标签:访问量 利用 success div 时间 矩阵计算 oat eve erro
计算矩阵矩阵乘法 Am×n Bn×p == Cm×p 过程。
原始矩阵乘法,一个线程计算结果矩阵中的一个元素。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <malloc.h> 4 #include <time.h> 5 #include "cuda_runtime.h" 6 #include "device_launch_parameters.h" 7 8 #define M (1024*1+17) 9 #define N (1024*1+23) 10 #define P (1024*1+31) 11 #define SHARE_WIDTH 16 12 #define SEED 2 13 #define CEIL(x,y) (( x - 1 ) / y + 1) 14 15 void checkNULL(void *input) 16 { 17 if (input == NULL) 18 { 19 printf("\n\tfind a NULL!"); 20 exit(1); 21 } 22 return; 23 } 24 25 void checkCudaError(cudaError input) 26 { 27 if (input != cudaSuccess) 28 { 29 printf("\n\tfind a cudaError!"); 30 exit(1); 31 } 32 return; 33 } 34 35 __global__ void times(float *a, float *b, float *c, int m, int n, int p)// A(mn)×B(np)=C(np) 36 { 37 int k; 38 float temp; 39 40 for (int idy = blockIdx.y * blockDim.y + threadIdx.y; idy < M; idy += gridDim.y*blockDim.y) 41 { 42 for (int idx = blockIdx.x * blockDim.x + threadIdx.x; idx < P; idx += gridDim.x*blockDim.x) 43 { 44 for (k = 0, temp = 0.0f; k < N; k++) 45 temp += a[idy * N + k] * b[k * P + idx]; 46 c[idy * P + idx] = temp; 47 } 48 } 49 return; 50 } 51 52 int main() 53 { 54 int i, j, k, flag; 55 float *a, *b, *c, *dev_a, *dev_b, *dev_c, temp, elapsedTime; 56 clock_t time; 57 cudaEvent_t start, stop; 58 cudaEventCreate(&start); 59 cudaEventCreate(&stop); 60 61 printf("\n\tStart!"); 62 63 a = (float *)malloc(sizeof(float) * M * N); 64 b = (float *)malloc(sizeof(float) * N * P); 65 c = (float *)malloc(sizeof(float) * M * P); 66 checkNULL(a); 67 checkNULL(b); 68 checkNULL(c); 69 checkCudaError(cudaMalloc((float **)&dev_a, sizeof(float) * M * N)); 70 checkCudaError(cudaMalloc((float **)&dev_b, sizeof(float) * N * P)); 71 checkCudaError(cudaMalloc((float **)&dev_c, sizeof(float) * M * P)); 72 73 // 初始化(最费时的一步) 74 time = clock(); 75 srand(SEED); 76 for (i = 0; i < M * N; a[i] = (float)rand() / RAND_MAX, i++); 77 for (i = 0; i < N * P; b[i] = (float)rand() / RAND_MAX, i++); 78 printf("\n\tInitialized!