标签:抓包 取数据 模拟 执行 span 加载 sele html网页 开发者
有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得。
这说明我们想要的元素是在我们的某些操作下通过js事件动态生成的。举个例子,我们在刷QQ空间或者微博评论的时候,一直往下刷,网页越来越长,内容越来越多,就是这个让人又爱又恨的动态加载。
爬取动态页面目前来说有两种方法
分析请求页面
通过Selenium模拟浏览器获取
小编不推荐使用方法二,原因很简单,效率低,爬取少量页面数据可以接受,如果我们获取的页面层次多数据量大,那么它的执行效率会死人的。。。。
分析很简单,我们只需要打开了浏览器F12开发者模式,获取它的js请求文件(除JS选项卡还有可能在XHR选项卡中,当然也可以通过其它抓包工具)
我们打开第一财经网看看,发现无法获取元素的内容
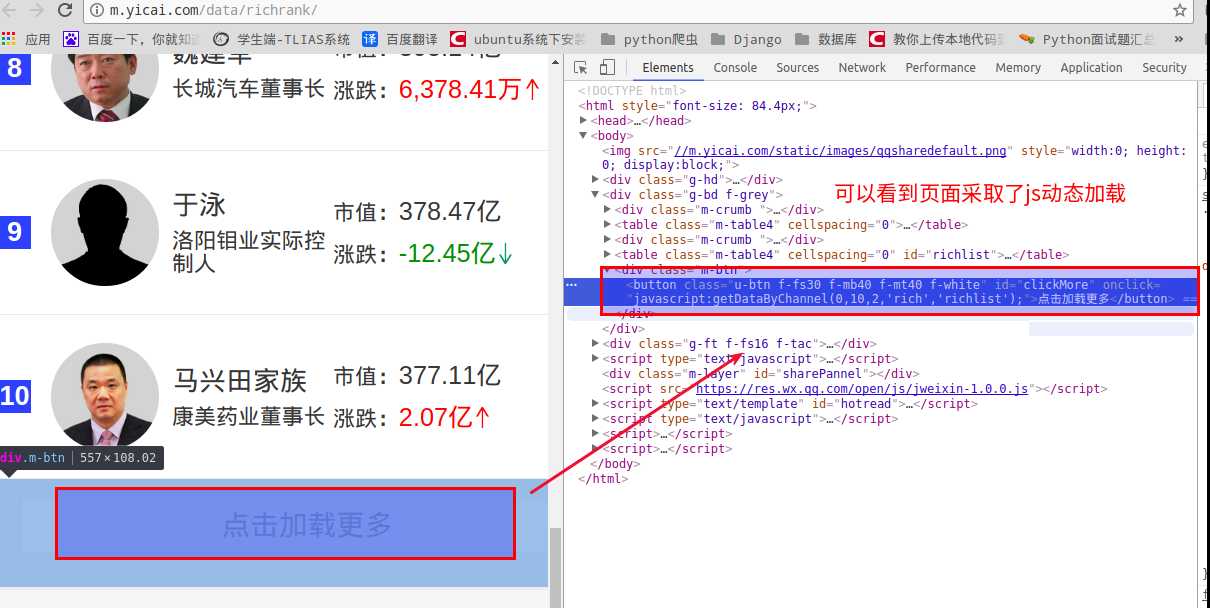
