标签:success 解决 pen 分享 check 处理 min __sync free
展示了三种不同的GPU一维卷积方法,分别为简单(全局内存)卷积,含光环元素的共享内存方法,不含光环元素的共享内存方法。并且改进了CPU的一维卷积方案(不需要分边界情况单独处理)。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <windows.h> 4 #include <time.h> 5 #include <math.h> 6 #include "cuda_runtime.h" 7 #include "device_launch_parameters.h" 8 9 #define ARRAY_SIZE (1024*73+27) 10 #define MASK_SIZE 7 //奇数 11 #define WIDTH 64 12 #define SEED 1 //(unsigned int)clock() 13 #define MIN(x,y) ((x)<(y)?(x):(y)) 14 #define CEIL(x,y) (int)(( x - 1 ) / y + 1) 15 16 typedef int format; // int or float 17 18 __constant__ format d_mask[MASK_SIZE]; 19 20 void checkCudaError(cudaError input) 21 { 22 if (input != cudaSuccess) 23 { 24 printf("\n\tfind a cudaError!"); 25 exit(1); 26 } 27 return; 28 } 29 30 int checkResult(format * in1, format * in2, const int length) 31 { 32 for (int i = 0; i < length; i++) 33 { 34 if (in1[i] != in2[i]) 35 return i; 36 } 37 return 0; 38 } 39 40 void convolutionCPU(const format *in, const format *mask, format *out, const int array_size, const int mask_size) 41 { 42 for (int i = 0; i < array_size; i++)// 外层循环针对数组元素 43 { 44 out[i] = 0; 45 for (int j = -MIN(mask_size / 2, i); j <= MIN(mask_size / 2, array_size - 1 - i); j++)// 魔改的判断条件,不需要分边界情况讨论 46 out[i] += in[i + j] * mask[mask_size / 2 + j]; 47 } 48 return; 49 } 50 51 __global__ void convolutionGPU1(const format *in, format *out, const int array_size, const int mask_size) 52 { 53 int id = blockIdx.x * blockDim.x + threadIdx.x; 54 if (id < array_size) 55 { 56 format sum = 0; 57 for (int j = 0; j < mask_size; j++)// 循环针对蒙版元素 58 sum += (id - mask_size / 2 + j >= 0 && id - mask_size / 2 + j < array_size) ? in[id - mask_size / 2 + j] * d_mask[j] : 0; 59 out[id] = sum; 60 } 61 return; 62 } 63 64 __global__ void convolutionGPU2(const format *in, format *out, const int array_size, const int mask_size) 65 { 66 extern __shared__ format share_in[];// 指定共享内存包括两端的光环元素 67 int id = blockIdx.x * blockDim.x + threadIdx.x; 68 if (id < array_size) 69 { 70 format sum = 0; 71 72 // 用前 mask_size / 2 个线程来填充前 mask_size / 2 个光环元素,保证顺序相同,提高全局内存访问效率 73 if (threadIdx.x <mask_size / 2) 74 share_in[threadIdx.x] = (id - mask_size / 2 >= 0) ? in[id - mask_size / 2] : 0; 75 76 share_in[mask_size / 2 + threadIdx.x] = in[blockIdx.x * blockDim.x + threadIdx.x];//中间部分下标用 mask_size / 2 