\n\tTime:\t%6.2f ms", (float)(clock() - time)); 79 80 cudaMemcpy(dev_a, a, sizeof(float) * M * N, cudaMemcpyHostToDevice); 81 cudaMemcpy(dev_b, b, sizeof(float) * N * P, cudaMemcpyHostToDevice); 82 83 time = clock(); 84 cudaEventRecord(start, 0); 85 86 87 88 times << < dim3(128, 128), dim3(16, 16) >> > (dev_a, dev_b, dev_c, M, N, P); 89 cudaThreadSynchronize(); 90 91 cudaEventRecord(stop, 0); 92 93 time = clock() - time; 94 95 96 cudaMemcpy(c, dev_c, sizeof(float) * M * P, cudaMemcpyDeviceToHost); 97 98 99 cudaEventSynchronize(stop); 100 cudaEventElapsedTime(&elapsedTime, start, stop); 101 printf("\n\tFinished!\n\tTime by CPU:\t%6.2f ms\n\tTime by GPU:\t%6.2f ms\n\n", (float)time, elapsedTime); 102 103 // 检验结果 104 time = clock(); 105 for (i = 0, flag = 1; i < M; i++) 106 { 107 for (j = 0; j < P; j++) 108 { 109 for (k = 0, temp = 0.0f; k < N; k++) 110 temp += a[i * N + k] * b[k * P + j]; 111 if (temp != c[i * P + j]) 112 { 113 printf("\n\tCalculate error at (%6d,%6d), which c[i]==%f,temp==%f", i, j, c[i *P + j], temp); 114 flag = 0; 115 break; 116 } 117 } 118 if (flag == 0) 119 break; 120 } 121 if (flag == 1) 122 printf("\n\tCalculate correctly!"); 123 time = clock() - time; 124 printf("\n\tFinished!\n\tTime by CPU:\t%6.2f ms", (float)time); 125 126 cudaEventDestroy(start); 127 cudaEventDestroy(stop); 128 cudaFree(dev_a); 129 cudaFree(dev_b); 130 cudaFree(dev_c); 131 getchar(); 132 return 0; 133 }
? 结果输出如下图。
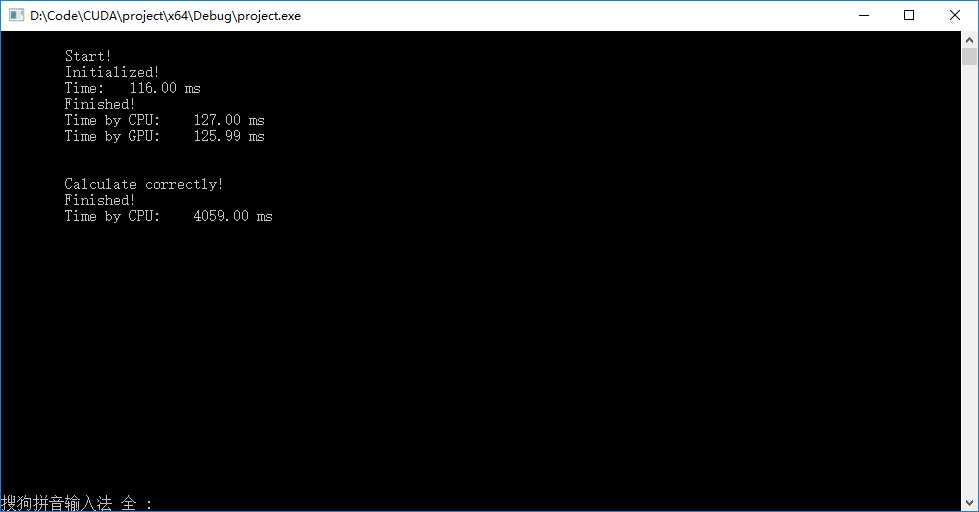
● 首先是矩阵初始化消耗的时间,在计算超大型矩阵的过程中初始化需要显著占用时间(因为矩阵元素是在CPU中逐个初始化的)。
● 其次比较了GPU运算过程的CPU和GPU计时的结果,在如上代码中(在内存拷贝前开始计时,在内存回拷完成后结束计时),两种计时方式差距在1毫秒以内,基本上认为结果相同。
● 下方为相同的矩阵乘法在CPU中的计算耗时,可见目前GPU效率约为CPU的32倍。
● 若去除内存拷贝时间,则GPU耗时可减少到100ms左右,注意此时若想利用利用CPU计时,则必须在第二次掐表以前加入 cudaThreadSynchronize(); 。因为核函数调用的同时,主机代码会继续往下执行,只到同步语句或者亟需GPU预算结果的语句才会停止,在上面的例子中,若不加入同步语句,则计时结果总是为0 ms。
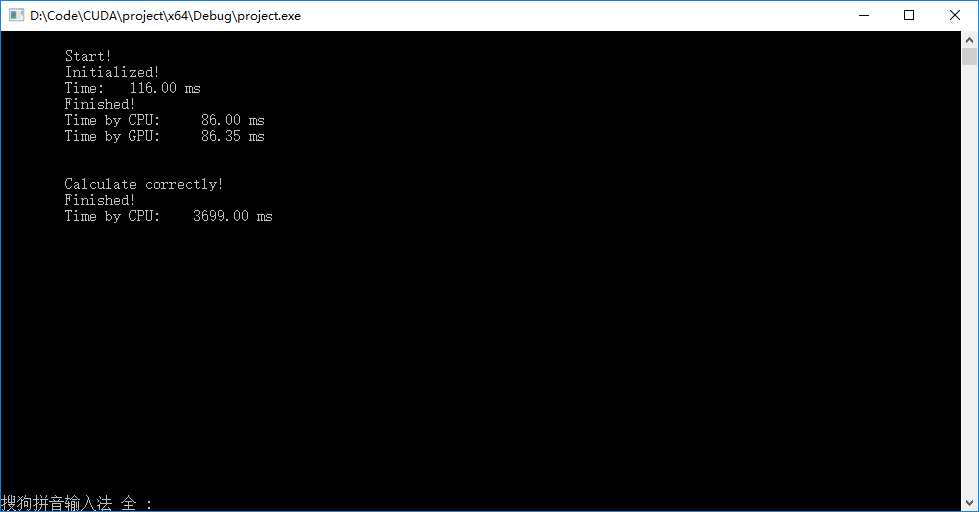
● 轻微调节粒度,将线程尺寸改为16×16,获得如下图结果,加速比可以高达42。
改进一,使用共享内存减少全局内存访问量
