标签:operation microsoft tar res flume rds nsf family org
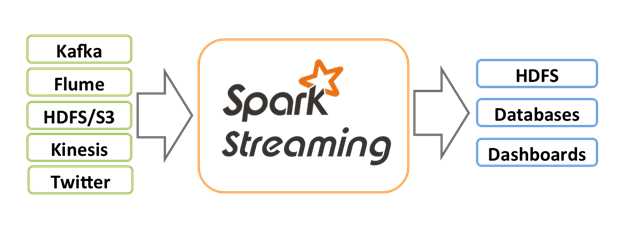
Spark Streaming 是core Spark的一个扩展,用来处理实时数据流,数据源可以来自Kafka, Flume, HDFS等,经过复杂的算法处理后,存入HDFS,数据库,或者实时的Dashboards.
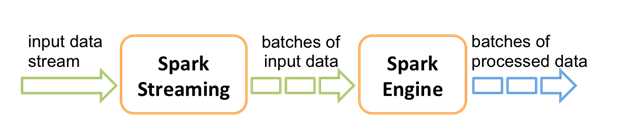
从内部来看,Spark Streaming把进来的流式数据切成一小块一小块,然后再交给Spark Engine处理,最终把无间隔的流式数据处理为有微小间隔的批次数据。由此完成了对数据流的实时处理。
接下来,介绍几个重要的概念:
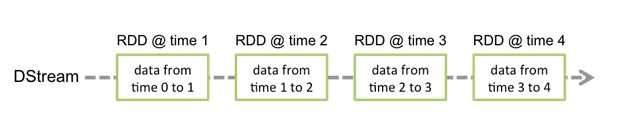
Discretized Stream(DStream):DStream是Spark Streaming的一个抽象概念,代表一段连续的数据流,它既可以是从输入端收到的数据流,也可以是经过转换处理后的数据流。从内部来看一个DStream是由一组RDD序列构成。
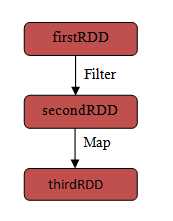
Resilient Distributed Dataset(RDD): RDD是Spark的一个数据结构,它由一组只读的,可容错的,可分布式处理的记录所构成。RDD要么通过读取外部数据来创建,要么通过转换现有的RDD来创建。RDD的操作包含Transformation(从现有的RDD生成一个新的RDD)和Action(对RDD执行运算后向Driver程序返回结果)
Input DStreams: Input DStream代表了从数据源接收到的输入数据流,Spark Streaming提供了两类数据源,一类是基础源,比如文件系统,Socket连接。另一类是高级源,比如Kafka, Flume这些。
Transformations on DStreams: 与RDD类型,我们也可以对DStream进行某些转换(Transformation), 其中常用的一些转换请参见 这里
Output Operations on DStreams: DStream的输出操作允许将DStream的数据存到外部系统中,比如数据库或者文件系统。具体的输出操作请参见 这里
总的来说,Spark Streaming就是将实时数据流分成一个个的RDD,然后对RDD进行各种操作和转换,最终将处理结果输出到外部的数据库或文件系统中。
标签:operation microsoft tar res flume rds nsf family org
原文地址:http://www.cnblogs.com/LeeZee/p/7659164.html