标签:模式 目的 基础上 logs 统计学 影响 精确 mon oda
基于二阶段聚集模式的异常探测
M.F .Jiang, S.S. Tseng *, C.M. Su
国立交通大学计算机与信息科学系,中国台北市新竹路100150号
1999年11月17日; 2000年4月25日修订
摘要
本文提出了一种进行异常探测的二阶段聚集算法。在第一段中,我们首先通过探索“如果一个新的输入样品距离簇中心的距离足够远,就将它指定为新的簇”来修改传统的k-means算法。它显示相同簇中的点似乎全部异常或者全部非异常。在第二段中我们构造了一个最小生成树,然后移除最长的边。簇越小,树中点的数量越少就会被挑选出来认定为异常。实验结果显示我们的流程是有效的。
关键词:异常值;k-means聚类;二过程聚类;最小生成树
1. 引言
异常分析可以定义为将一系列样品(或对象)分离到簇(或组)中,簇中的成员是相近的。分区或簇的目标也许是深入了解群体中的一致性(如植物或者动物的亚种分组)或者制订针对每个群体客户的业务策略,以提高业务效率。
术语“余数簇”(Cedno and Suer, 1997)的定义用于指定与其他簇有很大不同的少数样品。他们通常被认为是异常的噪声。在所有数据中,余数簇通常是小数量、各参数值与正常数据有很大的不同。因此,在传统的聚集算法中,这些样品会被忽略或给予较低的权重以避免其他数据被聚集。
然而,在某些具体应用中,我们必须从大量数据中找出异常样品。例如,在医学领域,我们也许想在病人数据中找出特殊的案例;在网络问题领域,我们也许想在日志数据中找出反常行为以预防一些反常的事故。识别异常观测值也是回归模型建立过程的一个重要方面。异常观测值应当被识别是因为他们对拟合魔性的潜在影响。这就是偶然会有观测值会对参数估计、参数估计的精确度和模型的整体预测能力产生不成比例的影响。
正如我们所知,如果我们将50各数据点分到5各簇中会有7.4×1032种可能性(Kaufman and Rousseeuw, 1990)。余数簇经常太小而不能被分类。所以使用传统的聚类算法来聚类次要和异常的样品会花费大量时间或效果不好。在实际情况下,数据集经常会有上万条记录,前一段提到的问题也许不容易通过传统聚类算法被简单地解决。
在这项工作中,异常值被定义为远离大多数点的较小簇。我们的想法是第一步将数据点分为多个不同簇,每个簇也许全是异常值或者全是非异常值。也就是说,当相同簇里的点距离不足够近,这个簇也许会被分为两个更小的簇。在数据点分类之后,可以明显看到巽宅异常簇的时间复杂度也许会降低。这是因为相似的点会被合并到相同的簇中,要处理的数据是簇而不是点。在本文中,一种进行异常探测的二相聚集算法被提出。第一阶段,我们提出首先通过探索“如果一个新的输入样品距离簇中心的距离足够远,就将它指定为新的簇”来修改k-means算法。结果显示每个簇的直径也许会缩短而且相同簇中的数据点也许更像是全为异常值或全为非异常值。但另一方面影响是,通过这种模式也许会导致获得的簇的数量比传统k-means算法获得的多。然后我们在第二阶段提出一个异常探索模式,在第一阶段的结果簇中寻找异常值。通过这个过程,这些簇的最小生成树(MST)(Zahn, 1971)首先构建并作为森林的成员处理。然后从森林中删除树的最长边,并用两个新生成的子树替换原始树。选择较小簇,具有较少节点数的树被视为异常值。此外,我们可以重复地从森林中删除最长的边缘,直到树木数量足够。
本文的结果组织如下。第2节介绍了聚类和异常值检测的相关工作。第3节给出了我们的算法的详细描述。在第4节中,我们给出了不同数据的一些实验结果,以显示我们的算法的性能。第5节给出了结论。
2. 相关工作
聚类技术在工程,医学,生物学,计算机科学等诸多领域得到了广泛的关注。聚类的目的是将彼此接近的数据点组合在一起(Tou和Gonzalez,1974)。 考夫曼和Rousseeuw(1990)将聚类称为“数据中查找组的艺术”。 由于聚类技术的成功高度依赖于调查,因此不存在最佳的聚类模式。尽管最近的研究尝试使聚类分析更具统计学意义,但仍被视为探索性工具。