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <malloc.h> 4 #include <time.h> 5 #include "cuda_runtime.h" 6 #include "device_launch_parameters.h" 7 8 #define M (1024+0) 9 #define N (1024+0) 10 #define P (1024+0) 11 #define WIDTH 16 12 #define SEED (unsigned int)clock() 13 #define CEIL(x,y) (( x - 1 ) / y + 1) 14 15 void checkNULL(void *input) 16 { 17 if (input == NULL) 18 { 19 printf("\n\tfind a NULL!"); 20 exit(1); 21 } 22 return; 23 } 24 25 void checkCudaError(cudaError input) 26 { 27 if (input != cudaSuccess) 28 { 29 printf("\n\tfind a cudaError!"); 30 exit(1); 31 } 32 return; 33 } 34 35 __global__ void times(float *a, float *b, float *c)// A(mn)×B(np)=C(np) 36 { 37 __shared__ float shareA[WIDTH * WIDTH]; 38 __shared__ float shareB[WIDTH * WIDTH]; 39 40 int k, t; 41 float temp; 42 int idx = blockIdx.x * blockDim.x + threadIdx.x;// B、C中精确列号 43 int idy = blockIdx.y * blockDim.y + threadIdx.y;// A、C中精确行号 44 45 for (k = 0, temp = 0.0f; k < CEIL(N, WIDTH); k++) 46 { 47 shareA[threadIdx.y * WIDTH + threadIdx.x] = (idy * N + k * WIDTH + threadIdx.x < M * N) ? a[idy * N + k * WIDTH + threadIdx.x] : 0.0f; 48 shareB[threadIdx.x * WIDTH + threadIdx.y] = ((threadIdx.y + k * WIDTH) * P + idx < N * P) ? b[(threadIdx.y + k * WIDTH) * P + idx] : 0.0f; 49 // shareB保存为B分块的转置,方便计算时读取 50 // 原本方法 51 //shareB[threadIdx.y * WIDTH + threadIdx.x] = ((threadIdx.y + k * WIDTH) * P + idx < N * P) ? b[(threadIdx.y + k * WIDTH) * P + idx] : 0.0f; 52 53 __syncthreads(); 54 55 for (t = 0; t < WIDTH; t++) 56 temp += shareA[threadIdx.y * WIDTH + t] * shareB[threadIdx.x * WIDTH + t]; 57 // 原本方法 58 //temp += shareA[threadIdx.y * WIDTH + t] * shareB[t * WIDTH + threadIdx.x]; 59 __syncthreads(); 60 } 61 c[idy * P + idx] = temp; 62 return; 63 } 64 65 int main() 66 { 67 int i, j, k, flag; 68 float *a, *b, *c, *dev_a, *dev_b, *dev_c, temp, elapsedTime; 69 clock_t time; 70 cudaEvent_t start, stop; 71 cudaEventCreate(&start); 72 cudaEventCreate(&stop); 73 74 printf("\n\tStart!"); 75 76 a = (float *)malloc(sizeof(float) * M * N); 77 b = (float *)malloc(sizeof(float) * N * P); 78 c = (float *)malloc(sizeof(float) * M * P); 79 checkNULL(a); 80 checkNULL(b); 