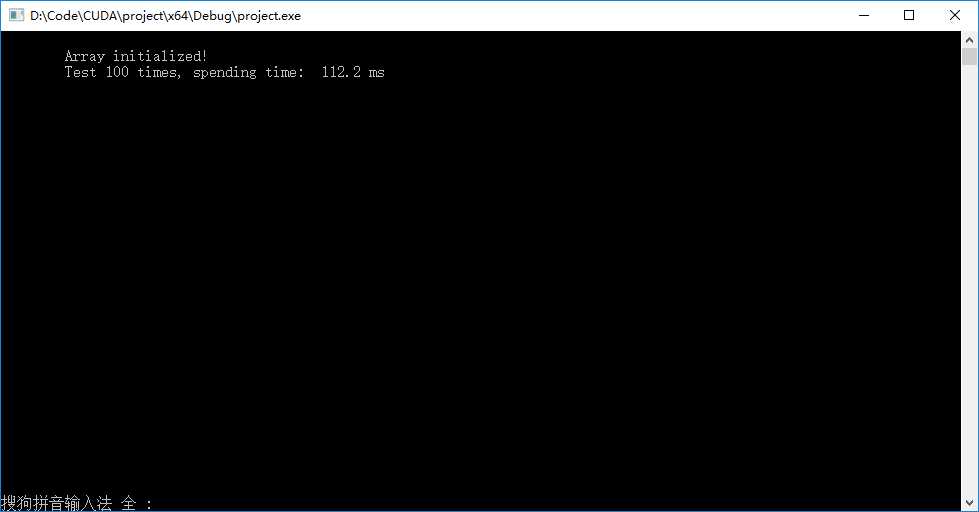
标签:har getch lock 使用 global 函数 src 技术 核函数
原文地址:http://www.cnblogs.com/cuancuancuanhao/p/7645352.html