不遵循与其余数据相同的模型的观察通常称为异常值。在机器学习,图像识别,聚类等许多领域中,包括异常值或噪声的实验数据可能会对结果产生不良影响。 在这个意义上,模型选择的方法与数据中不存在异常值同义。 在选择变量和异常值识别的许多方法中,一些稳定的方法已经被提出用来检测多个异常值(Hadi和Simonoff,1993:Kianifard和Swallow,1990),它们可以通过舍弃异常值来推断估计。
有多种分类方法来分类一个困难的任务。在聚类方法中,与我们的新方法相关的三种着名的算法,k-means算法,层次聚类方法和图聚类理论简要描述如下。
2.1. k-means算法
k-means聚类的过程(Forgy,1965; McQueen,1967)尽量寻找具有固定数量的簇的最优分区。首先,构建了具有选定数量的簇的初始分区(可以以许多方式完成)。然后,保持相同数量的簇,分区被迭代地改进。在本文的其余部分,假设有m个样品要聚类。每个样品被顺序处理并重新分配给簇,从而通过重新分配最大程度地提高分配标准。通常当不能获得改进的再分配时,程序结束,但也可以使用更强的结束测试。
令样品M的集合为{x1,x2,...,xm},xi∈Rn,xi是第i个样品。让目标簇的数量为k。迭代聚类算法(Forgy,1965)如下:
步骤1:选择一个拥有k个簇的初始分区。
步骤2:通过将每个样品分配给其最近的簇(以簇中心来计算距离)来生成新的分区。
步骤3:计算新的簇中心。
步骤4:重复步骤2和步骤3直到找到标准函数的最佳值。
步骤5:调整群集数量,或通过合并和拆分现有群集或删除离群群集。
在步骤2中定义了一种将所有样品分配给最近的簇中心的k-means方法,步骤3是更新分区的过程。许多确定初始分区的方法由Hyvarinen(1963),Forgy(1965),McQueen(1967),Bakk和Hall(1964)等提出。此外,还有两种以k-means方式更新分区的方法。 在McQueen的k-means方法中,在每次新的分配之后重新计算获取簇的中心。Forgy的方法在所有样品被检查之后重新计算集群的中心。我们的聚类方法是通过在分配,分割或合并操作之后调整中心来修改McQueen的方法。对于不适当的初始分区,一些修改的算法,例如ISODATA(Ball和Hall,1964)可以在满足某些条件时创建新的簇或合并现有的簇。如果簇具有太多的样品,则会将簇分裂,如果两个簇中心足够接近,则会将簇合并。
Johnson 和Wichern (1982)指出,欧几里德距离是在多变量模式中寻找群体时最广泛接受和常用的相似度度量。基于毕达哥拉斯定理的欧氏距离是模式差异的平方和的平方根。假定样本x1=(x11,x12,...,x1p)和x2=(x21,x22,...,x2p),其中xij代表第i个样品第i个变量的值。x1与x2间的欧几里得距离d表示为d(x1,x2)=√[(x11-x21)2+(x12-x22)2+···+(x1p-x2p)2]。欧几里得距离之所以流行是因为其作为相似度量的直观性。也就是说,类似的观测值应该相隔较小的距离,而不同的观测值应该相隔较远的距离。
2.2. 分层聚类方法
分层算法来自m个簇的初始分区(每个样品被看作是一个簇),然后逐个减少一个簇的数量,直到所有m个观察值都在单个簇中(Dubes和Jain,1987)。各种聚类技术之间的区别是合并簇的规则。单链接聚类合并基于每个簇中两个最近的观测值的距离(“相似性度量”)。因此,单链接通常被称为“最近邻”算法。关于单链接聚类算法和其他聚类算法的更多细节,参考Johnson和Wichern(1982)。