打开Network,看下它的请求,这里我们只看它的js请求就够了
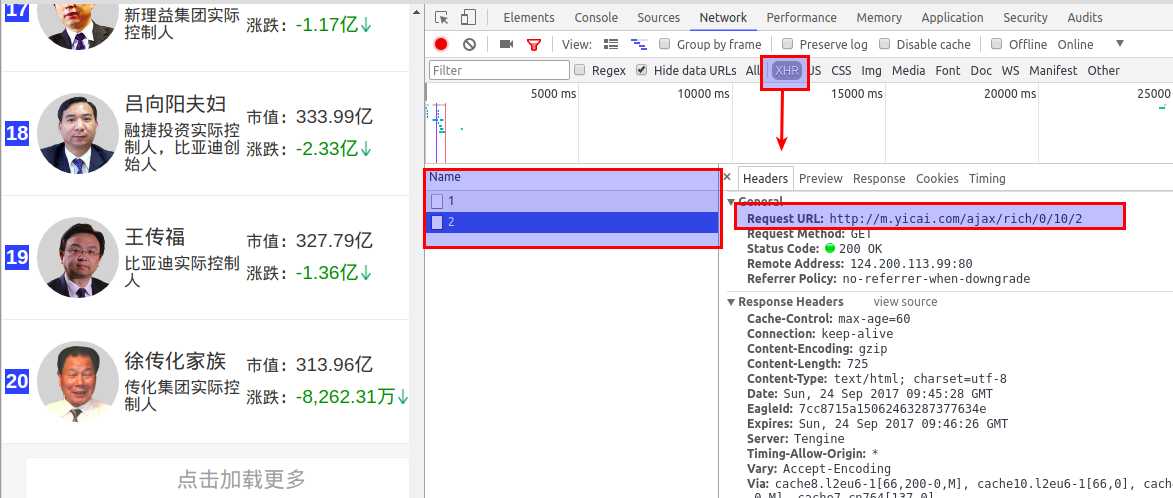
将它的url放到浏览器看下
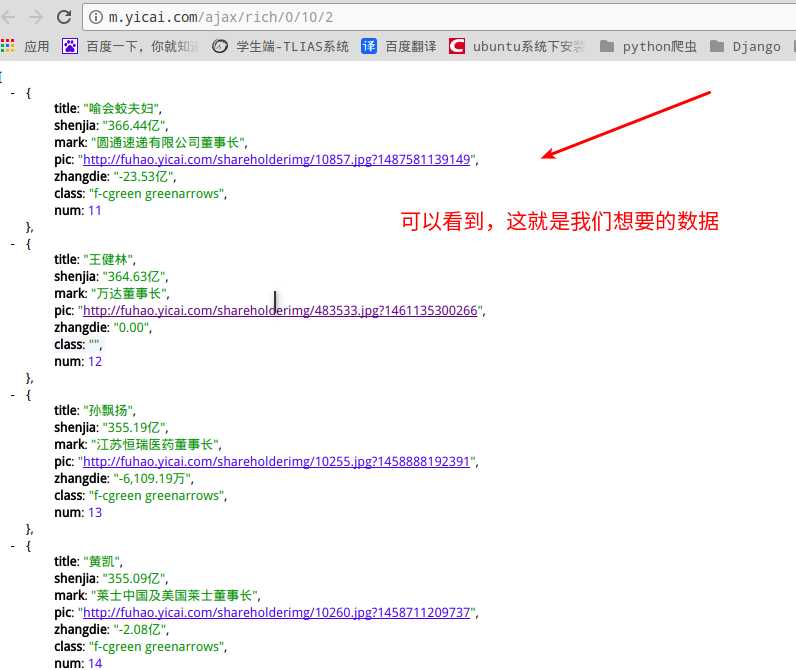
我们观察url的规律可以看到每次末尾的url都自增1,这样我们就可以重构请求来获取数据,贴下代码
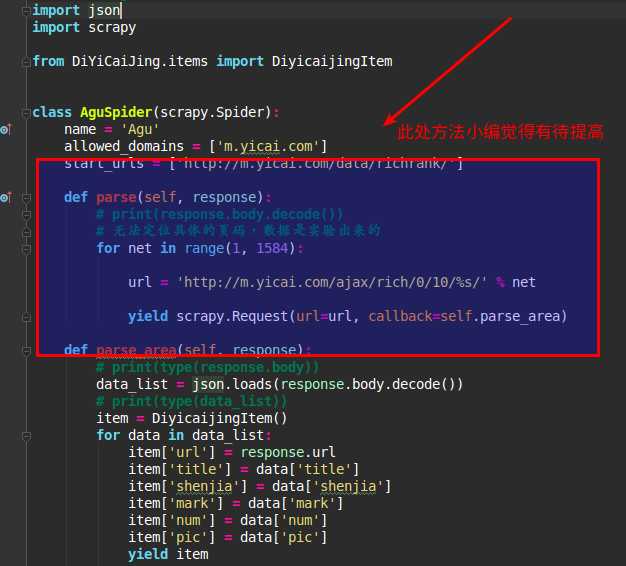
这里的数值1584是小编手动试出来的,还有一种方法就是直接while循环,在判断返回值,如果还有更好的方法,请告知下小编
有时候,一些网站所有的接口都进行了加密操作,我们无法解析js,就必须采用selenium+phantomjs进行获取,具体使用请看另一篇。
标签:抓包 取数据 模拟 执行 span 加载 sele html网页 开发者
原文地址:http://www.cnblogs.com/syketw23/p/7667622.html