81 checkNULL(c); 82 checkCudaError(cudaMalloc((float **)&dev_a, sizeof(float) * M * N)); 83 checkCudaError(cudaMalloc((float **)&dev_b, sizeof(float) * N * P)); 84 checkCudaError(cudaMalloc((float **)&dev_c, sizeof(float) * M * P)); 85 86 time = clock(); 87 srand(SEED); 88 for (i = 0; i < M * N; a[i] = (float)rand() / RAND_MAX, i++); 89 for (i = 0; i < N * P; b[i] = (float)rand() / RAND_MAX, i++); 90 printf("\n\tInitialized! Time:\t%6.2f ms", (float)(clock() - time)); 91 92 time = clock(); 93 cudaEventRecord(start, 0); 94 95 cudaMemcpy(dev_a, a, sizeof(float) * M * N, cudaMemcpyHostToDevice); 96 cudaMemcpy(dev_b, b, sizeof(float) * N * P, cudaMemcpyHostToDevice); 97 98 times << < dim3(CEIL(P, WIDTH), CEIL(M, WIDTH)), dim3(WIDTH, WIDTH) >> > (dev_a, dev_b, dev_c); 99 cudaThreadSynchronize(); 100 101 cudaMemcpy(c, dev_c, sizeof(float) * M * P, cudaMemcpyDeviceToHost); 102 103 time = clock() - time; 104 cudaEventRecord(stop, 0); 105 106 cudaEventSynchronize(stop); 107 cudaEventElapsedTime(&elapsedTime, start, stop); 108 printf("\n\tFinished!\n\tTime by CPU:\t%6.2f ms\n\tTime by GPU:\t%6.2f ms\n\n", (float)time, elapsedTime); 109 110 // 检验结果 111 time = clock(); 112 for (i = 0, flag = 1; i < M; i++) 113 { 114 for (j = 0; j < P; j++) 115 { 116 for (k = 0, temp = 0.0f; k < N; k++) 117 temp += a[i * N + k] * b[k * P + j]; 118 if (temp != c[i * P + j]) 119 { 120 printf("\n\tCalculate error at (%6d,%6d), which c[i]==%f,temp==%f", i, j, c[i *P + j], temp); 121 flag = 0; 122 break; 123 } 124 } 125 if (flag == 0) 126 break; 127 } 128 if (flag == 1) 129 printf("\n\tCalculate correctly!"); 130 time = clock() - time; 131 printf("\n\tFinished!\n\tTime by CPU:\t%6.2f ms\n\tAccRatio:\t%3.1f\n\n", (float)time,time/elapsedTime); 132 133 cudaEventDestroy(start); 134 cudaEventDestroy(stop); 135 cudaFree(dev_a); 136 cudaFree(dev_b); 137 cudaFree(dev_c); 138 getchar(); 139 return 0; 140 }
? 代码有点问题,非16整数倍变长的矩阵计算可能出错,且出错位置不定,待调试。
标签:访问量 利用 success div 时间 矩阵计算 oat eve erro
原文地址:http://www.cnblogs.com/cuancuancuanhao/p/7657668.html