单一链接聚类算法的结果可以在图中看到,或者通常称为“簇树”。具体来说,簇树必须在一定高度被分割或“切割”。群体的数量取决于树被切割的位置。“群体数量”问题是任何聚类程序用户必须处理的现实问题。分层聚类模型,通常使用单链接测量来聚集点,提供了一个确定组数n量的方法。在层次聚类模型中,单链接基于每个簇中两个最接近的观察点之间的距离来合并簇,聚类结果可以看作是“簇树”。之后添加的簇可以被视为异常值或余数簇。然而,它不适合大量的数据,因为使用现代方法的单链接的计算成本对于CPU时间是O(n2),对于存储器空间是O(n),对于n个模式被聚集( Dubes and Jain,1987)反之亦然。
2.3. 图聚类理论
一个簇是在簇分析中有许多应用的数学结构。可以将图形定义为一组顶点和边。顶点集V={vi}通常代表被聚类的对象。边集E={ej}记录一对顶点之间的相互作用。在本工作中,我们考虑到图是树T=(V,E)时的具体情况。树的聚类问题出现在各种应用中。树用于表示分层数据库,许多通信或分布网络呈现树状结构。在树的情况下,可行分区可以如下表示。如果从树上任意“切”p-1个边,得到p个分离子树T1,...,Tp。如果Ck是Tk((1,...,p)的顶点,则π={C1,...,Cp}是V到p簇的可行分区。事实上,通过对它们进行切割,可以得到相对于π的p-1个外边缘,以获得π。
通过对实际使用的几乎所有目标函数的动态规划,可以在多项式时间内解决树上的聚类问题。一般图中的聚类问题往往是NP完整的; 事实证明,树的情况是边界和计算复杂度受目标函数的影响。
3. 二阶段聚集模式
在数据往往非常大的数据挖掘应用中,例如1000万条记录或更多,一个重要的因素是所需的计算资源(CPU时间和存储空间)。资源消耗在不同方法之间变化很大,一些方法对于除小数据集之外的其他数据集都变得不切实际,而k均值算法通常具有n阶的时空复杂度,其中n是数据集中的记录数。在本节中,提出了一种用于异常值的两阶段聚类算法。在第一阶段,以粗略的方式对簇进行k-means算法修改,从而允许簇的数量超过原始k,其中k是包括由用户设置的异常值的所需要的簇数。 在第一阶段,k-means算法被修改为以粗略的方式聚集大量数据,允许簇的数量超过原始k,其中k是包括由用户设置的异常值的所需求的簇数。在修改的k-means算法中,我们使用启发式的“如果一个新的输入样品远离所有集群的中心,然后将其分配为新的簇中心”。这导致每个簇的直径会缩短,并且同一簇中的数据点彼此更接近。通过这种方法,同一集群中的数据点可能都是异常值或都是非异常值,但副作用是在该阶段发现的簇数大于原始k均值算法中发现的簇数。在第二阶段为了找到异常值,根据边的距离构建MST,其中树的每个节点代表在阶段1中获得的每个簇的中心。然后删除最长边,原来的树被两个新生成的子树替换。选择小簇即节点数少的树被视为异常值。此外,我们可以重复地去除最长的边缘,直到簇的数量足够多,并且生成的簇不像传统的k-均值算法那样很多被平均划分。我们的聚类方法的算法被划分为两个阶段,修改后的k均值过程(MKP相)和OFP阶段,在以下部分描述。
3.1. 修改后的K-means过程(MKP)
由于不同的初始数据集可能会产生不同的聚类结果,所以使用k-means算法不能很容易地获得所需的最优结果。特别是在大量的模式中,通过尝试所有不同的初始集来找到全局最优情况是不切实际的。我们修改后的k-means算法使用了一个启发式的“如果一个新的输入样品远离所有的簇中心,然后把它分配为一个新的簇中心”,它将异常值在集群交互过程中分离成另一个集群中心。允许这个启发式搜索调整集群的数量。类似于ISODATA算法,添加更多的集群将有助于我们找出不显眼的潜在异常值或余数簇。
一开始,我们的聚类方法就像传统的k-means算法。令k‘为可调整簇的数量。最初设置k‘= k,随机选择k‘个样品作为聚类中心,C = {z1,z2,...,zk‘}属于Rn。在迭代期间,当向最近的集群添加一个模式时,我们不仅计算新集群的中心,而且还计算任何两个集群中心之间的最小距离min(C)。
min(C)=min||zj-zh||2 其中j,h=1,...,k‘, j≠h.
对于任何模式xi,其最近的簇的中心的最小距离min(xi,C)计算如下
min(xi,C)=min||xi-zj||2 其中j,h=1,...,k‘.