垫起 77 78 // 用后 mask_size / 2 个线程来填充后 mask_size / 2 个光环元素 79 if (threadIdx.x >= blockDim.x - mask_size / 2) 80 share_in[mask_size / 2 + blockDim.x + threadIdx.x] = (id + mask_size / 2 < array_size) ? in[id + mask_size / 2] : 0; 81 __syncthreads(); 82 83 for (int j = 0; j < mask_size; j++)// 卷积,循环针对蒙版元素 84 sum += share_in[threadIdx.x + j] * d_mask[j]; 85 out[id] = sum; 86 } 87 return; 88 } 89 90 __global__ void convolutionGPU3(const format *in, format *out, const int array_size, const int mask_size) 91 { 92 extern __shared__ format share_in[];// 指定共享内存不包括两端的光环元素 93 int id = blockIdx.x * blockDim.x + threadIdx.x; 94 if (id < array_size) 95 { 96 int in_j, j;// in_j 为本线程中涉及卷积的原数组的第j个元素的下标 97 format sum = 0; 98 99 share_in[threadIdx.x] = in[id]; 100 __syncthreads(); 101 102 for (j = 0; j < mask_size; j++) 103 { 104 in_j = id - mask_size / 2 + j; 105 if (in_j >= 0 && in_j < array_size) 106 sum += (in_j >= blockIdx.x*blockDim.x && in_j < (blockIdx.x + 1)*blockDim.x) ? 107 share_in[threadIdx.x + j - mask_size / 2] * d_mask[j] : sum += in[in_j] * d_mask[j]; 108 } 109 } 110 return; 111 } 112 113 int main() 114 { 115 int i; 116 format h_in[ARRAY_SIZE], h_mask[MASK_SIZE], cpu_out[ARRAY_SIZE],gpu_out[ARRAY_SIZE]; 117 format *d_in, *d_out; 118 clock_t time; 119 cudaEvent_t start, stop; 120 float elapsedTime1, elapsedTime2, elapsedTime3; 121 cudaEventCreate(&start); 122 cudaEventCreate(&stop); 123 124 checkCudaError(cudaMalloc((void **)&d_in, sizeof(format) * ARRAY_SIZE)); 125 checkCudaError(cudaMalloc((void **)&d_mask, sizeof(format) * MASK_SIZE)); 126 checkCudaError(cudaMalloc((void **)&d_out, sizeof(format) * ARRAY_SIZE)); 127 128 srand(SEED); 129 for (i = 0; i < ARRAY_SIZE; i++) 130 h_in[i] = 1 + 0 * (rand() - RAND_MAX / 2); 131 for (i = 0; i < MASK_SIZE; i++) 132 h_mask[i] = 1; 133 134 time = clock(); 135 convolutionCPU(h_in, h_mask, cpu_out, ARRAY_SIZE, MASK_SIZE); 136 time = clock() - time; 137 138 cudaMemcpy(d_in, h_in, sizeof(format) * ARRAY_SIZE, cudaMemcpyHostToDevice); 139 cudaMemcpyToSymbol(d_mask, h_mask, sizeof(format) * MASK_SIZE); 140 141 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 142 cudaEventRecord(start, 0); 143 convolutionGPU1 << < CEIL(ARRAY_SIZE, WIDTH), WIDTH >> > (d_in, d_out, ARRAY_SIZE, MASK_SIZE); 144 cudaMemcpy(gpu_out, d_out, sizeof(format) * ARRAY_SIZE, cudaMemcpyDeviceToHost); 