根据上述启发法,分割数据后可以找到更多的簇。在某些极端情况下,每个样品被放入自己的簇中,即k‘= m,其中m是所有点的数量。在某些极端情况下,每个模式被放入自己的簇,即k‘= m,其中m是所有点的数量,这将导致产生太多的簇。在修改的k-means算法中,当模式被分解为kmax+1个簇时,两个最接近的簇将被合并。修改的k-means算法如下:
算法3.1 (修改后的k-means过程,MKP)。
第1步:随机选择k‘个初始点作为簇中心。
第2步:对于i←1到m,计算min(C)和min(xi,C)。
第3步:如果min(xi,C)≤min(C)则跳到第6步。
第4步:分割过程:将xi指定为新集群Ck‘的中心,并设置k‘←k‘+ 1。
第5步:合并过程:如果k‘>kmax,将两个最近的簇合并为一个簇,并设置k‘=kmax。
第6步:分配过程:将xi分配给其最接近的簇。
第7步:跳到第2步直到簇成员稳定。
在第2步中,计算“样品与最近簇之间的距离”与“现有簇之间的最小距离”,在步骤3中,启发法“如果一个样品足够远,则将其分配为新的簇” 用于确定应将哪一个拆分或合并。重要的是要注意,这里使用的分割和合并操作与ISODATA算法中提出的分割和合并操作非常相似。然而,与ISODATA算法不同,它设置用户参数,以确定当集群有太多样品或两个集群的中心足够接近时合并。当用户既不知道属性也不知道模式的散布时,这是不合适的。在我们的分割方案中,是依据当时的条件而执行,并且当产生太多的簇时,执行合并。在聚类之前不必彻底了解数据的分布。kmax的值范围从k到m,由领域专家确定。如果数据点是随机的,我们建议将kmax的值设置在m附近。
(a)合并过程
合并的过程是整合两个现有的簇。将zk1和zk2设置为用于合并的两个最近的簇的中心。然后,通过以下操作合并这两个簇:
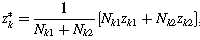
zk*是新簇的中心,Nk1和Nk2是两个簇分别包含样品的数量。显然Zk1和Zk2被zk*替代,同事k‘的值减一。
(b)分配过程
对于每个聚类迭代,我们将所有样品分配给最近的簇,使得每个样品与相应簇的中心之间的欧几里德距离的平方和最小化。总标准可以描述为最小化: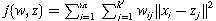 受制于
受制于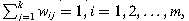 其中wij=1,如果对于所有i = 1,2,...,m,j = 1,2,...,k或wij = 0,则将样品i分配给集群j。
其中wij=1,如果对于所有i = 1,2,...,m,j = 1,2,...,k或wij = 0,则将样品i分配给集群j。
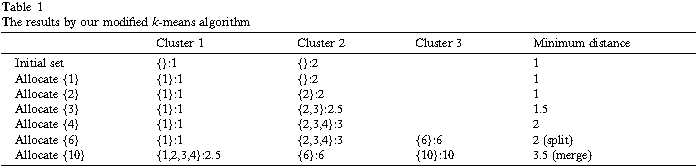
例1:令样本{1,2,3,4,6,10},我们修改的的k-means算法结果展示在表1中。
由于k-means和异常值检测算法的相对性能可能很好地随着k的范围而变化,所以将标准函数定义为:(1/ARAC),其中ARAC(群集之间的平均关系)是与其他集群的一个集群的关系标准类似于Davies-Bouldin指数(Davies and Bouldin, 1979)。当ARAC变小时,标准函数将会绝对增长。通过比较不同簇号的标准值,可以找出最优簇数。
3.2. 异常值查找过程(OFP)
虽然大多数集群技术使用密度作为标准来确定聚类的结果是否好,但我们的方法似乎没有必要将大型簇拆分成几个分区来降低密度。与分层技术的标准类似,我们方法的标准是用依据距离找到异常值数据。因此,在阶段2中,在阶段1中获得的k‘个集群的中心将被看作是基于每两个节点之间的距离来构造MST的k‘个节点。我们构造MST而不是层次化的原因是构建MST的时间复杂度是O(n2),而层次结构是O(n3)(Jain and Dubes, 1988)。
在第2阶段,我们提出一个OFP,从第一阶段得到的聚类中找出异常值。在步骤1中,我们首先为这些簇构建MST,并将其设置为树林F的成员。然后在步骤2中,从森林中删除树的最长边,并用两个新获得的子树替换树。选择小簇,具有较少节点数的树被视为异常值。此外,我们可以重复从森林中删除最长边,直到F中的树数等于k。
让进程的输入为中心集C={z1,z2,...,zk‘}属于Rn,并假定空树集合F被初始化。OFP如下所示:
算法3.2 (异常值查找过程,OFP)。
第1步:通过集合C的中心构造MST并将其添加到F.