145 cudaDeviceSynchronize(); 146 cudaEventRecord(stop, 0); 147 cudaEventSynchronize(stop); 148 cudaEventElapsedTime(&elapsedTime1, start, stop); 149 if (i = checkResult(cpu_out, gpu_out, ARRAY_SIZE)) 150 printf("\n\tCompute error at i = %d\n\tcpu_out[i] = %10d, gpu_out[i] = %10d\n", i, cpu_out[i], gpu_out[i]); 151 else 152 printf("\n\tGPU1 Compute correctly!\n"); 153 154 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 155 cudaEventRecord(start, 0); 156 convolutionGPU2 << < CEIL(ARRAY_SIZE, WIDTH), WIDTH, sizeof(format) * (WIDTH + MASK_SIZE - 1) >> > (d_in, d_out, ARRAY_SIZE, MASK_SIZE); 157 cudaMemcpy(gpu_out, d_out, sizeof(format) * ARRAY_SIZE, cudaMemcpyDeviceToHost); 158 cudaDeviceSynchronize(); 159 cudaEventRecord(stop, 0); 160 cudaEventSynchronize(stop); 161 cudaEventElapsedTime(&elapsedTime2, start, stop); 162 if (i = checkResult(cpu_out, gpu_out, ARRAY_SIZE)) 163 printf("\n\tCompute error at i = %d\n\tcpu_out[i] = %10d, gpu_out[i] = %10d\n", i, cpu_out[i], gpu_out[i]); 164 else 165 printf("\n\tGPU2 Compute correctly!\n"); 166 167 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 168 cudaEventRecord(start, 0); 169 convolutionGPU3 << < CEIL(ARRAY_SIZE, WIDTH), WIDTH, sizeof(format) * WIDTH >> > (d_in, d_out, ARRAY_SIZE, MASK_SIZE); 170 cudaMemcpy(gpu_out, d_out, sizeof(format) * ARRAY_SIZE, cudaMemcpyDeviceToHost); 171 cudaDeviceSynchronize(); 172 cudaEventRecord(stop, 0); 173 cudaEventSynchronize(stop); 174 cudaEventElapsedTime(&elapsedTime3, start, stop); 175 if (i = checkResult(cpu_out, gpu_out, ARRAY_SIZE)) 176 printf("\n\tCompute error at i = %d\n\tcpu_out[i] = %10d, gpu_out[i] = %10d\n", i, cpu_out[i], gpu_out[i]); 177 else 178 printf("\n\tGPU3 Compute correctly!\n"); 179 180 printf("\n\tSpending time:\n\tCPU:\t%10ld ms\ 181 \n\tGPU1:\t%10.2f ms\n\tGPU2:\t%10.2f ms\n\tGPU3:\t%10.2f ms\n", 182 time, elapsedTime1, elapsedTime2, elapsedTime3); 183 184 cudaFree(d_in); 185 cudaFree(d_mask); 186 cudaFree(d_out); 187 cudaEventDestroy(start); 188 cudaEventDestroy(stop); 189 getchar(); 190 return 0; 191 }
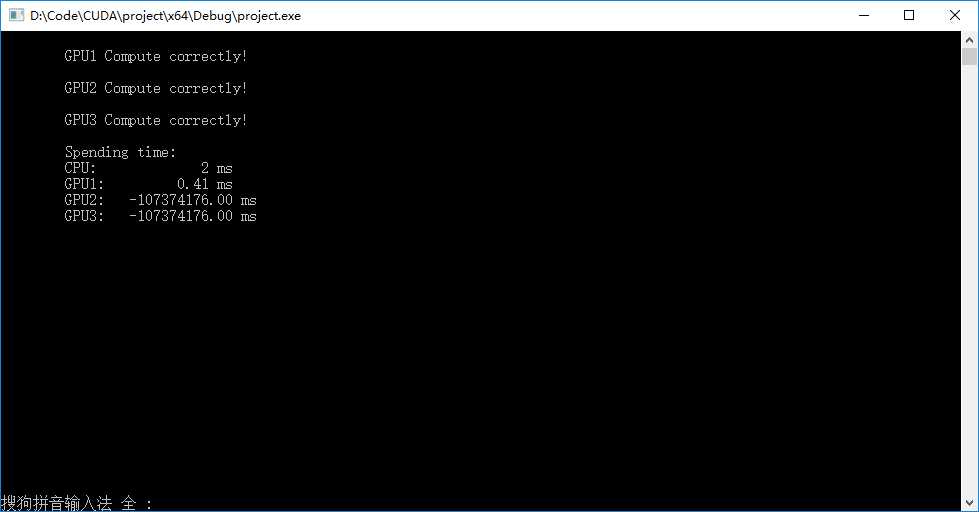
? 输出结果如下图,计时部分有点问题(如何使用同一个 cudaEvent _t start, stop 对多个事件进行计时?),三种方法计算结果均正确,等待及时问题解决再来对比测评。
标签:success 解决 pen 分享 check 处理 min __sync free
原文地址:http://www.cnblogs.com/cuancuancuanhao/p/7667440.html