第2步:从F中移除树的最长边,并将树替换为新生成的两个子树。
第3步:将小子树中的簇视为异常值。
4. 实验
在本节中,三组不同的实验数据用来我们的新方法和传统聚类算法进行测试和比较。在第一个实验中,我们使用150个鸢尾花二维数据。在第二个实验中,四维甘蔗育种数据集被测试。最后,我们在网络行为检测中应用我们的方法。所有的实验结果显示我们的异常检测方法通常工作的比传统k-means算法更好。
4.1. 两个属性的鸢尾花数据
该实验的第一部分涉及的是著名的鸢尾花数据(Duda and Hart,1973)。这里有鸢尾植株数据库中的三组鸢尾花数据:山鸢尾、变色鸢尾和维吉尼亚鸢尾。众所周知鸢尾花数据有一些可以被现、以前的方法消除的噪声。在本次实验中,我们选取第1和第2个属性作为输入参数。图1(a)和(b)分别展示了k=3和k=4的k-means算法的结果;图1(a‘)和(b‘)分别展示了我们的聚类方法k=3和k=4时的结果。
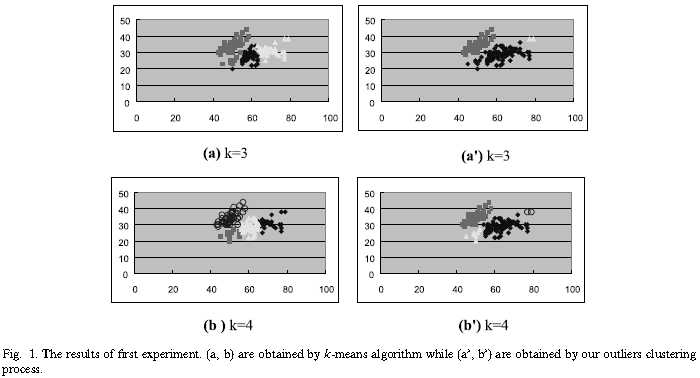
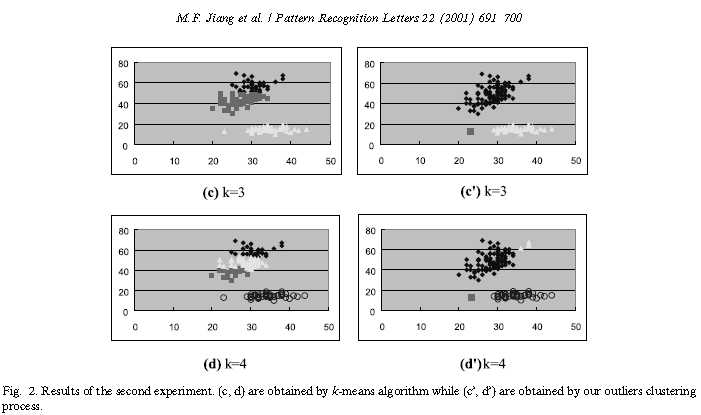
在实验的第二部分,我们选择鸢尾花的第2和第3个属性作为输入参数。相似地,图2(c)和(d)分别是k=3和k=4的k-means算法获得的,图2(c‘)和(d‘)分别是通过我们的k=3和k=4的离群聚类获得的。依据这个结果,可以清晰地看到k-means算法集群模式是平衡的方式,而我们的集群过程不会将大型簇分成几个子簇。相反,我们的方法可以将分布在边缘的少量样品聚类以达到聚类异常值的目标。
4.2 甘蔗育种数据
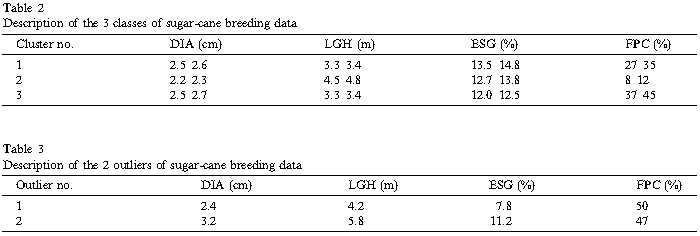
为了了解异常值搜寻算法的能力,1990年台湾糖研究所(TSRI)发布的甘蔗育种数据库(Jiang et al., 1996)被用来实验。每个数据记录包含名字和23个甘蔗属性包括茎直径、茎长等。在本实验中,使用了171条记录和4个特征即茎直径(DIA)、茎长(LGH)、增强糖(ESG)和花百分比(FPC)。k=5的聚类结果展示在表2和表3中,产生了3个簇,检测到两个离群。
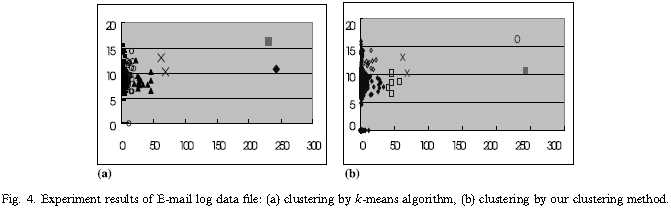
4.3 电子邮件日志数据
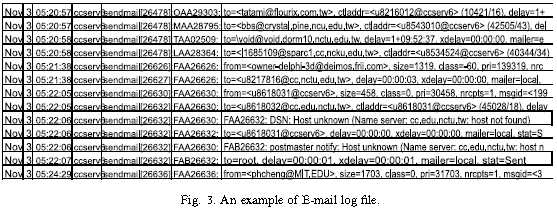
垃圾邮件通常一位置在短时间内大量邮件被发送到邮件服务器,将会增加邮件服务器的工作量同事使整个系统瘫痪。因此我们建立了一个在线异常电子邮件行为监控系统,它可以在邮件服务器上工作同时分析邮件服务器收到的每封邮件。据我们所知,当用户通过电子邮件服务器发送电子邮件时,服务器会记录一些相对于用户行为的信息。在将信息从日志文件中提取到关系数据库之前,我们必须首先清理并转换原始数据。原始日志文件记录包括以下信息:时间、来源和目的地地址、邮件大小、流程优先级和用户信息等。图3展示了一个例子。
我们实验的电子邮件数据记录有25511条,被分为6个簇。在网络管理员的经验基础上,我们使用了两个变量即电子邮件记录(X坐标),每封电子邮件大小(日志字节,Y坐标)作为我们的实验参数。图4是聚类实验结果,我们可以发现k-means算法只能将这些相当大的正常样品分成几个子集群,但不区分异常值样品。图4(b)展示了我们的聚类方法可以聚类更多异常样品。
5. 结语
在传统的聚类算法中,异常样品被忽视或被并入其他大量样品中。然而,在一些特殊领域,我们需要从大量的数据中找出这些异常样品。在本文中,我们提出一个异常识别二阶段聚类方法。第一阶段,我们基友一个“分裂”启发法修改k-means算法;第二阶段,我们提出一个OFP用来在第一阶段获得的结果簇中寻找异常值。在本阶段中,一个MST被建立同事最长边被移除。然后将原始树用两个新生成的子树替换。小簇即节点很少的树会被选择和看作异常。此外,我们会迭代移除最长边直到森林中树的数量足够多。依据第一个实验:鸢尾花数据,结果显示我们提出的方法可以找出次要和异常的样品。在电子邮件日志文件算法实验中,我们提出的聚类算法被应用于在线监控异常电子邮件行为系统。结果显示我们的方法效果较好。
致谢
这项工作得到了中国教育部和国家科学部下第89-E-FA04-1-4号“高信度信息系统”的支持。
参考文献
略。
Two-phase clustering process for outliers detection 文章翻译
标签:模式 目的 基础上 logs 统计学 影响 精确 mon oda
原文地址:http://www.cnblogs.com/wintertone/p/7641109.html